Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Language Adaptation for Cross-Lingual Stance Detection
Paper and Code
Oct 04, 2019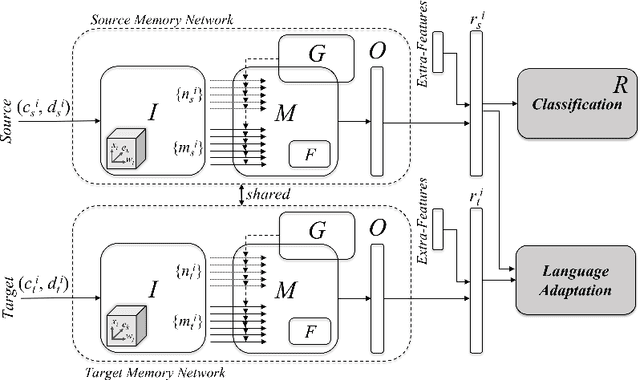

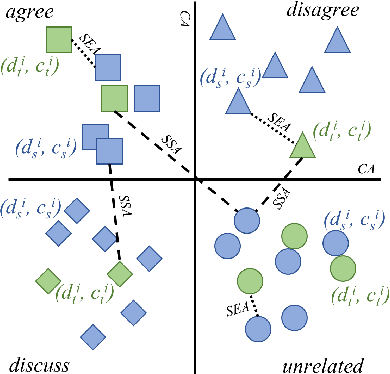
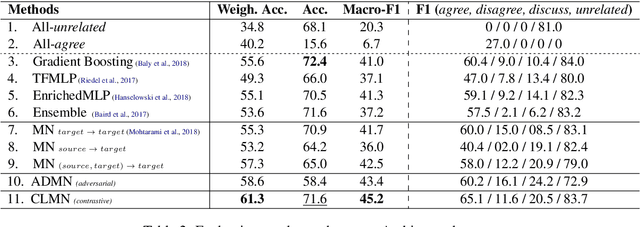
We study cross-lingual stance detection, which aims to leverage labeled data in one language to identify the relative perspective (or stance) of a given document with respect to a claim in a different target language. In particular, we introduce a novel contrastive language adaptation approach applied to memory networks, which ensures accurate alignment of stances in the source and target languages, and can effectively deal with the challenge of limited labeled data in the target language. The evaluation results on public benchmark datasets and comparison against current state-of-the-art approaches demonstrate the effectiveness of our approach.
* EMNLP-2019
View paper on