 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Unimodal Language Agent Provide Preferences to Tune a Multimodal Vision-Language Model?
Jan 10, 2026To explore a more scalable path for adding multimodal capabilities to existing LLMs, this paper addresses a fundamental question: Can a unimodal LLM, relying solely on text, reason about its own informational needs and provide effective feedback to optimize a multimodal model? To answer this, we propose a method that enables a language agent to give feedback to a vision-language model (VLM) to adapt text generation to the agent's preferences. Our results from different experiments affirm this hypothesis, showing that LLM preference feedback significantly enhances VLM descriptions. Using our proposed method, we find that the VLM can generate multimodal scene descriptions to help the LLM better understand multimodal context, leading to improvements of maximum 13% in absolute accuracy compared to the baseline multimodal approach. Furthermore, a human study validated our AI-driven feedback, showing a 64.6% preference alignment rate between the LLM's choices and human judgments. Extensive experiments provide insights on how and why the method works and its limitations.
GFT: Graph Feature Tuning for Efficient Point Cloud Analysis
Nov 13, 2025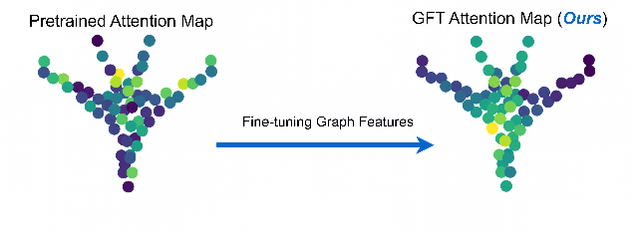
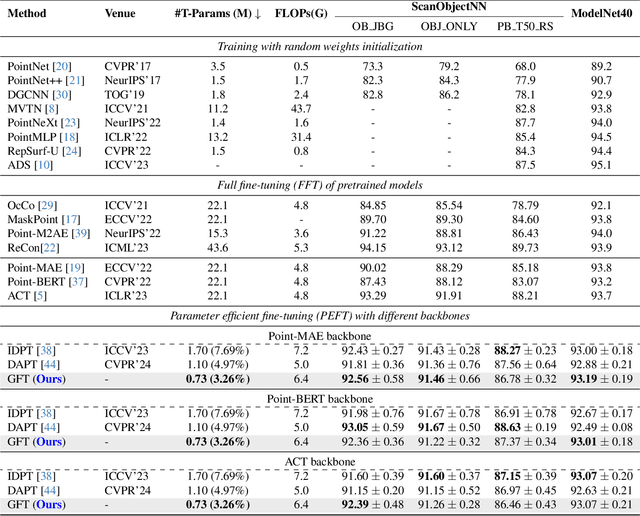
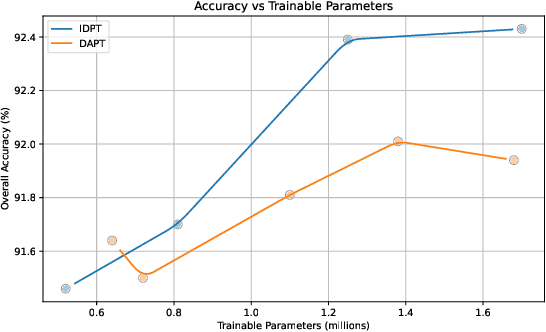
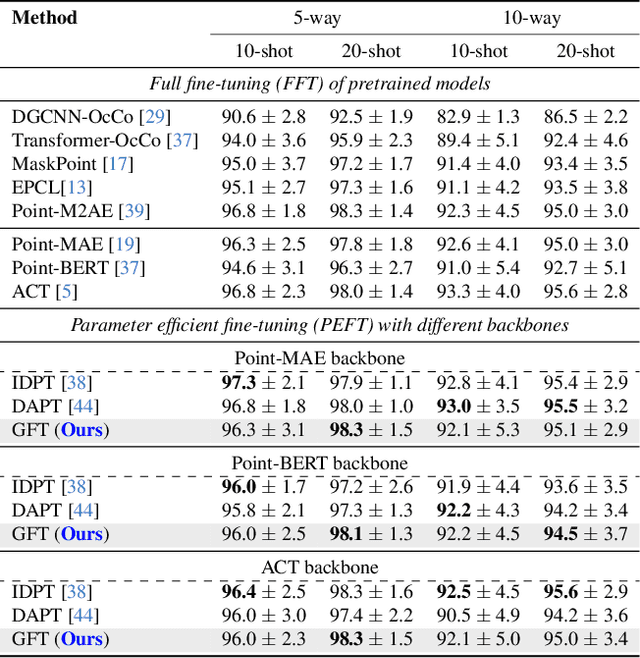
Parameter-efficient fine-tuning (PEFT) significantly reduces computational and memory costs by updating only a small subset of the model's parameters, enabling faster adaptation to new tasks with minimal loss in performance. Previous studies have introduced PEFTs tailored for point cloud data, as general approaches are suboptimal. To further reduce the number of trainable parameters, we propose a point-cloud-specific PEFT, termed Graph Features Tuning (GFT), which learns a dynamic graph from initial tokenized inputs of the transformer using a lightweight graph convolution network and passes these graph features to deeper layers via skip connections and efficient cross-attention modules. Extensive experiments on object classification and segmentation tasks show that GFT operates in the same domain, rivalling existing methods, while reducing the trainable parameters. Code is at https://github.com/manishdhakal/GFT.
Adversarial Robustness Analysis of Vision-Language Models in Medical Image Segmentation
