 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Aware Feedback-Based Self-Learning in Large-Scale Conversational AI
Apr 29, 2022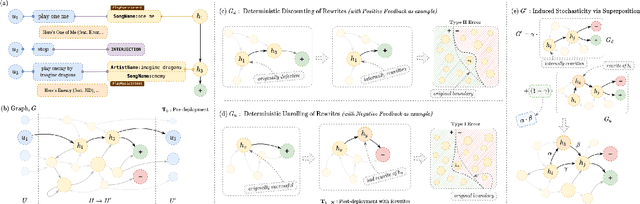
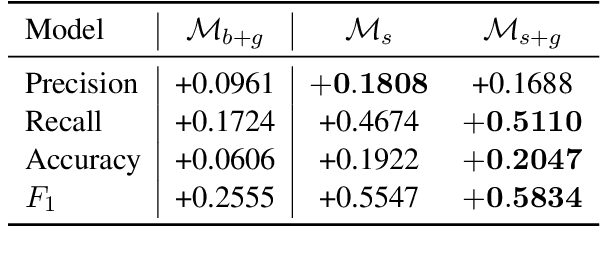
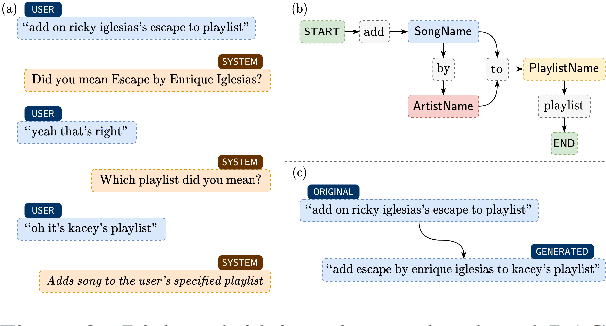

Self-learning paradigms in large-scale conversational AI agents tend to leverage user feedback in bridging between what they say and what they mean. However, such learning, particularly in Markov-based query rewriting systems have far from addressed the impact of these models on future training where successive feedback is inevitably contingent on the rewrite itself, especially in a continually updating environment. In this paper, we explore the consequences of this inherent lack of self-awareness towards impairing the model performance, ultimately resulting in both Type I and II errors over time. To that end, we propose augmenting the Markov Graph construction with a superposition-based adjacency matrix. Here, our method leverages an induced stochasticity to reactively learn a locally-adaptive decision boundary based on the performance of the individual rewrites in a bi-variate beta setting. We also surface a data augmentation strategy that leverages template-based generation in abridging complex conversation hierarchies of dialogs so as to simplify the learning process. All in all, we demonstrate that our self-aware model improves the overall PR-AUC by 27.45%, achieves a relative defect reduction of up to 31.22%, and is able to adapt quicker to changes in global preferences across a large number of customers.
A Vocabulary-Free Multilingual Neural Tokenizer for End-to-End Task Learning
Apr 22, 2022
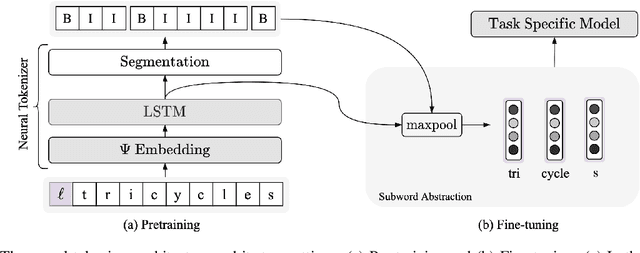
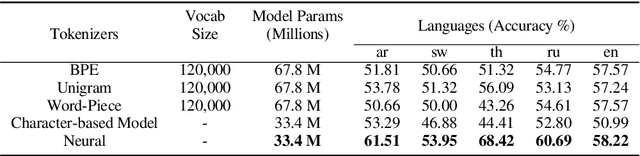

Subword tokenization is a commonly used input pre-processing step in most recent NLP models. However, it limits the models' ability to leverage end-to-end task learning. Its frequency-based vocabulary creation compromises tokenization in low-resource languages, leading models to produce suboptimal representations. Additionally, the dependency on a fixed vocabulary limits the subword models' adaptability across languages and domains. In this work, we propose a vocabulary-free neural tokenizer by distilling segmentation information from heuristic-based subword tokenization. We pre-train our character-based tokenizer by processing unique words from multilingual corpus, thereby extensively increasing word diversity across languages. Unlike the predefined and fixed vocabularies in subword methods, our tokenizer allows end-to-end task learning, resulting in optimal task-specific tokenization. The experimental results show that replacing the subword tokenizer with our neural tokenizer consistently improves performance on multilingual (NLI) and code-switching (sentiment analysis) tasks, with larger gains in low-resource languages. Additionally, our neural tokenizer exhibits a robust performance on downstream tasks when adversarial noise is present (typos and misspelling), further increasing the initial improvements over statistical subword tokenizers.
