 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Factuality of Reporting of News Media Using Observations About User Attention in Their YouTube Channels
Aug 27, 2021

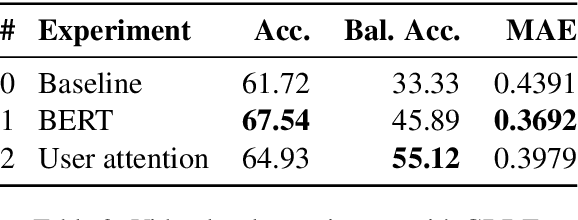
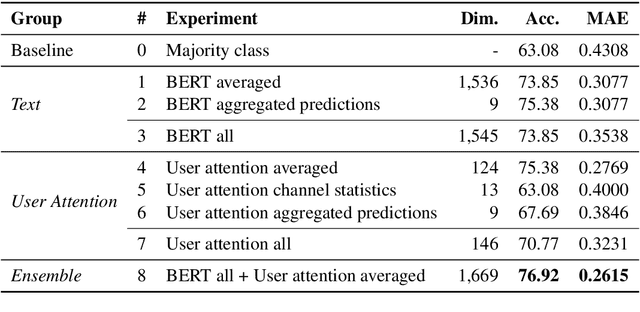
We propose a novel framework for predicting the factuality of reporting of news media outlets by studying the user attention cycles in their YouTube channels. In particular, we design a rich set of features derived from the temporal evolution of the number of views, likes, dislikes, and comments for a video, which we then aggregate to the channel level. We develop and release a dataset for the task, containing observations of user attention on YouTube channels for 489 news media. Our experiments demonstrate both complementarity and sizable improvements over state-of-the-art textual representations.
* Factuality, disinformation, misinformation, fake news, Youtube channels, propaganda, attention cycles
A Neighbourhood Framework for Resource-Lean Content Flagging
Mar 31, 2021
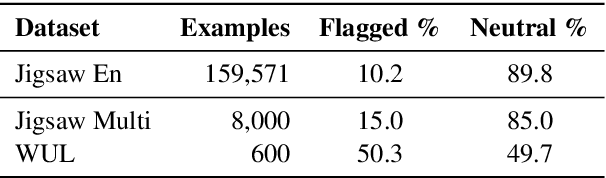
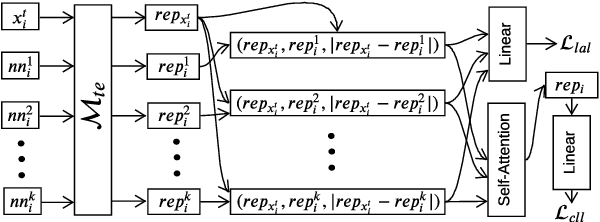
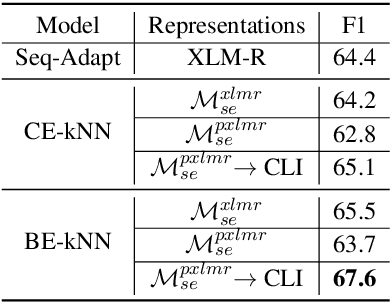
We propose a novel interpretable framework for cross-lingual content flagging, which significantly outperforms prior work both in terms of predictive performance and average inference time. The framework is based on a nearest-neighbour architecture and is interpretable by design. Moreover, it can easily adapt to new instances without the need to retrain it from scratch. Unlike prior work, (i) we encode not only the texts, but also the labels in the neighbourhood space (which yields better accuracy), and (ii) we use a bi-encoder instead of a cross-encoder (which saves computation time). Our evaluation results on ten different datasets for abusive language detection in eight languages shows sizable improvements over the state of the art, as well as a speed-up at inference time.
Detecting Abusive Language on Online Platforms: A Critical Analysis
Feb 27, 2021
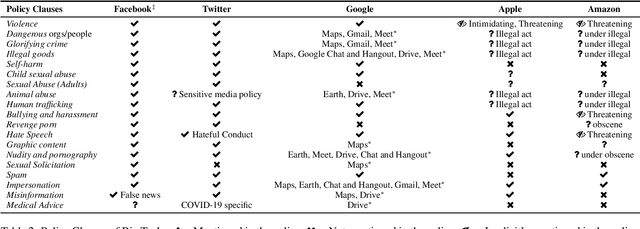
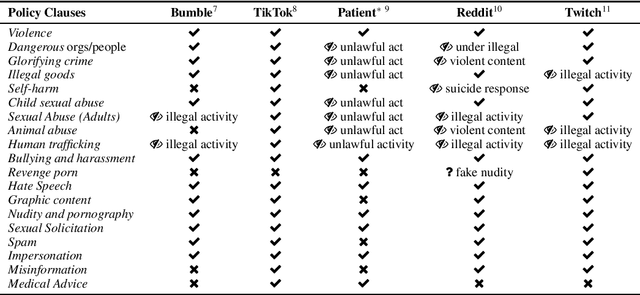

Abusive language on online platforms is a major societal problem, often leading to important societal problems such as the marginalisation of underrepresented minorities. There are many different forms of abusive language such as hate speech, profanity, and cyber-bullying, and online platforms seek to moderate it in order to limit societal harm, to comply with legislation, and to create a more inclusive environment for their users. Within the field of Natural Language Processing, researchers have developed different methods for automatically detecting abusive language, often focusing on specific subproblems or on narrow communities, as what is considered abusive language very much differs by context. We argue that there is currently a dichotomy between what types of abusive language online platforms seek to curb, and what research efforts there are to automatically detect abusive language. We thus survey existing methods as well as content moderation policies by online platforms in this light, and we suggest directions for future work.
