 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Data Selection for TTS: Using Arabic Broadcast News as a Case Study
Jan 26, 2023



Several high-resource Text to Speech (TTS) systems currently produce natural, well-established human-like speech. In contrast, low-resource languages, including Arabic, have very limited TTS systems due to the lack of resources. We propose a fully unsupervised method for building TTS, including automatic data selection and pre-training/fine-tuning strategies for TTS training, using broadcast news as a case study. We show how careful selection of data, yet smaller amounts, can improve the efficiency of TTS system in generating more natural speech than a system trained on a bigger dataset. We adopt to propose different approaches for the: 1) data: we applied automatic annotations using DNSMOS, automatic vowelization, and automatic speech recognition (ASR) for fixing transcriptions' errors; 2) model: we used transfer learning from high-resource language in TTS model and fine-tuned it with one hour broadcast recording then we used this model to guide a FastSpeech2-based Conformer model for duration. Our objective evaluation shows 3.9% character error rate (CER), while the groundtruth has 1.3% CER. As for the subjective evaluation, where 1 is bad and 5 is excellent, our FastSpeech2-based Conformer model achieved a mean opinion score (MOS) of 4.4 for intelligibility and 4.2 for naturalness, where many annotators recognized the voice of the broadcaster, which proves the effectiveness of our proposed unsupervised method.
Creating Speech-to-Speech Corpus from Dubbed Series
Mar 07, 2022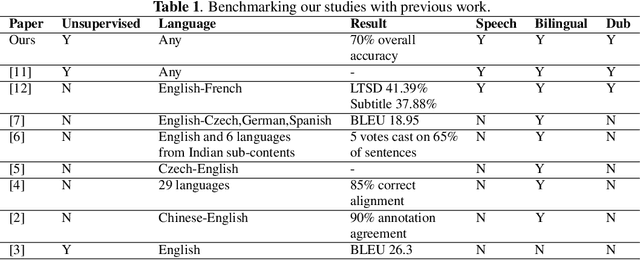
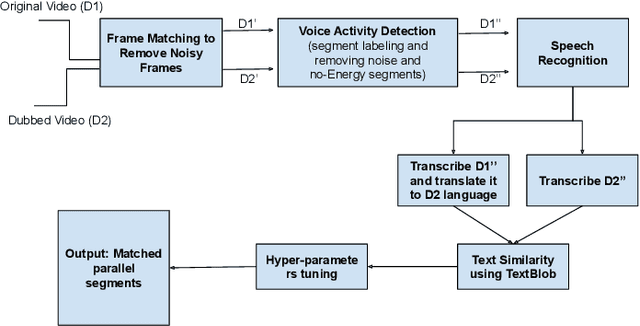
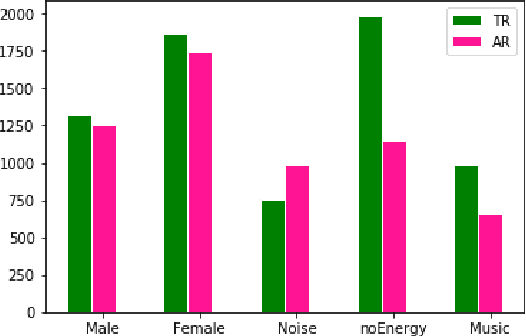

Dubbed series are gaining a lot of popularity in recent years with strong support from major media service providers. Such popularity is fueled by studies that showed that dubbed versions of TV shows are more popular than their subtitled equivalents. We propose an unsupervised approach to construct speech-to-speech corpus, aligned on short segment levels, to produce a parallel speech corpus in the source- and target- languages. Our methodology exploits video frames, speech recognition, machine translation, and noisy frames removal algorithms to match segments in both languages. To verify the performance of the proposed method, we apply it on long and short dubbed clips. Out of 36 hours TR-AR dubbed series, our pipeline was able to generate 17 hours of paired segments, which is about 47% of the corpus. We applied our method on another language pair, EN-AR, to ensure it is robust enough and not tuned for a specific language or a specific corpus. Regardless of the language pairs, the accuracy of the paired segments was around 70% when evaluated using human subjective evaluation. The corpus will be freely available for the research community.