CALCS 2021 Shared Task: Machine Translation for Code-Switched Data
Feb 19, 2022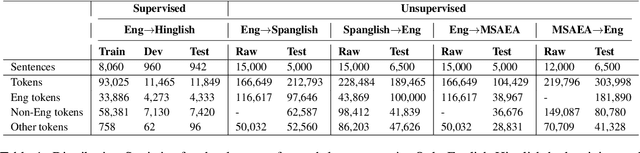
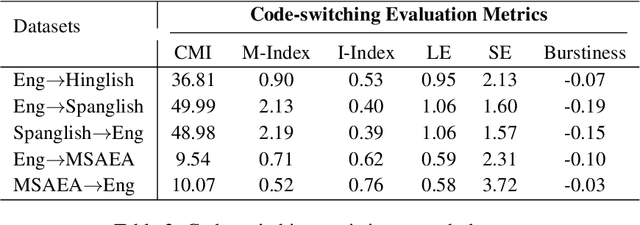

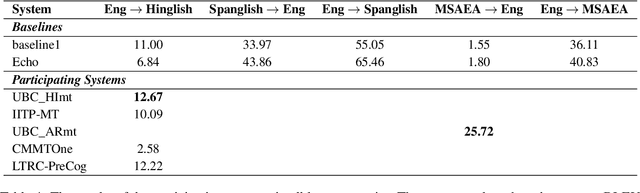
To date, efforts in the code-switching literature have focused for the most part on language identification, POS, NER, and syntactic parsing. In this paper, we address machine translation for code-switched social media data. We create a community shared task. We provide two modalities for participation: supervised and unsupervised. For the supervised setting, participants are challenged to translate English into Hindi-English (Eng-Hinglish) in a single direction. For the unsupervised setting, we provide the following language pairs: English and Spanish-English (Eng-Spanglish), and English and Modern Standard Arabic-Egyptian Arabic (Eng-MSAEA) in both directions. We share insights and challenges in curating the "into" code-switching language evaluation data. Further, we provide baselines for all language pairs in the shared task. The leaderboard for the shared task comprises 12 individual system submissions corresponding to 5 different teams. The best performance achieved is 12.67% BLEU score for English to Hinglish and 25.72% BLEU score for MSAEA to English.
