 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the CLEF--2021 CheckThat! Lab on Detecting Check-Worthy Claims, Previously Fact-Checked Claims, and Fake News
Sep 23, 2021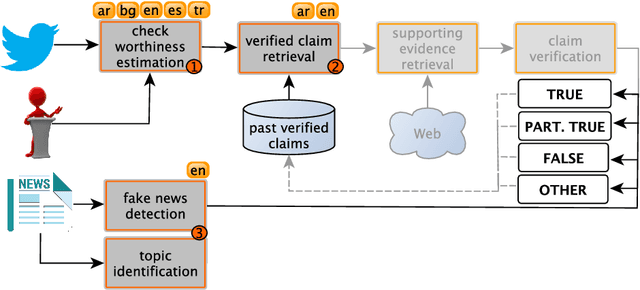
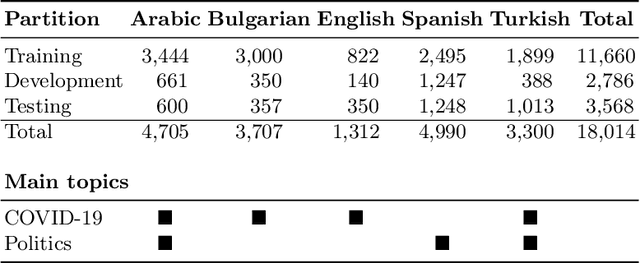
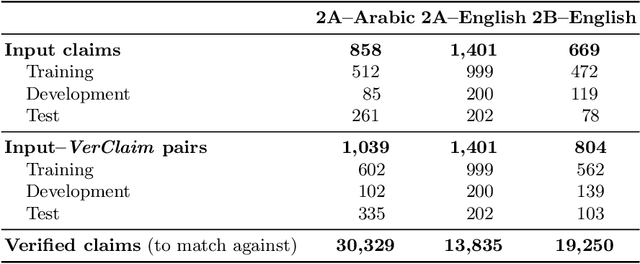
We describe the fourth edition of the CheckThat! Lab, part of the 2021 Conference and Labs of the Evaluation Forum (CLEF). The lab evaluates technology supporting tasks related to factuality, and covers Arabic, Bulgarian, English, Spanish, and Turkish. Task 1 asks to predict which posts in a Twitter stream are worth fact-checking, focusing on COVID-19 and politics (in all five languages). Task 2 asks to determine whether a claim in a tweet can be verified using a set of previously fact-checked claims (in Arabic and English). Task 3 asks to predict the veracity of a news article and its topical domain (in English). The evaluation is based on mean average precision or precision at rank k for the ranking tasks, and macro-F1 for the classification tasks. This was the most popular CLEF-2021 lab in terms of team registrations: 132 teams. Nearly one-third of them participated: 15, 5, and 25 teams submitted official runs for tasks 1, 2, and 3, respectively.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
Overview of CheckThat! 2020: Automatic Identification and Verification of Claims in Social Media
Jul 15, 2020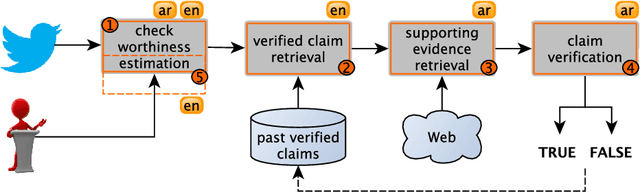
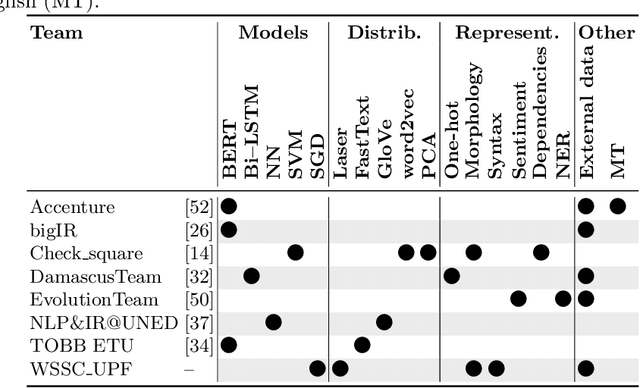
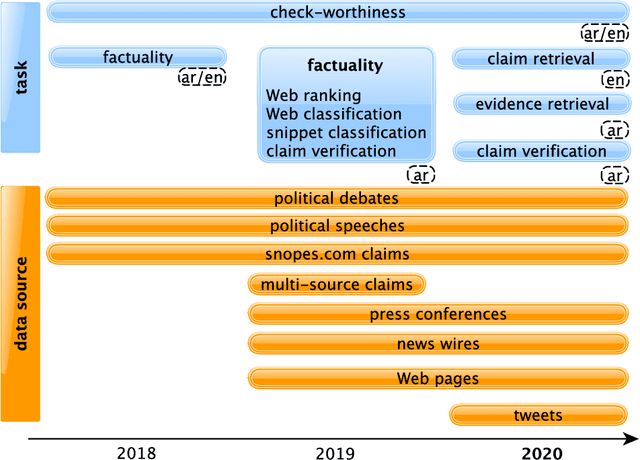
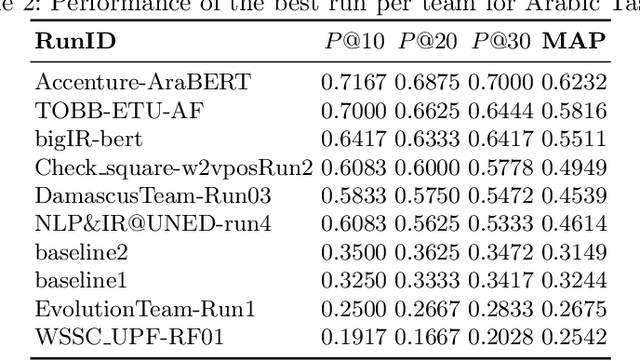
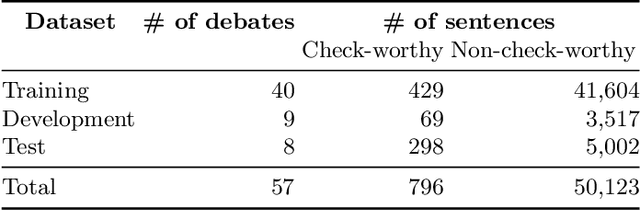
We present an overview of the third edition of the CheckThat! Lab at CLEF 2020. The lab featured five tasks in two different languages: English and Arabic. The first four tasks compose the full pipeline of claim verification in social media: Task 1 on check-worthiness estimation, Task 2 on retrieving previously fact-checked claims, Task 3 on evidence retrieval, and Task 4 on claim verification. The lab is completed with Task 5 on check-worthiness estimation