 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic speech recognition for the Nepali language using CNN, bidirectional LSTM and ResNet
Jun 25, 2024



This paper presents an end-to-end deep learning model for Automatic Speech Recognition (ASR) that transcribes Nepali speech to text. The model was trained and tested on the OpenSLR (audio, text) dataset. The majority of the audio dataset have silent gaps at both ends which are clipped during dataset preprocessing for a more uniform mapping of audio frames and their corresponding texts. Mel Frequency Cepstral Coefficients (MFCCs) are used as audio features to feed into the model. The model having Bidirectional LSTM paired with ResNet and one-dimensional CNN produces the best results for this dataset out of all the models (neural networks with variations of LSTM, GRU, CNN, and ResNet) that have been trained so far. This novel model uses Connectionist Temporal Classification (CTC) function for loss calculation during training and CTC beam search decoding for predicting characters as the most likely sequence of Nepali text. On the test dataset, the character error rate (CER) of 17.06 percent has been achieved. The source code is available at: https://github.com/manishdhakal/ASR-Nepali-using-CNN-BiLSTM-ResNet.
* Accepted at 2022 International Conference on Inventive Computation Technologies (ICICT), IEEE
Towards Handling Unconstrained User Preferences in Dialogue
Sep 17, 2021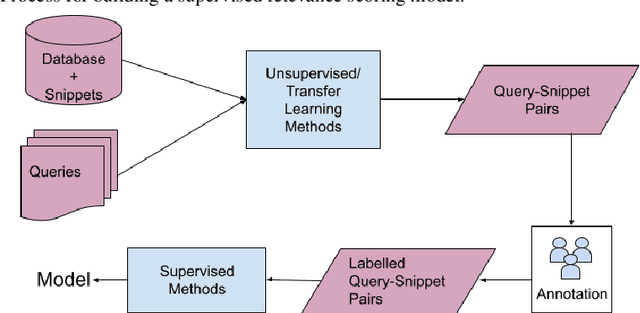

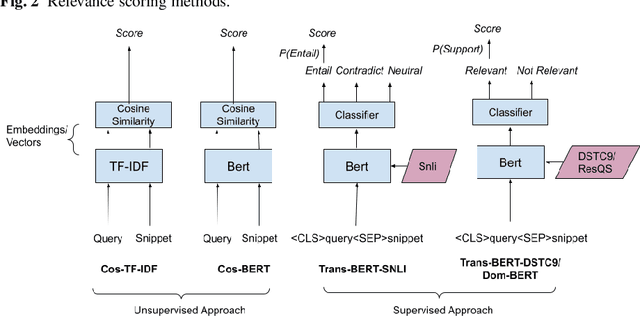
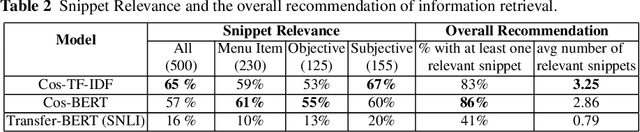
A user input to a schema-driven dialogue information navigation system, such as venue search, is typically constrained by the underlying database which restricts the user to specify a predefined set of preferences, or slots, corresponding to the database fields. We envision a more natural information navigation dialogue interface where a user has flexibility to specify unconstrained preferences that may not match a predefined schema. We propose to use information retrieval from unstructured knowledge to identify entities relevant to a user request. We update the Cambridge restaurants database with unstructured knowledge snippets (reviews and information from the web) for each of the restaurants and annotate a set of query-snippet pairs with a relevance label. We use the annotated dataset to train and evaluate snippet relevance classifiers, as a proxy to evaluating recommendation accuracy. We show that with a pretrained transformer model as an encoder, an unsupervised/supervised classifier achieves a weighted F1 of .661/.856.
SemEval-2020 Task 9: Overview of Sentiment Analysis of Code-Mixed Tweets
Aug 10, 2020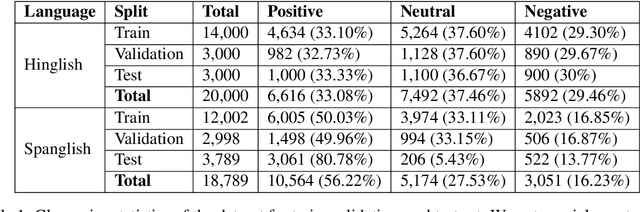

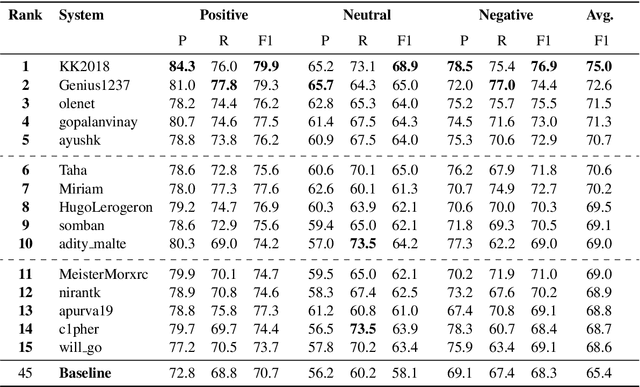
In this paper, we present the results of the SemEval-2020 Task 9 on Sentiment Analysis of Code-Mixed Tweets (SentiMix 2020). We also release and describe our Hinglish (Hindi-English) and Spanglish (Spanish-English) corpora annotated with word-level language identification and sentence-level sentiment labels. These corpora are comprised of 20K and 19K examples, respectively. The sentiment labels are - Positive, Negative, and Neutral. SentiMix attracted 89 submissions in total including 61 teams that participated in the Hinglish contest and 28 submitted systems to the Spanglish competition. The best performance achieved was 75.0% F1 score for Hinglish and 80.6% F1 for Spanglish. We observe that BERT-like models and ensemble methods are the most common and successful approaches among the participants.