Data Augmentation for Cross-Domain Named Entity Recognition
Sep 04, 2021
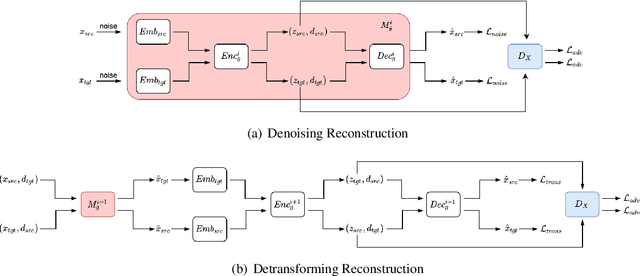
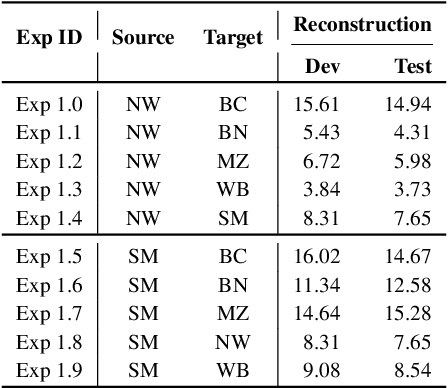
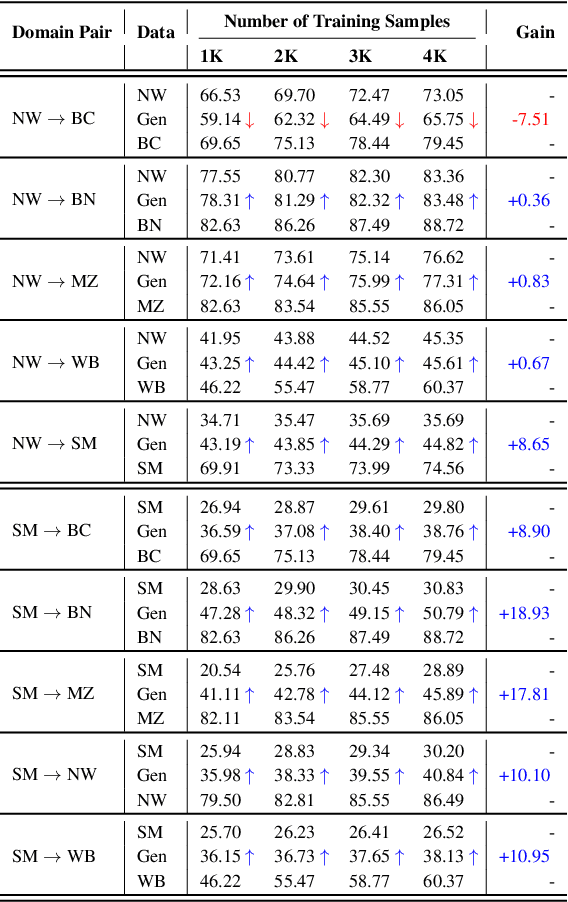
Current work in named entity recognition (NER) shows that data augmentation techniques can produce more robust models. However, most existing techniques focus on augmenting in-domain data in low-resource scenarios where annotated data is quite limited. In contrast, we study cross-domain data augmentation for the NER task. We investigate the possibility of leveraging data from high-resource domains by projecting it into the low-resource domains. Specifically, we propose a novel neural architecture to transform the data representation from a high-resource to a low-resource domain by learning the patterns (e.g. style, noise, abbreviations, etc.) in the text that differentiate them and a shared feature space where both domains are aligned. We experiment with diverse datasets and show that transforming the data to the low-resource domain representation achieves significant improvements over only using data from high-resource domains.