May 05, 2025Adversarial attacks have been fairly explored for computer vision and vision-language models. However, the avenue of adversarial attack for the vision language segmentation models (VLSMs) is still under-explored, especially for medical image analysis. Thus, we have investigated the robustness of VLSMs against adversarial attacks for 2D medical images with different modalities with radiology, photography, and endoscopy. The main idea of this project was to assess the robustness of the fine-tuned VLSMs specially in the medical domain setting to address the high risk scenario. First, we have fine-tuned pre-trained VLSMs for medical image segmentation with adapters. Then, we have employed adversarial attacks -- projected gradient descent (PGD) and fast gradient sign method (FGSM) -- on that fine-tuned model to determine its robustness against adversaries. We have reported models' performance decline to analyze the adversaries' impact. The results exhibit significant drops in the DSC and IoU scores after the introduction of these adversaries. Furthermore, we also explored universal perturbation but were not able to find for the medical images. \footnote{https://github.com/anjilab/secure-private-ai}
TuneVLSeg: Prompt Tuning Benchmark for Vision-Language Segmentation Models
Oct 07, 2024



Vision-Language Models (VLMs) have shown impressive performance in vision tasks, but adapting them to new domains often requires expensive fine-tuning. Prompt tuning techniques, including textual, visual, and multimodal prompting, offer efficient alternatives by leveraging learnable prompts. However, their application to Vision-Language Segmentation Models (VLSMs) and evaluation under significant domain shifts remain unexplored. This work presents an open-source benchmarking framework, TuneVLSeg, to integrate various unimodal and multimodal prompt tuning techniques into VLSMs, making prompt tuning usable for downstream segmentation datasets with any number of classes. TuneVLSeg includes $6$ prompt tuning strategies on various prompt depths used in $2$ VLSMs totaling of $8$ different combinations. We test various prompt tuning on $8$ diverse medical datasets, including $3$ radiology datasets (breast tumor, echocardiograph, chest X-ray pathologies) and $5$ non-radiology datasets (polyp, ulcer, skin cancer), and two natural domain segmentation datasets. Our study found that textual prompt tuning struggles under significant domain shifts, from natural-domain images to medical data. Furthermore, visual prompt tuning, with fewer hyperparameters than multimodal prompt tuning, often achieves performance competitive to multimodal approaches, making it a valuable first attempt. Our work advances the understanding and applicability of different prompt-tuning techniques for robust domain-specific segmentation. The source code is available at https://github.com/naamiinepal/tunevlseg.
