 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHater-O-Genius Aggression Classification using Capsule Networks
May 24, 2021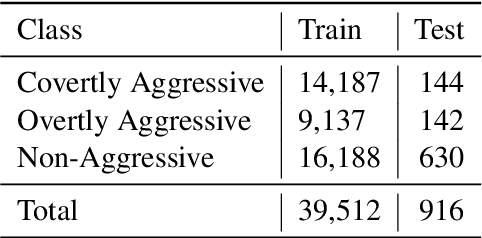
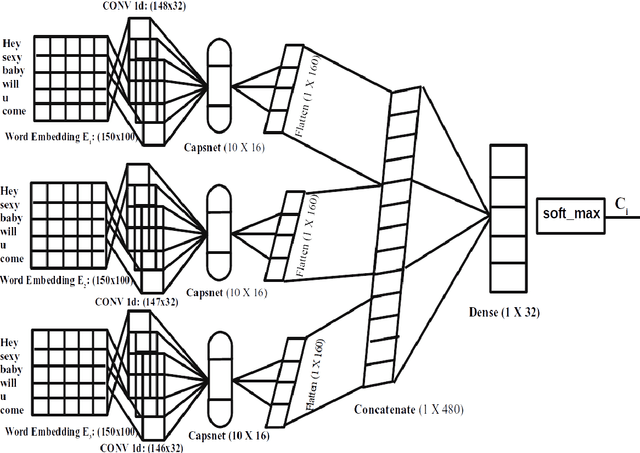
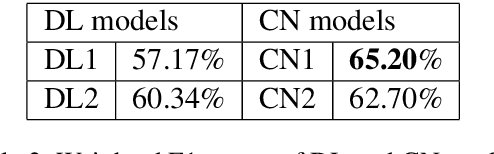
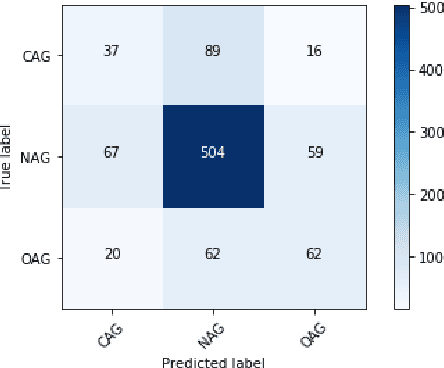
Contending hate speech in social media is one of the most challenging social problems of our time. There are various types of anti-social behavior in social media. Foremost of them is aggressive behavior, which is causing many social issues such as affecting the social lives and mental health of social media users. In this paper, we propose an end-to-end ensemble-based architecture to automatically identify and classify aggressive tweets. Tweets are classified into three categories - Covertly Aggressive, Overtly Aggressive, and Non-Aggressive. The proposed architecture is an ensemble of smaller subnetworks that are able to characterize the feature embeddings effectively. We demonstrate qualitatively that each of the smaller subnetworks is able to learn unique features. Our best model is an ensemble of Capsule Networks and results in a 65.2% F1 score on the Facebook test set, which results in a performance gain of 0.95% over the TRAC-2018 winners. The code and the model weights are publicly available at https://github.com/parthpatwa/Hater-O-Genius-Aggression-Classification-using-Capsule-Networks.
Fighting an Infodemic: COVID-19 Fake News Dataset
Nov 06, 2020