Char2Subword: Extending the Subword Embedding Space from Pre-trained Models Using Robust Character Compositionality
Oct 24, 2020

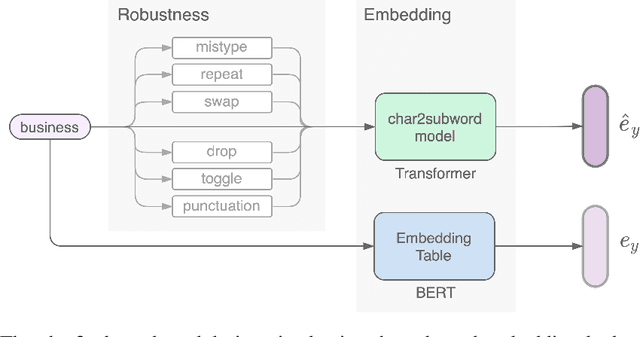
Byte-pair encoding (BPE) is a ubiquitous algorithm in the subword tokenization process of language models. BPE provides multiple benefits, such as handling the out-of-vocabulary problem and reducing vocabulary sparsity. However, this process is defined from the pre-training data statistics, making the tokenization on different domains susceptible to infrequent spelling sequences (e.g., misspellings as in social media or character-level adversarial attacks). On the other hand, pure character-level models, though robust to misspellings, often lead to unreasonably large sequence lengths and make it harder for the model to learn meaningful contiguous characters. To alleviate these challenges, we propose a character-based subword transformer module (char2subword) that learns the subword embedding table in pre-trained models like BERT. Our char2subword module builds representations from characters out of the subword vocabulary, and it can be used as a drop-in replacement of the subword embedding table. The module is robust to character-level alterations such as misspellings, word inflection, casing, and punctuation. We integrate it further with BERT through pre-training while keeping BERT transformer parameters fixed. We show our method's effectiveness by outperforming a vanilla multilingual BERT on the linguistic code-switching evaluation (LinCE) benchmark.
A Caption Is Worth A Thousand Images: Investigating Image Captions for Multimodal Named Entity Recognition
Oct 23, 2020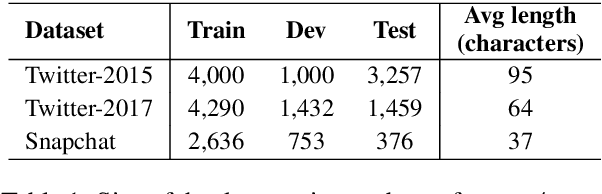

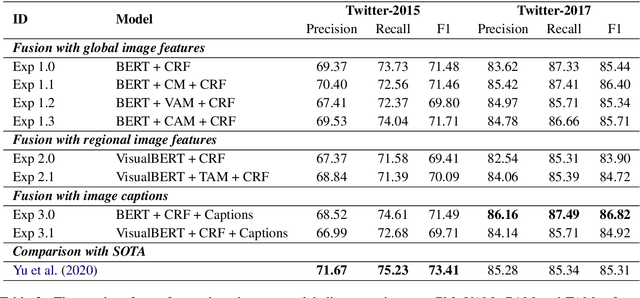
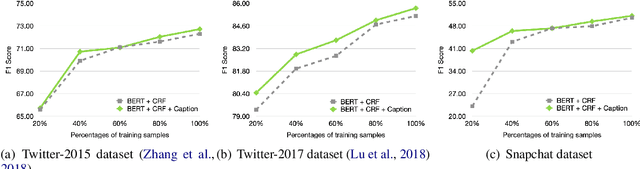
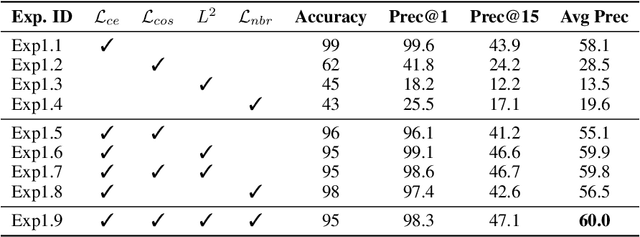
Multimodal named entity recognition (MNER) requires to bridge the gap between language understanding and visual context. Due to advances in natural language processing (NLP) and computer vision (CV), many neural techniques have been proposed to incorporate images into the NER task. In this work, we conduct a detailed analysis of current state-of-the-art fusion techniques for MNER and describe scenarios where adding information from the image does not always result in boosts in performance. We also study the use of captions as a way to enrich the context for MNER. We provide extensive empirical analysis and an ablation study on three datasets from popular social platforms to expose the situations where the approach is beneficial.
