 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Learning of Qualitative Constraint Networks from Membership Queries
Sep 23, 2021
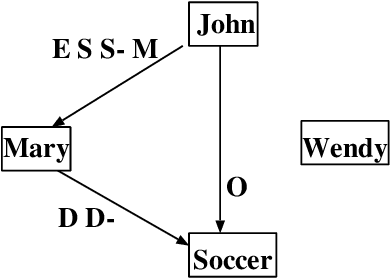

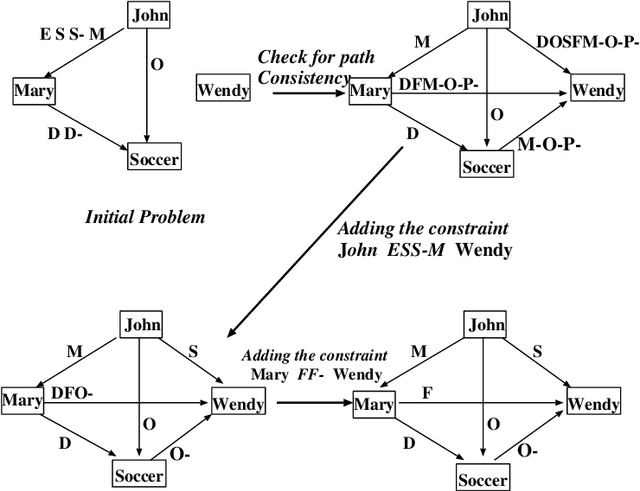
A Qualitative Constraint Network (QCN) is a constraint graph for representing problems under qualitative temporal and spatial relations, among others. More formally, a QCN includes a set of entities, and a list of qualitative constraints defining the possible scenarios between these entities. These latter constraints are expressed as disjunctions of binary relations capturing the (incomplete) knowledge between the involved entities. QCNs are very effective in representing a wide variety of real-world applications, including scheduling and planning, configuration and Geographic Information Systems (GIS). It is however challenging to elicit, from the user, the QCN representing a given problem. To overcome this difficulty in practice, we propose a new algorithm for learning, through membership queries, a QCN from a non expert. In this paper, membership queries are asked in order to elicit temporal or spatial relationships between pairs of temporal or spatial entities. In order to improve the time performance of our learning algorithm in practice, constraint propagation, through transitive closure, as well as ordering heuristics, are enforced. The goal here is to reduce the number of membership queries needed to reach the target QCN. In order to assess the practical effect of constraint propagation and ordering heuristics, we conducted several experiments on randomly generated temporal and spatial constraint network instances. The results of the experiments are very encouraging and promising.
