 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2020 Task 9: Overview of Sentiment Analysis of Code-Mixed Tweets
Paper and Code
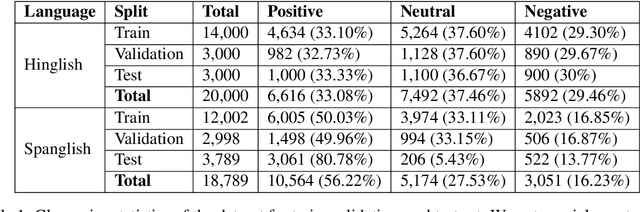
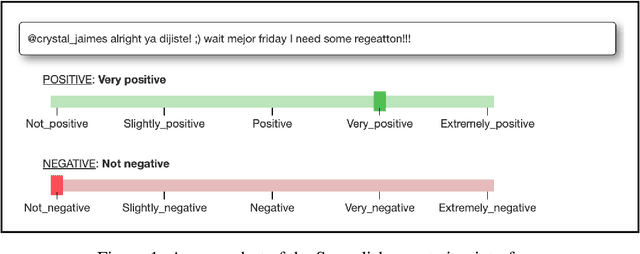

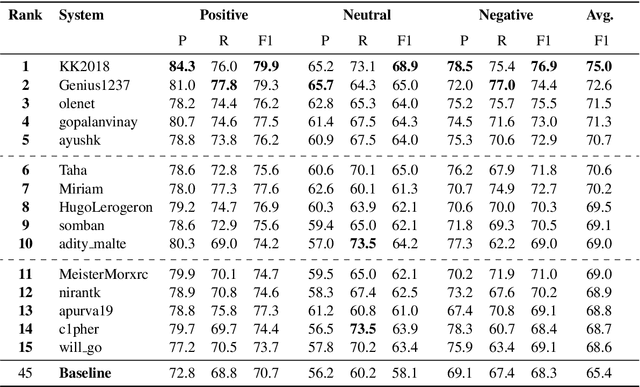
In this paper, we present the results of the SemEval-2020 Task 9 on Sentiment Analysis of Code-Mixed Tweets (SentiMix 2020). We also release and describe our Hinglish (Hindi-English) and Spanglish (Spanish-English) corpora annotated with word-level language identification and sentence-level sentiment labels. These corpora are comprised of 20K and 19K examples, respectively. The sentiment labels are - Positive, Negative, and Neutral. SentiMix attracted 89 submissions in total including 61 teams that participated in the Hinglish contest and 28 submitted systems to the Spanglish competition. The best performance achieved was 75.0% F1 score for Hinglish and 80.6% F1 for Spanglish. We observe that BERT-like models and ensemble methods are the most common and successful approaches among the participants.