 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Transfer Learning in Medical Image Segmentation using Vision-Language Models
Paper and Code
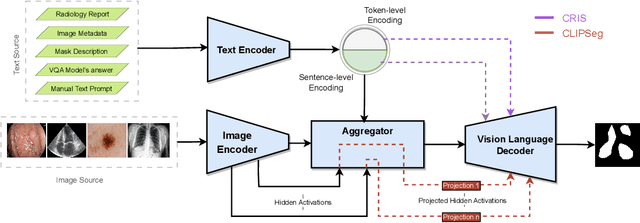



Medical Image Segmentation is crucial in various clinical applications within the medical domain. While state-of-the-art segmentation models have proven effective, integrating textual guidance to enhance visual features for this task remains an area with limited progress. Existing segmentation models that utilize textual guidance are primarily trained on open-domain images, raising concerns about their direct applicability in the medical domain without manual intervention or fine-tuning. To address these challenges, we propose using multimodal vision-language models for capturing semantic information from image descriptions and images, enabling the segmentation of diverse medical images. This study comprehensively evaluates existing vision language models across multiple datasets to assess their transferability from the open domain to the medical field. Furthermore, we introduce variations of image descriptions for previously unseen images in the dataset, revealing notable variations in model performance based on the generated prompts. Our findings highlight the distribution shift between the open-domain images and the medical domain and show that the segmentation models trained on open-domain images are not directly transferrable to the medical field. But their performance can be increased by finetuning them in the medical datasets. We report the zero-shot and finetuned segmentation performance of 4 Vision Language Models (VLMs) on 11 medical datasets using 9 types of prompts derived from 14 attributes.