 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic speech recognition for the Nepali language using CNN, bidirectional LSTM and ResNet
Jun 25, 2024



This paper presents an end-to-end deep learning model for Automatic Speech Recognition (ASR) that transcribes Nepali speech to text. The model was trained and tested on the OpenSLR (audio, text) dataset. The majority of the audio dataset have silent gaps at both ends which are clipped during dataset preprocessing for a more uniform mapping of audio frames and their corresponding texts. Mel Frequency Cepstral Coefficients (MFCCs) are used as audio features to feed into the model. The model having Bidirectional LSTM paired with ResNet and one-dimensional CNN produces the best results for this dataset out of all the models (neural networks with variations of LSTM, GRU, CNN, and ResNet) that have been trained so far. This novel model uses Connectionist Temporal Classification (CTC) function for loss calculation during training and CTC beam search decoding for predicting characters as the most likely sequence of Nepali text. On the test dataset, the character error rate (CER) of 17.06 percent has been achieved. The source code is available at: https://github.com/manishdhakal/ASR-Nepali-using-CNN-BiLSTM-ResNet.
* Accepted at 2022 International Conference on Inventive Computation Technologies (ICICT), IEEE
Can Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
Apr 28, 2024



Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
Contextual Spelling Correction with Language Model for Low-resource Setting
Apr 28, 2024



The task of Spell Correction(SC) in low-resource languages presents a significant challenge due to the availability of only a limited corpus of data and no annotated spelling correction datasets. To tackle these challenges a small-scale word-based transformer LM is trained to provide the SC model with contextual understanding. Further, the probabilistic error rules are extracted from the corpus in an unsupervised way to model the tendency of error happening(error model). Then the combination of LM and error model is used to develop the SC model through the well-known noisy channel framework. The effectiveness of this approach is demonstrated through experiments on the Nepali language where there is access to just an unprocessed corpus of textual data.
A Comparison of Semantic Similarity Methods for Maximum Human Interpretability
Oct 31, 2019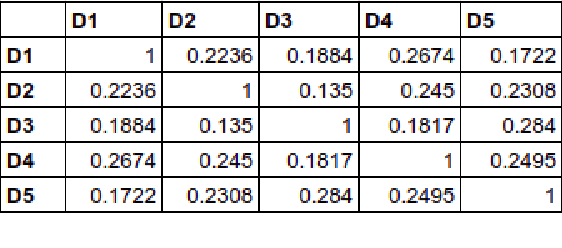


The inclusion of semantic information in any similarity measures improves the efficiency of the similarity measure and provides human interpretable results for further analysis. The similarity calculation method that focuses on features related to the text's words only, will give less accurate results. This paper presents three different methods that not only focus on the text's words but also incorporates semantic information of texts in their feature vector and computes semantic similarities. These methods are based on corpus-based and knowledge-based methods, which are: cosine similarity using tf-idf vectors, cosine similarity using word embedding and soft cosine similarity using word embedding. Among these three, cosine similarity using tf-idf vectors performed best in finding similarities between short news texts. The similar texts given by the method are easy to interpret and can be used directly in other information retrieval applications.
Word Sense Disambiguation using WSD specific Wordnet of Polysemy Words
Sep 10, 2014
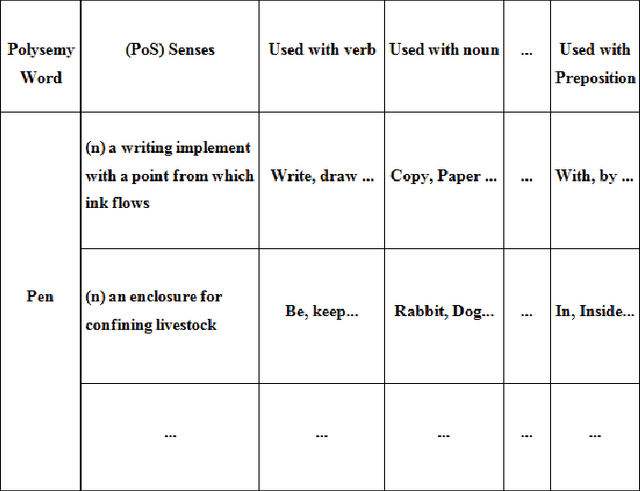
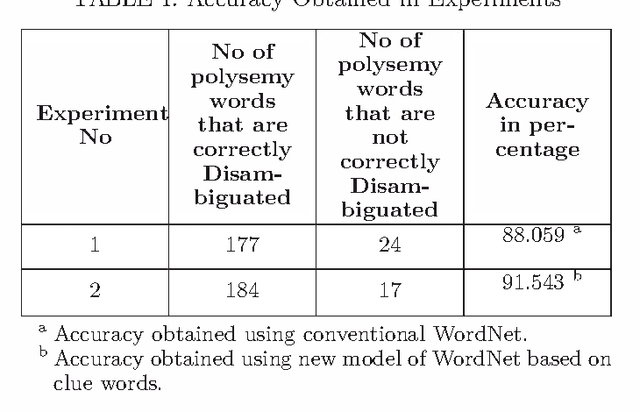
This paper presents a new model of WordNet that is used to disambiguate the correct sense of polysemy word based on the clue words. The related words for each sense of a polysemy word as well as single sense word are referred to as the clue words. The conventional WordNet organizes nouns, verbs, adjectives and adverbs together into sets of synonyms called synsets each expressing a different concept. In contrast to the structure of WordNet, we developed a new model of WordNet that organizes the different senses of polysemy words as well as the single sense words based on the clue words. These clue words for each sense of a polysemy word as well as for single sense word are used to disambiguate the correct meaning of the polysemy word in the given context using knowledge based Word Sense Disambiguation (WSD) algorithms. The clue word can be a noun, verb, adjective or adverb.