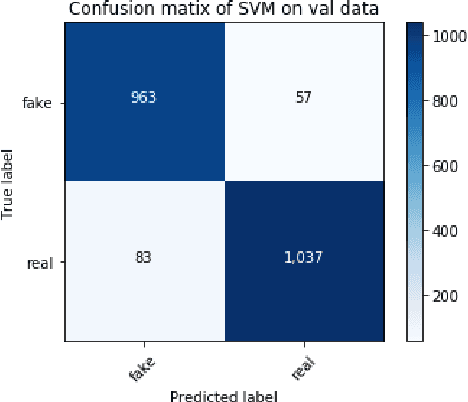
Along with COVID-19 pandemic we are also fighting an `infodemic'. Fake news and rumors are rampant on social media. Believing in rumors can cause significant harm. This is further exacerbated at the time of a pandemic. To tackle this, we curate and release a manually annotated dataset of 10,700 social media posts and articles of real and fake news on COVID-19. We benchmark the annotated dataset with four machine learning baselines - Decision Tree, Logistic Regression , Gradient Boost , and Support Vector Machine (SVM). We obtain the best performance of 93.46\% F1-score with SVM. The data and code is available at: https://github.com/parthpatwa/covid19-fake-news-dectection
SemEval-2020 Task 9: Overview of Sentiment Analysis of Code-Mixed Tweets
Aug 10, 2020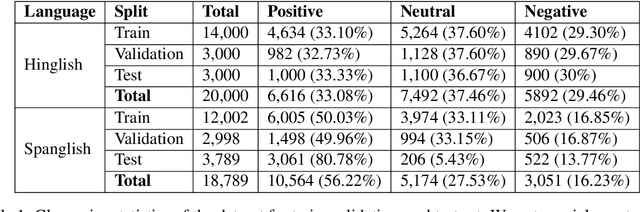
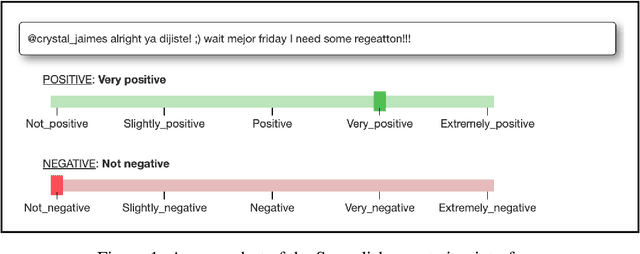

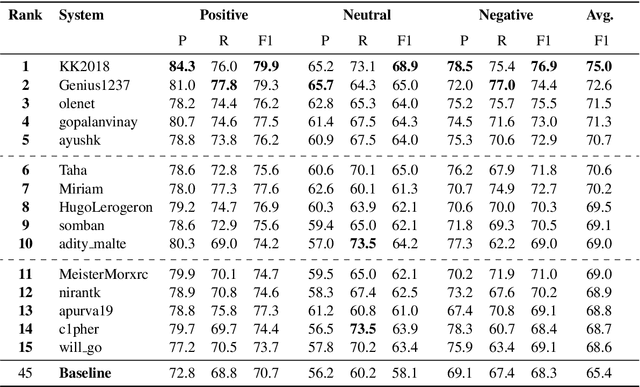
In this paper, we present the results of the SemEval-2020 Task 9 on Sentiment Analysis of Code-Mixed Tweets (SentiMix 2020). We also release and describe our Hinglish (Hindi-English) and Spanglish (Spanish-English) corpora annotated with word-level language identification and sentence-level sentiment labels. These corpora are comprised of 20K and 19K examples, respectively. The sentiment labels are - Positive, Negative, and Neutral. SentiMix attracted 89 submissions in total including 61 teams that participated in the Hinglish contest and 28 submitted systems to the Spanglish competition. The best performance achieved was 75.0% F1 score for Hinglish and 80.6% F1 for Spanglish. We observe that BERT-like models and ensemble methods are the most common and successful approaches among the participants.
SemEval-2020 Task 8: Memotion Analysis -- The Visuo-Lingual Metaphor!
Aug 09, 2020


Information on social media comprises of various modalities such as textual, visual and audio. NLP and Computer Vision communities often leverage only one prominent modality in isolation to study social media. However, the computational processing of Internet memes needs a hybrid approach. The growing ubiquity of Internet memes on social media platforms such as Facebook, Instagram, and Twiter further suggests that we can not ignore such multimodal content anymore. To the best of our knowledge, there is not much attention towards meme emotion analysis. The objective of this proposal is to bring the attention of the research community towards the automatic processing of Internet memes. The task Memotion analysis released approx 10K annotated memes, with human-annotated labels namely sentiment (positive, negative, neutral), type of emotion (sarcastic, funny, offensive, motivation) and their corresponding intensity. The challenge consisted of three subtasks: sentiment (positive, negative, and neutral) analysis of memes, overall emotion (humour, sarcasm, offensive, and motivational) classification of memes, and classifying intensity of meme emotion. The best performances achieved were F1 (macro average) scores of 0.35, 0.51 and 0.32, respectively for each of the three subtasks.