Eating Garlic Prevents COVID-19 Infection: Detecting Misinformation on the Arabic Content of Twitter
Jan 09, 2021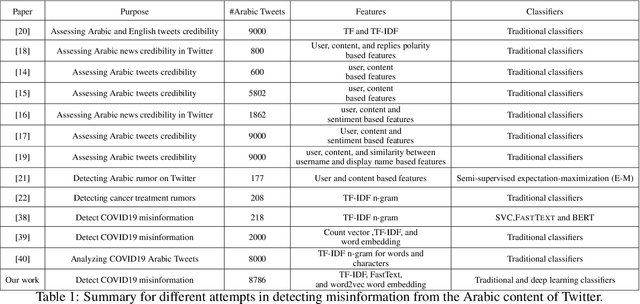
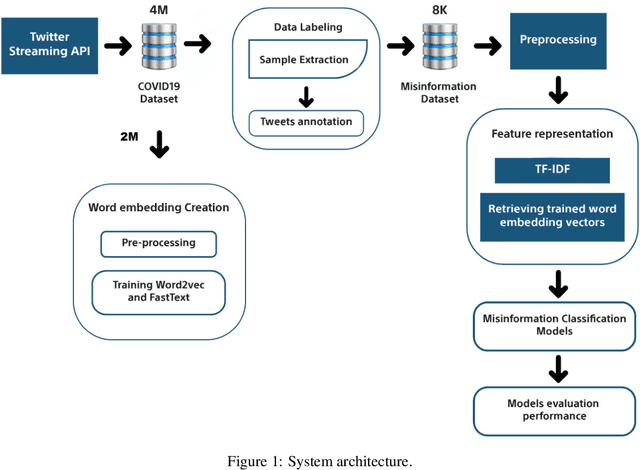
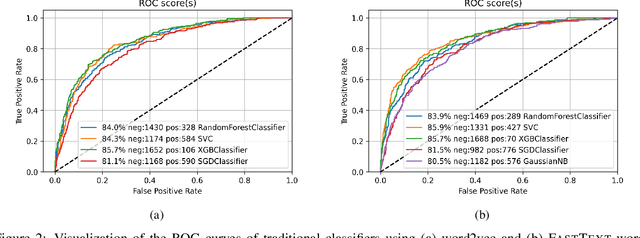
The rapid growth of social media content during the current pandemic provides useful tools for disseminating information which has also become a root for misinformation. Therefore, there is an urgent need for fact-checking and effective techniques for detecting misinformation in social media. In this work, we study the misinformation in the Arabic content of Twitter. We construct a large Arabic dataset related to COVID-19 misinformation and gold-annotate the tweets into two categories: misinformation or not. Then, we apply eight different traditional and deep machine learning models, with different features including word embeddings and word frequency. The word embedding models (\textsc{FastText} and word2vec) exploit more than two million Arabic tweets related to COVID-19. Experiments show that optimizing the area under the curve (AUC) improves the models' performance and the Extreme Gradient Boosting (XGBoost) presents the highest accuracy in detecting COVID-19 misinformation online.
Applying Machine Learning Techniques for Caching in Edge Networks: A Comprehensive Survey
Jun 21, 2020
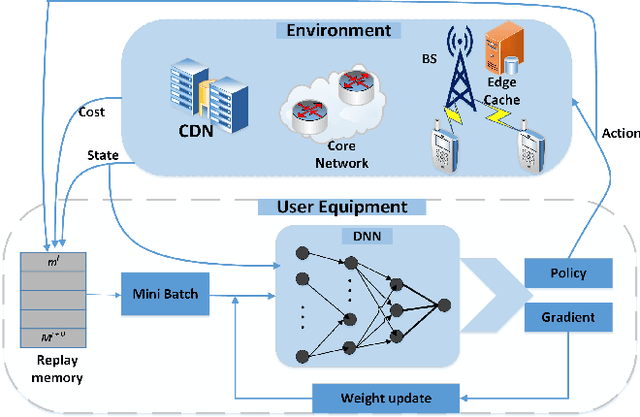
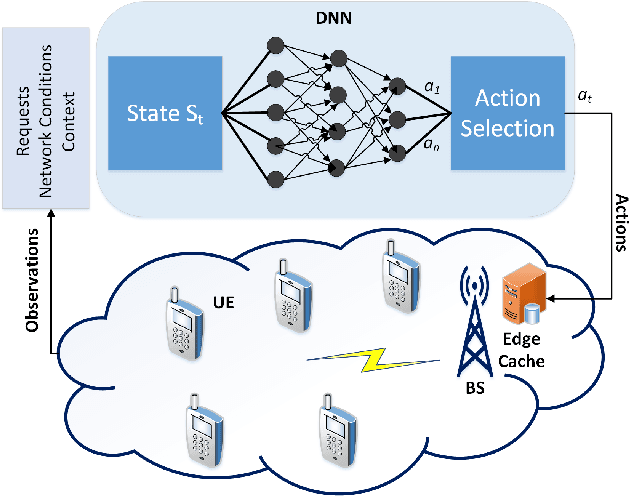
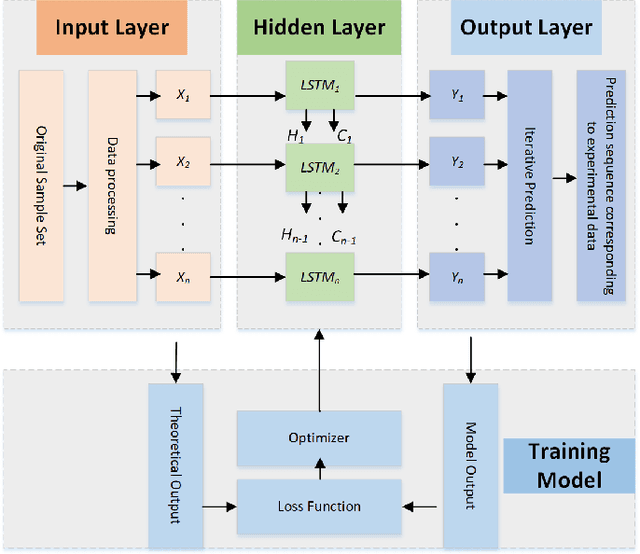
Edge networks provide access to a group of proximate users who may have similar content interests. Caching popular content at the edge networks leads to lower latencies while reducing the load on backhaul and core networks with the emergence of high-speed 5G networks. User mobility, preferences, and