EXAMS: A Multi-Subject High School Examinations Dataset for Cross-Lingual and Multilingual Question Answering
Nov 05, 2020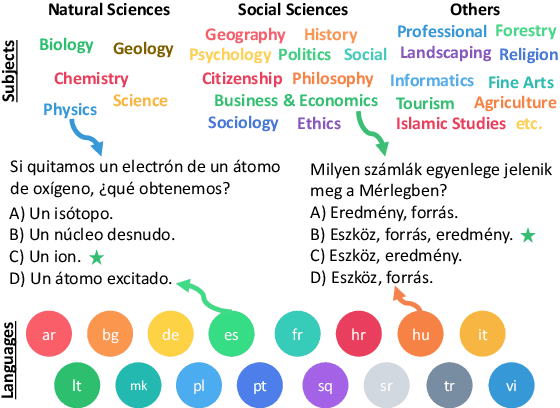
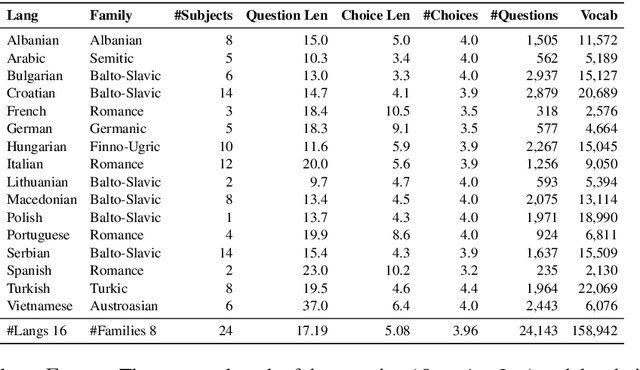

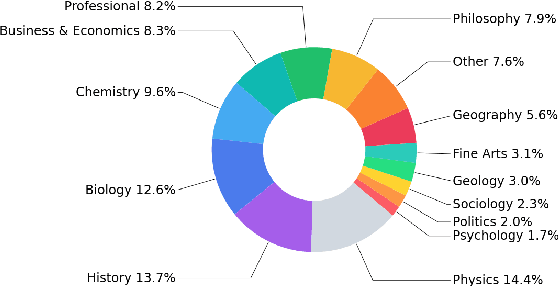
We propose EXAMS -- a new benchmark dataset for cross-lingual and multilingual question answering for high school examinations. We collected more than 24,000 high-quality high school exam questions in 16 languages, covering 8 language families and 24 school subjects from Natural Sciences and Social Sciences, among others. EXAMS offers a fine-grained evaluation framework across multiple languages and subjects, which allows precise analysis and comparison of various models. We perform various experiments with existing top-performing multilingual pre-trained models and we show that EXAMS offers multiple challenges that require multilingual knowledge and reasoning in multiple domains. We hope that EXAMS will enable researchers to explore challenging reasoning and knowledge transfer methods and pre-trained models for school question answering in various languages which was not possible before. The data, code, pre-trained models, and evaluation are available at https://github.com/mhardalov/exams-qa.