SemEval-2020 Task 9: Overview of Sentiment Analysis of Code-Mixed Tweets
Aug 10, 2020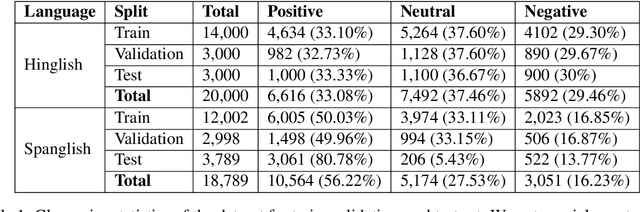
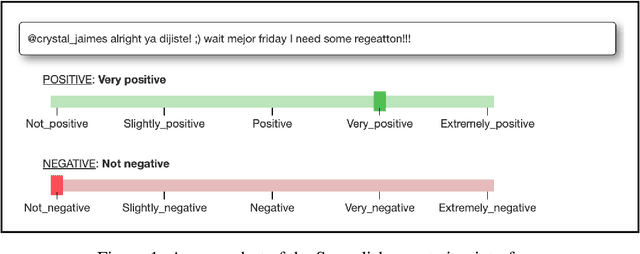

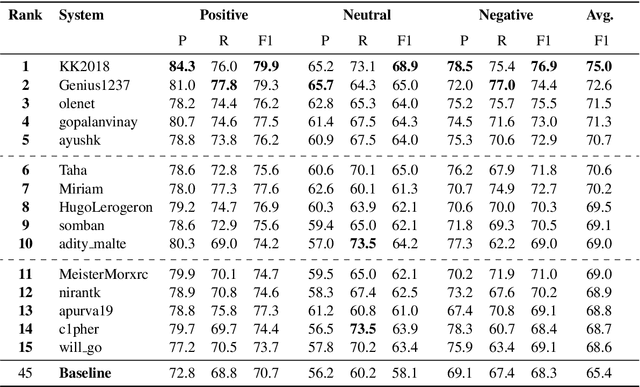
In this paper, we present the results of the SemEval-2020 Task 9 on Sentiment Analysis of Code-Mixed Tweets (SentiMix 2020). We also release and describe our Hinglish (Hindi-English) and Spanglish (Spanish-English) corpora annotated with word-level language identification and sentence-level sentiment labels. These corpora are comprised of 20K and 19K examples, respectively. The sentiment labels are - Positive, Negative, and Neutral. SentiMix attracted 89 submissions in total including 61 teams that participated in the Hinglish contest and 28 submitted systems to the Spanglish competition. The best performance achieved was 75.0% F1 score for Hinglish and 80.6% F1 for Spanglish. We observe that BERT-like models and ensemble methods are the most common and successful approaches among the participants.
LinCE: A Centralized Benchmark for Linguistic Code-switching Evaluation
May 09, 2020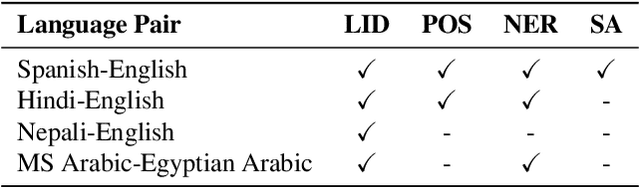
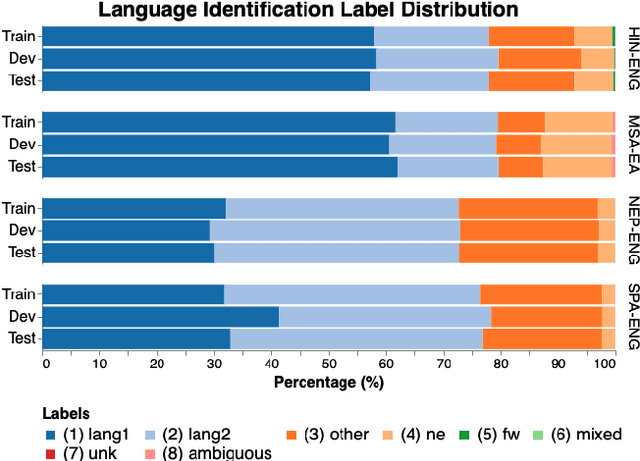
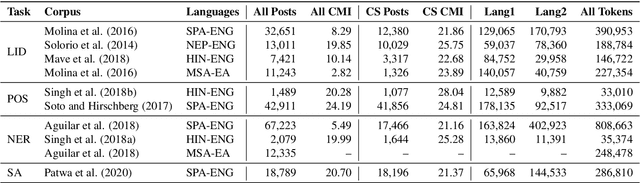
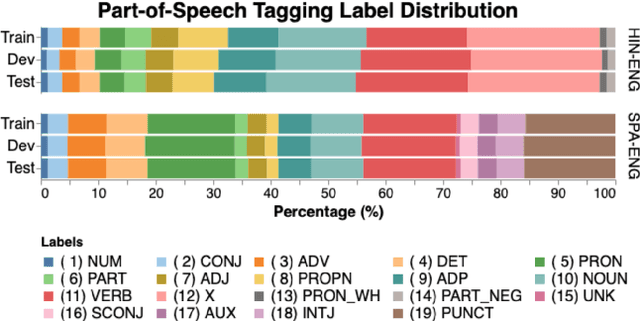