content popularity are the dominant dynamic features of the edge networks. Temporal and social features of content, such as the number of views and likes are applied to estimate the popularity of content from a global perspective. However, such estimates may not be mapped to an edge network with particular social and geographic characteristics. In edge networks, machine learning techniques can be applied to predict content popularity based on user preferences, user mobility based on user location history, cluster users based on similar content interests, and optimize cache placement strategies provided a set of constraints and predictions about the state of the network. These applications of machine learning can help identify relevant content for an edge network to lower latencies and increase cache hits. This article surveys the application of machine learning techniques for caching content in edge networks. We survey recent state-of-the-art literature and formulate a comprehensive taxonomy based on (a) machine learning technique, (b) caching strategy, and edge network. We further survey supporting concepts for optimal edge caching decisions that require the application of machine learning. These supporting concepts are social-awareness, popularity prediction, and community detection in edge networks. A comparative analysis of the state-of-the-art literature is presented with respect to the parameters identified in the taxonomy. Moreover, we debate research challenges and future directions for optimal caching decisions and the application of machine learning towards caching in edge networks.
Large Arabic Twitter Dataset on COVID-19
Apr 22, 2020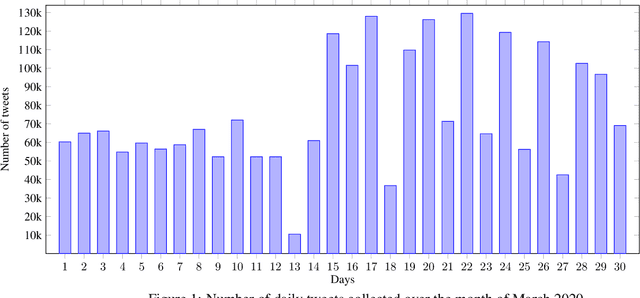
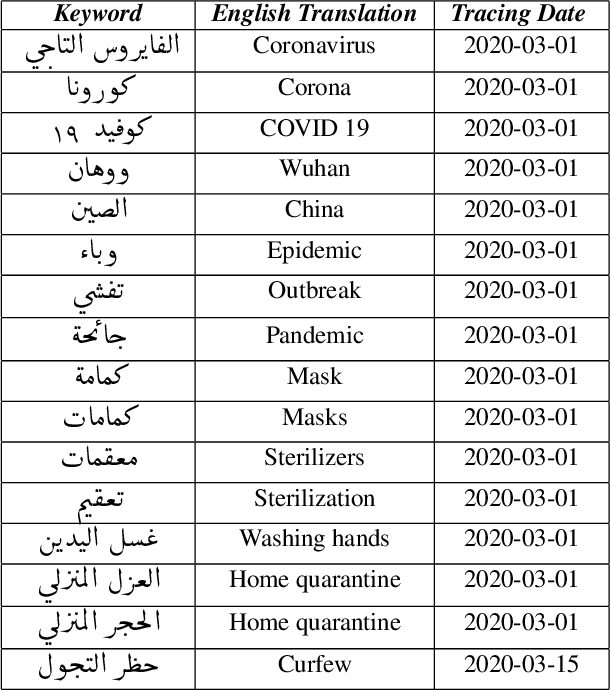