Automatic speech recognition for the Nepali language using CNN, bidirectional LSTM and ResNet
Jun 25, 2024



This paper presents an end-to-end deep learning model for Automatic Speech Recognition (ASR) that transcribes Nepali speech to text. The model was trained and tested on the OpenSLR (audio, text) dataset. The majority of the audio dataset have silent gaps at both ends which are clipped during dataset preprocessing for a more uniform mapping of audio frames and their corresponding texts. Mel Frequency Cepstral Coefficients (MFCCs) are used as audio features to feed into the model. The model having Bidirectional LSTM paired with ResNet and one-dimensional CNN produces the best results for this dataset out of all the models (neural networks with variations of LSTM, GRU, CNN, and ResNet) that have been trained so far. This novel model uses Connectionist Temporal Classification (CTC) function for loss calculation during training and CTC beam search decoding for predicting characters as the most likely sequence of Nepali text. On the test dataset, the character error rate (CER) of 17.06 percent has been achieved. The source code is available at: https://github.com/manishdhakal/ASR-Nepali-using-CNN-BiLSTM-ResNet.
* Accepted at 2022 International Conference on Inventive Computation Technologies (ICICT), IEEE
VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks
May 10, 2024Foundation Vision-Language Models (VLMs) trained using large-scale open-domain images and text pairs have recently been adapted to develop Vision-Language Segmentation Models (VLSMs) that allow providing text prompts during inference to guide image segmentation. If robust and powerful VLSMs can be built for medical images, it could aid medical professionals in many clinical tasks where they must spend substantial time delineating the target structure of interest. VLSMs for medical images resort to fine-tuning base VLM or VLSM pretrained on open-domain natural image datasets due to fewer annotated medical image datasets; this fine-tuning is resource-consuming and expensive as it usually requires updating all or a significant fraction of the pretrained parameters. Recently, lightweight blocks called adapters have been proposed in VLMs that keep the pretrained model frozen and only train adapters during fine-tuning, substantially reducing the computing resources required. We introduce a novel adapter, VLSM-Adapter, that can fine-tune pretrained vision-language segmentation models using transformer encoders. Our experiments in widely used CLIP-based segmentation models show that with only 3 million trainable parameters, the VLSM-Adapter outperforms state-of-the-art and is comparable to the upper bound end-to-end fine-tuning. The source code is available at: https://github.com/naamiinepal/vlsm-adapter.
Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
Sep 22, 2023Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at https://github.com/naamiinepal/synthetic-boost.
Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models
Aug 15, 2023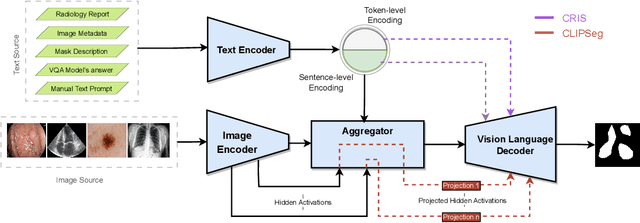



Medical Image Segmentation is crucial in various clinical applications within the medical domain. While state-of-the-art segmentation models have proven effective, integrating textual guidance to enhance visual features for this task remains an area with limited progress. Existing segmentation models that utilize textual guidance are primarily trained on open-domain images, raising concerns about their direct applicability in the medical domain without manual intervention or fine-tuning. To address these challenges, we propose using multimodal vision-language models for capturing semantic information from image descriptions and images, enabling the segmentation of diverse medical images. This study comprehensively evaluates existing vision language models across multiple datasets to assess their transferability from the open domain to the medical field. Furthermore, we introduce variations of image descriptions for previously unseen images in the dataset, revealing notable variations in model performance based on the generated prompts. Our findings highlight the distribution shift between the open-domain images and the medical domain and show that the segmentation models trained on open-domain images are not directly transferrable to the medical field. But their performance can be increased by finetuning them in the medical datasets. We report the zero-shot and finetuned segmentation performance of 4 Vision Language Models (VLMs) on 11 medical datasets using 9 types of prompts derived from 14 attributes.