Recent trends in NLP research have raised an interest in linguistic code-switching (CS); modern approaches have been proposed to solve a wide range of NLP tasks on multiple language pairs. Unfortunately, these proposed methods are hardly generalizable to different code-switched languages. In addition, it is unclear whether a model architecture is applicable for a different task while still being compatible with the code-switching setting. This is mainly because of the lack of a centralized benchmark and the sparse corpora that researchers employ based on their specific needs and interests. To facilitate research in this direction, we propose a centralized benchmark for Linguistic Code-switching Evaluation (LinCE) that combines ten corpora covering four different code-switched language pairs (i.e., Spanish-English, Nepali-English, Hindi-English, and Modern Standard Arabic-Egyptian Arabic) and four tasks (i.e., language identification, named entity recognition, part-of-speech tagging, and sentiment analysis). As part of the benchmark centralization effort, we provide an online platform at ritual.uh.edu/lince, where researchers can submit their results while comparing with others in real-time. In addition, we provide the scores of different popular models, including LSTM, ELMo, and multilingual BERT so that the NLP community can compare against state-of-the-art systems. LinCE is a continuous effort, and we will expand it with more low-resource languages and tasks.
Knowledge Distillation from Internal Representations
Oct 08, 2019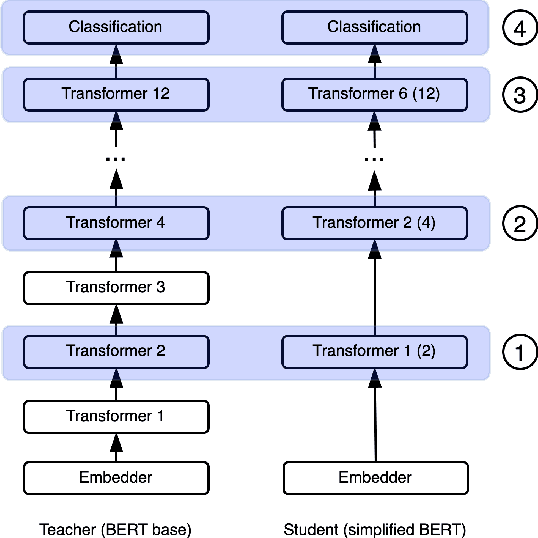
