 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom English to Code-Switching: Transfer Learning with Strong Morphological Clues
Paper and Code
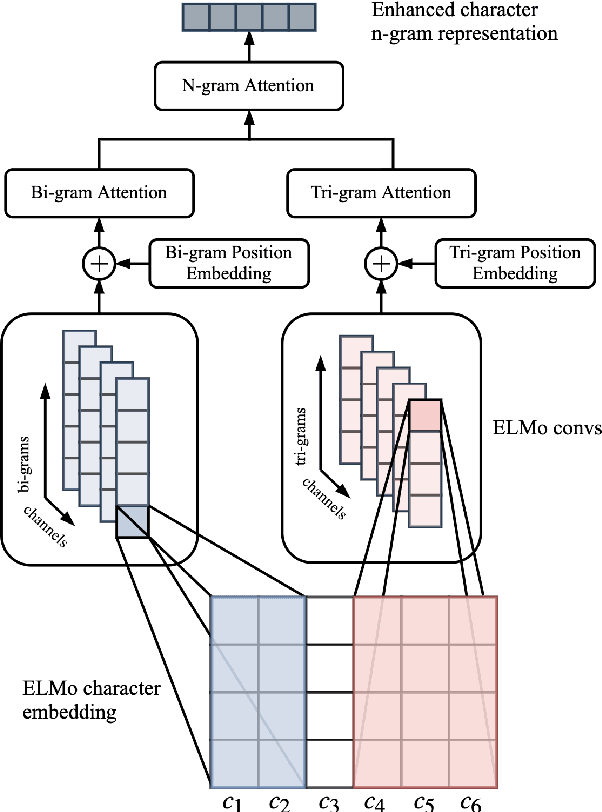
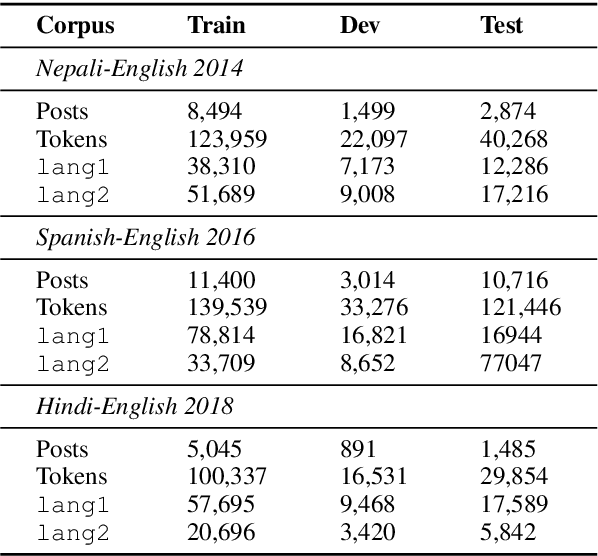
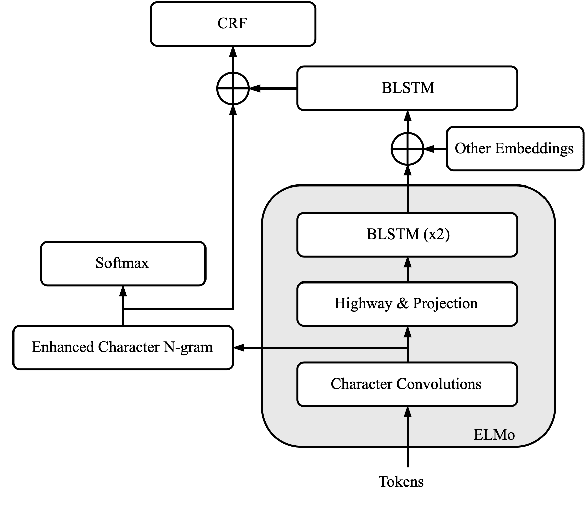
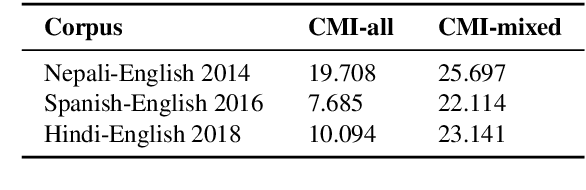
Code-switching is still an understudied phenomenon in natural language processing mainly because of two related challenges: it lacks annotated data, and it combines a vast diversity of low-resource languages. Despite the language diversity, many code-switching scenarios occur in language pairs, and English is often a common factor among them. In the first part of this paper, we use transfer learning from English to English-paired code-switched languages for the language identification (LID) task by applying two simple yet effective techniques: 1) a hierarchical attention mechanism that enhances morphological clues from character n-grams, and 2) a secondary loss that forces the model to learn n-gram representations that are particular to the languages involved. We use the bottom layers of the ELMo architecture to learn these morphological clues by essentially recognizing what is and what is not English. Our approach outperforms the previous state of the art on Nepali-English, Spanish-English, and Hindi-English datasets. In the second part of the paper, we use our best LID models for the tasks of Spanish-English named entity recognition and Hindi-English part-of-speech tagging by replacing their inference layers and retraining them. We show that our retrained models are capable of using the code-switching information on both tasks to outperform models that do not have such knowledge.