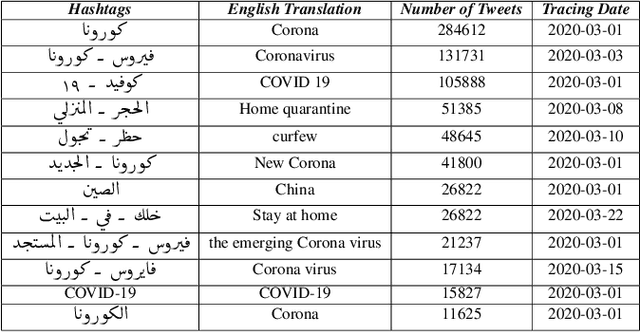
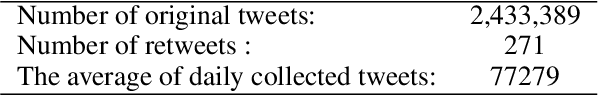
The 2019 coronavirus disease (COVID-19), emerged late December 2019 in China, is now rapidly spreading across the globe. At the time of writing this paper, the number of global confirmed cases has passed two millions and half with over 180,000 fatalities. Many countries have enforced strict social distancing policies to contain the spread of the virus. This have changed the daily life of tens of millions of people, and urged people to turn their discussions online, e.g., via online social media sites like Twitter. In this work, we describe the first Arabic tweets dataset on COVID-19 that we have been collecting since January 1st, 2020. The dataset would help researchers and policy makers in studying different societal issues related to the pandemic. Many other tasks related to behavioral change, information sharing, misinformation and rumors spreading can also be analyzed.
Preference-based Multiobjective Virtual Machine Placement: A Ceteris Paribus Approach
Apr 20, 2019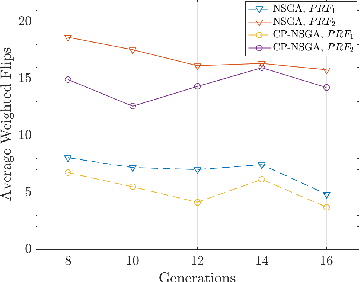
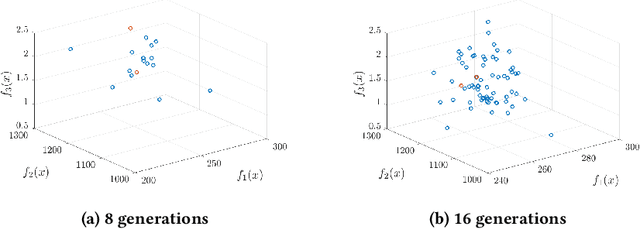
This work adopts the notion of Ceteris Paribus (CP) as an interpretation of the Decision Maker (DM) preferences and incorporates it in a constrained multiobjective problem known as virtual machine placement (VMP). VMP is an essential multiobjective problem in the design and operation of cloud data centers concerned about placing each virtual machine to a physical machine (a server) in the data center. We analyze the effectiveness of CP interpretation on VMP problems and propose an NSGA-II variant with which preferred solutions are returned at almost no extra time cost.