What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context
May 09, 2020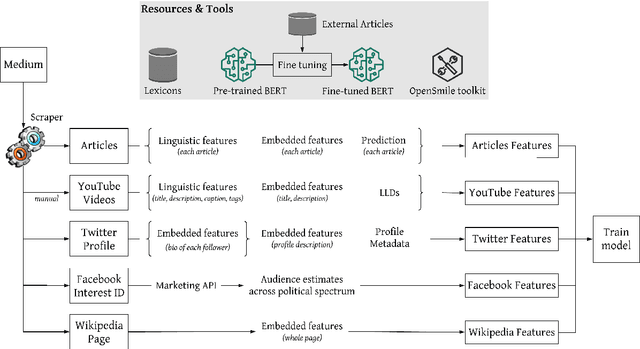
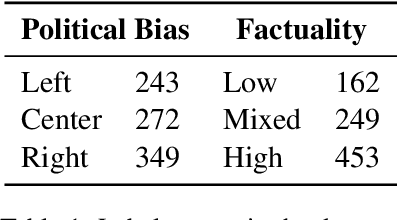
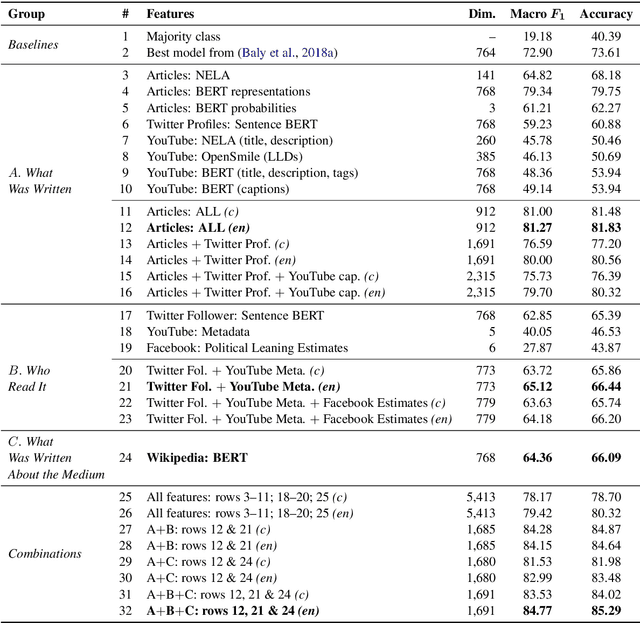
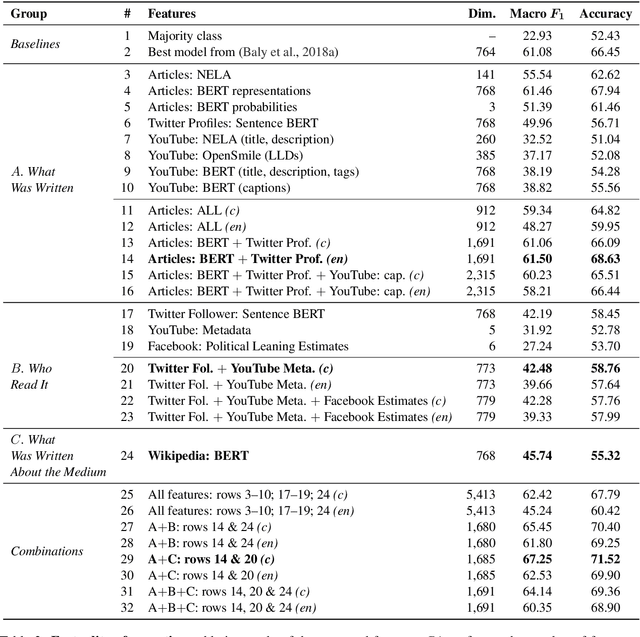
Predicting the political bias and the factuality of reporting of entire news outlets are critical elements of media profiling, which is an understudied but an increasingly important research direction. The present level of proliferation of fake, biased, and propagandistic content online, has made it impossible to fact-check every single suspicious claim, either manually or automatically. Alternatively, we can profile entire news outlets and look for those that are likely to publish fake or biased content. This approach makes it possible to detect likely "fake news" the moment they are published, by simply checking the reliability of their source. From a practical perspective, political bias and factuality of reporting have a linguistic aspect but also a social context. Here, we study the impact of both, namely (i) what was written (i.e., what was published by the target medium, and how it describes itself on Twitter) vs. (ii) who read it (i.e., analyzing the readers of the target medium on Facebook, Twitter, and YouTube). We further study (iii) what was written about the target medium on Wikipedia. The evaluation results show that what was written matters most, and that putting all information sources together yields huge improvements over the current state-of-the-art.
* Factuality of reporting, fact-checking, political ideology, media bias, disinformation, propaganda, social media, news media
Predicting the Leading Political Ideology of YouTube Channels Using Acoustic, Textual, and Metadata Information
Oct 20, 2019


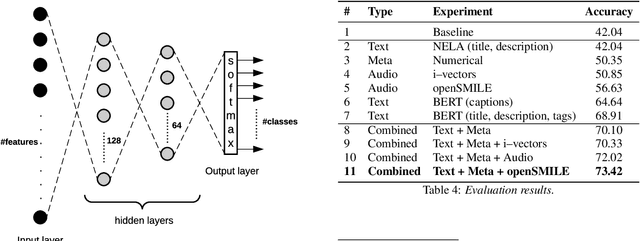
We address the problem of predicting the leading political ideology, i.e., left-center-right bias, for YouTube channels of news media. Previous work on the problem has focused exclusively on text and on analysis of the language used, topics discussed, sentiment, and the like. In contrast, here we study videos, which yields an interesting multimodal setup. Starting with gold annotations about the leading political ideology of major world news media from Media Bias/Fact Check, we searched on YouTube to find their corresponding channels, and we downloaded a recent sample of videos from each channel. We crawled more than 1,000 YouTube hours along with the corresponding subtitles and metadata, thus producing a new multimodal dataset. We further developed a multimodal deep-learning architecture for the task. Our analysis shows that the use of acoustic signal helped to improve bias detection by more than 6% absolute over using text and metadata only. We release the dataset to the research community, hoping to help advance the field of multi-modal political bias detection.