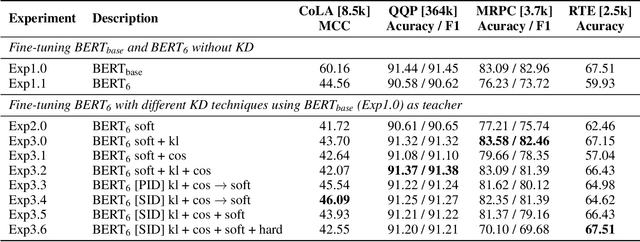
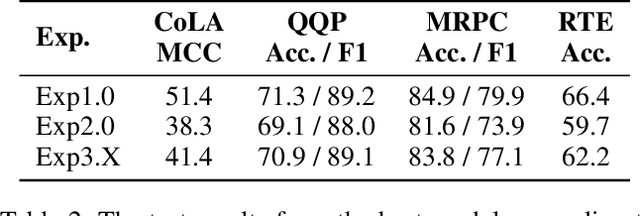
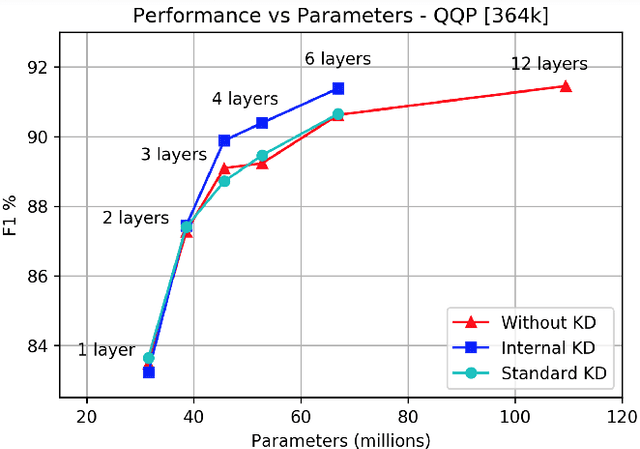
Knowledge distillation is typically conducted by training a small model (the student) to mimic a large and cumbersome model (the teacher). The idea is to compress the knowledge from the teacher by using its output probabilities as soft-labels to optimize the student. However, when the teacher is considerably large, there is no guarantee that the internal knowledge of the teacher will be transferred into the student; even if the student closely matches the soft-labels, its internal representations may be considerably different. This internal mismatch can undermine the generalization capabilities originally intended to be transferred from the teacher to the student. In this paper, we propose to distill the internal representations of a large model such as BERT into a simplified version of it. We formulate two ways to distill such representations and various algorithms to conduct the distillation. We experiment with datasets from the GLUE benchmark and consistently show that adding knowledge distillation from internal representations is a more powerful method than only using soft-label distillation.
From English to Code-Switching: Transfer Learning with Strong Morphological Clues
Sep 12, 2019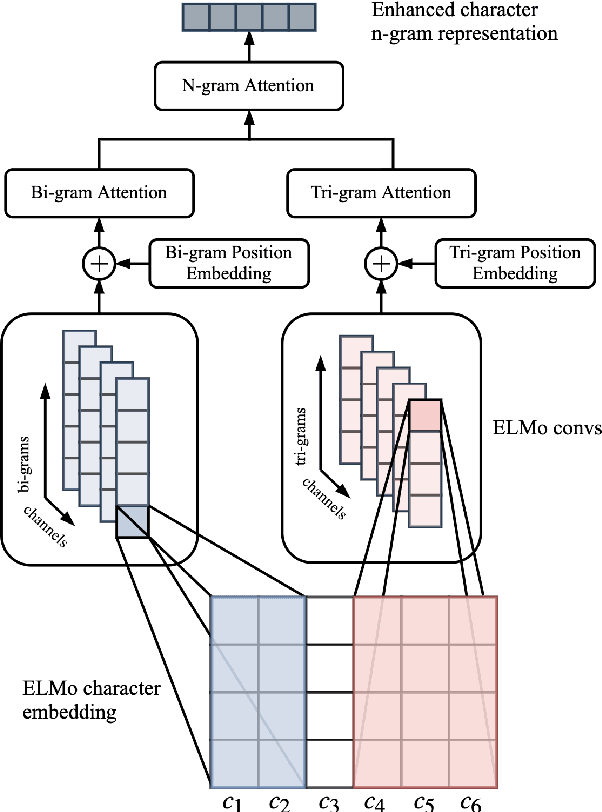
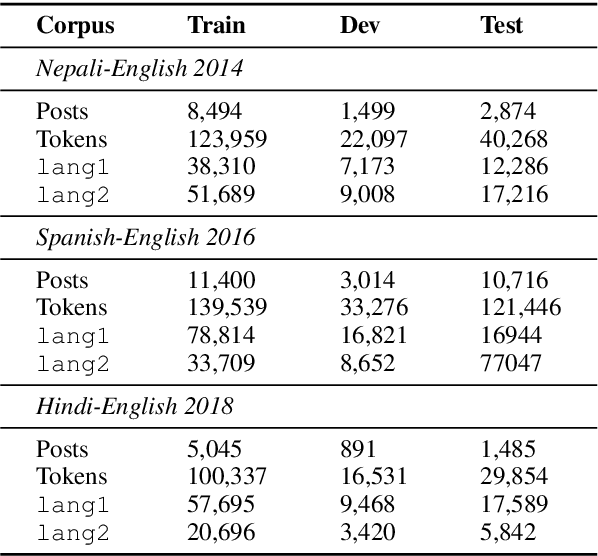
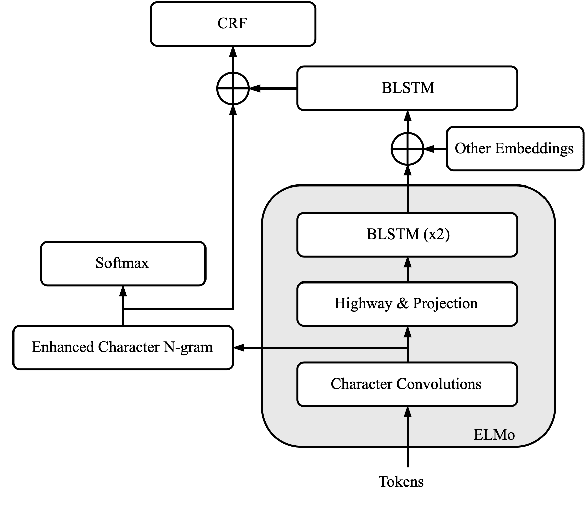