A Panoramic Survey of Natural Language Processing in the Arab World
Nov 26, 2020The term natural language refers to any system of symbolic communication (spoken, signed or written) without intentional human planning and design. This distinguishes natural languages such as Arabic and Japanese from artificially constructed languages such as Esperanto or Python. Natural language processing (NLP) is the sub-field of artificial intelligence (AI) focused on modeling natural languages to build applications such as speech recognition and synthesis, machine translation, optical character recognition (OCR), sentiment analysis (SA), question answering, dialogue systems, etc. NLP is a highly interdisciplinary field with connections to computer science, linguistics, cognitive science, psychology, mathematics and others. Some of the earliest AI applications were in NLP (e.g., machine translation); and the last decade (2010-2020) in particular has witnessed an incredible increase in quality, matched with a rise in public awareness, use, and expectations of what may have seemed like science fiction in the past. NLP researchers pride themselves on developing language independent models and tools that can be applied to all human languages, e.g. machine translation systems can be built for a variety of languages using the same basic mechanisms and models. However, the reality is that some languages do get more attention (e.g., English and Chinese) than others (e.g., Hindi and Swahili). Arabic, the primary language of the Arab world and the religious language of millions of non-Arab Muslims is somewhere in the middle of this continuum. Though Arabic NLP has many challenges, it has seen many successes and developments. Next we discuss Arabic's main challenges as a necessary background, and we present a brief history of Arabic NLP. We then survey a number of its research areas, and close with a critical discussion of the future of Arabic NLP.
ArSentD-LEV: A Multi-Topic Corpus for Target-based Sentiment Analysis in Arabic Levantine Tweets
May 25, 2019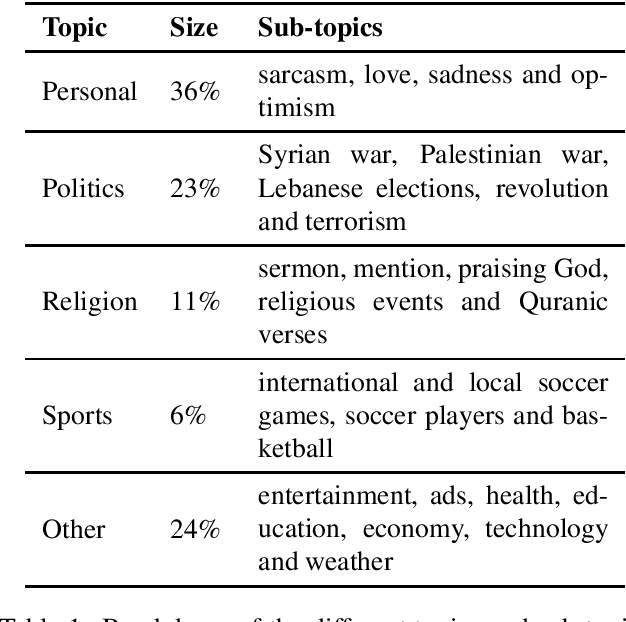
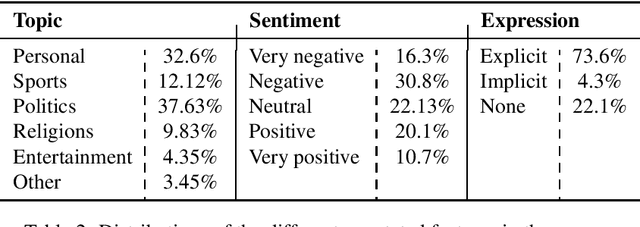
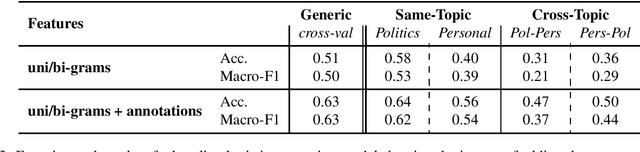
Sentiment analysis is a highly subjective and challenging task. Its complexity further increases when applied to the Arabic language, mainly because of the large variety of dialects that are unstandardized and widely used in the Web, especially in social media. While many datasets have been released to train sentiment classifiers in Arabic, most of these datasets contain shallow annotation, only marking the sentiment of the text unit, as a word, a sentence or a document. In this paper, we present the Arabic Sentiment Twitter Dataset for the Levantine dialect (ArSenTD-LEV). Based on findings from analyzing tweets from the Levant region, we created a dataset of 4,000 tweets with the following annotations: the overall sentiment of the tweet, the target to which the sentiment was expressed, how the sentiment was expressed, and the topic of the tweet. Results confirm the importance of these annotations at improving the performance of a baseline sentiment classifier. They also confirm the gap of training in a certain domain, and testing in another domain.