* media bias, political ideology, Youtube channels, propaganda, disinformation, fake news
Detecting Toxicity in News Articles: Application to Bulgarian
Aug 26, 2019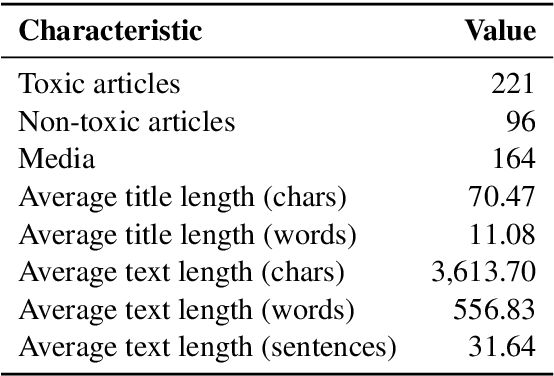
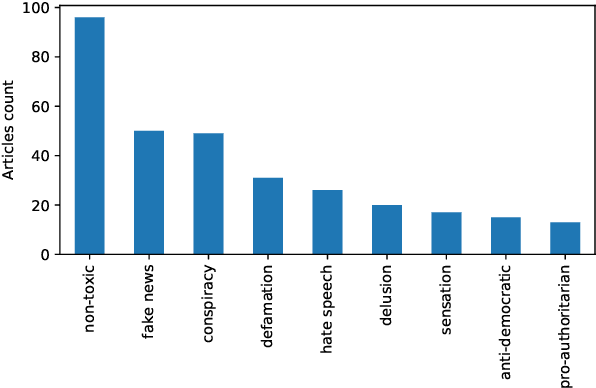
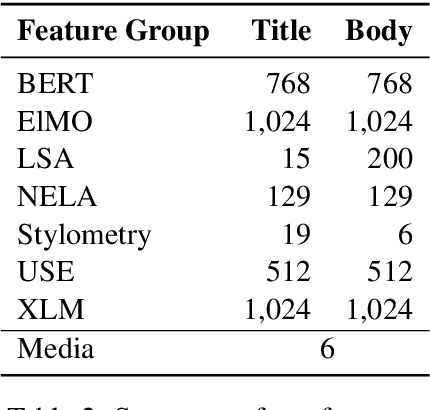
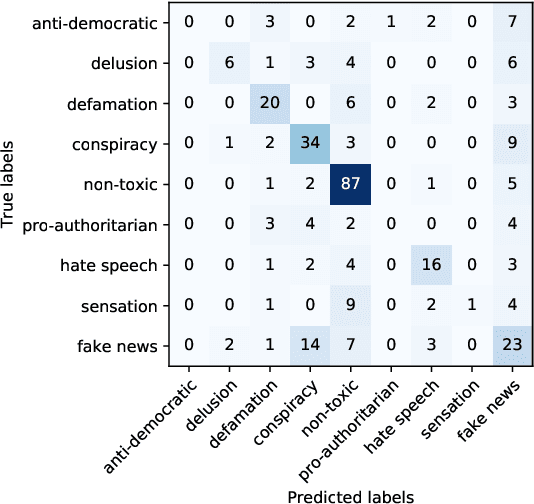
Online media aim for reaching ever bigger audience and for attracting ever longer attention span. This competition creates an environment that rewards sensational, fake, and toxic news. To help limit their spread and impact, we propose and develop a news toxicity detector that can recognize various types of toxic content. While previous research primarily focused on English, here we target Bulgarian. We created a new dataset by crawling a website that for five years has been collecting Bulgarian news articles that were manually categorized into eight toxicity groups. Then we trained a multi-class classifier with nine categories: eight toxic and one non-toxic. We experimented with different representations based on ElMo, BERT, and XLM, as well as with a variety of domain-specific features. Due to the small size of our dataset, we created a separate model for each feature type, and we ultimately combined these models into a meta-classifier. The evaluation results show an accuracy of 59.0% and a macro-F1 score of 39.7%, which represent sizable improvements over the majority-class baseline (Acc=30.3%, macro-F1=5.2%).
* Fact-checking, source reliability, political ideology, news media, Bulgarian, RANLP-2019. arXiv admin note: text overlap with arXiv:1810.01765