in political debates and speeches. A total of 67 teams registered to participate in the lab (up from 47 at CLEF 2019), and 23 of them actually submitted runs (compared to 14 at CLEF 2019). Most teams used deep neural networks based on BERT, LSTMs, or CNNs, and achieved sizable improvements over the baselines on all tasks. Here we describe the tasks setup, the evaluation results, and a summary of the approaches used by the participants, and we discuss some lessons learned. Last but not least, we release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
That is a Known Lie: Detecting Previously Fact-Checked Claims
May 12, 2020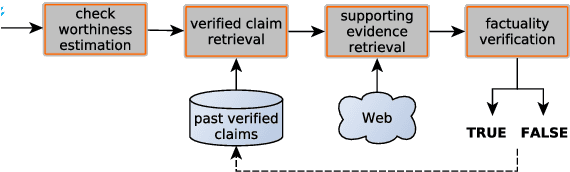



The recent proliferation of "fake news" has triggered a number of responses, most notably the emergence of several manual fact-checking initiatives. As a result and over time, a large number of fact-checked claims have been accumulated, which increases the likelihood that a new claim in social media or a new statement by a politician might have already been fact-checked by some trusted fact-checking organization, as viral claims often come back after a while in social media, and politicians like to repeat their favorite statements, true or false, over and over again. As manual fact-checking is very time-consuming (and fully automatic fact-checking has credibility issues), it is important to try to save this effort and to avoid wasting time on claims that have already been fact-checked. Interestingly, despite the importance of the task, it has been largely ignored by the research community so far. Here, we aim to bridge this gap. In particular, we formulate the task and we discuss how it relates to, but also differs from, previous work. We further create a specialized dataset, which we release to the research community. Finally, we present learning-to-rank experiments that demonstrate sizable improvements over state-of-the-art retrieval and textual similarity approaches.
* detecting previously fact-checked claims, fact-checking, disinformation, fake news, social media, political debates