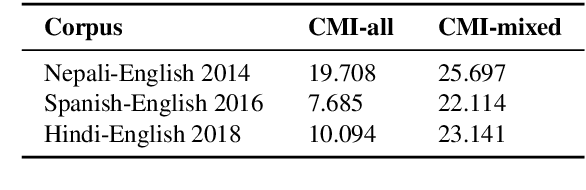
Code-switching is still an understudied phenomenon in natural language processing mainly because of two related challenges: it lacks annotated data, and it combines a vast diversity of low-resource languages. Despite the language diversity, many code-switching scenarios occur in language pairs, and English is often a common factor among them. In the first part of this paper, we use transfer learning from English to English-paired code-switched languages for the language identification (LID) task by applying two simple yet effective techniques: 1) a hierarchical attention mechanism that enhances morphological clues from character n-grams, and 2) a secondary loss that forces the model to learn n-gram representations that are particular to the languages involved. We use the bottom layers of the ELMo architecture to learn these morphological clues by essentially recognizing what is and what is not English. Our approach outperforms the previous state of the art on Nepali-English, Spanish-English, and Hindi-English datasets. In the second part of the paper, we use our best LID models for the tasks of Spanish-English named entity recognition and Hindi-English part-of-speech tagging by replacing their inference layers and retraining them. We show that our retrained models are capable of using the code-switching information on both tasks to outperform models that do not have such knowledge.