The Complexity of Learning Acyclic Conditional Preference Networks
Aug 25, 2018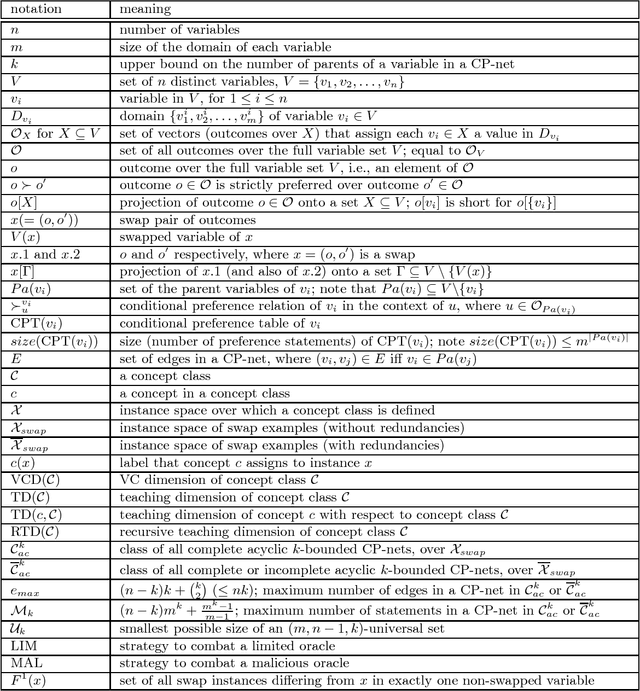
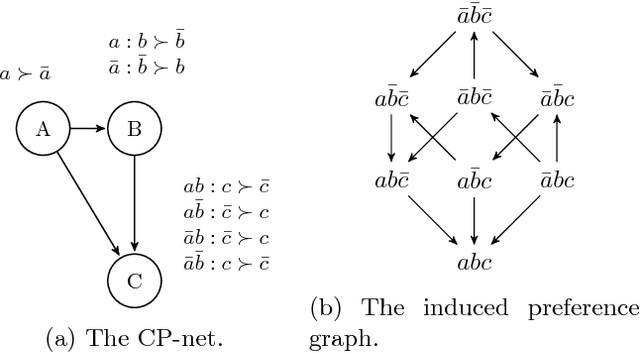
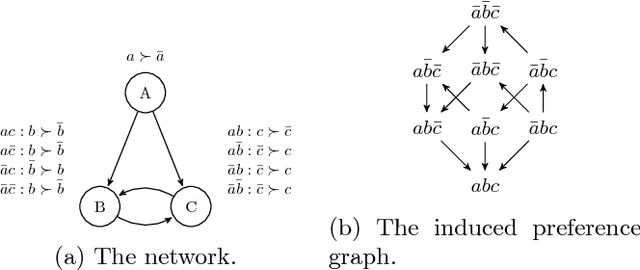
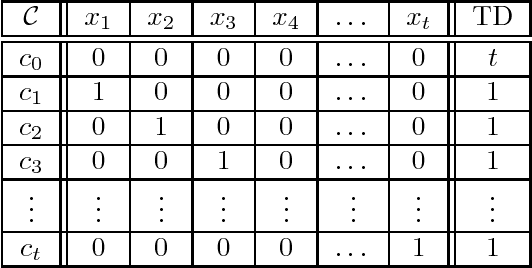
Learning of user preferences, as represented by, for example, Conditional Preference Networks (CP-nets), has become a core issue in AI research. Recent studies investigate learning of CP-nets from randomly chosen examples or from membership and equivalence queries. To assess the optimality of learning algorithms as well as to better understand the combinatorial structure of classes of CP-nets, it is helpful to calculate certain learning-theoretic information complexity parameters. This article focuses on the frequently studied case of learning from so-called swap examples, which express preferences among objects that differ in only one attribute. It presents bounds on or exact values of some well-studied information complexity parameters, namely the VC dimension, the teaching dimension, and the recursive teaching dimension, for classes of acyclic CP-nets. We further provide algorithms that learn tree-structured and general acyclic CP-nets from membership queries. Using our results on complexity parameters, we assess the optimality of our algorithms as well as that of another query learning algorithm for acyclic CP-nets presented in the literature. Our algorithms are near-optimal, and can, under certain assumptions, be adapted to the case when the membership oracle is faulty.