 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
Apr 28, 2024Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
Contextual Spelling Correction with Language Model for Low-resource Setting
Apr 28, 2024



The task of Spell Correction(SC) in low-resource languages presents a significant challenge due to the availability of only a limited corpus of data and no annotated spelling correction datasets. To tackle these challenges a small-scale word-based transformer LM is trained to provide the SC model with contextual understanding. Further, the probabilistic error rules are extracted from the corpus in an unsupervised way to model the tendency of error happening(error model). Then the combination of LM and error model is used to develop the SC model through the well-known noisy channel framework. The effectiveness of this approach is demonstrated through experiments on the Nepali language where there is access to just an unprocessed corpus of textual data.
Cross-modal Contrastive Learning with Asymmetric Co-attention Network for Video Moment Retrieval
Dec 12, 2023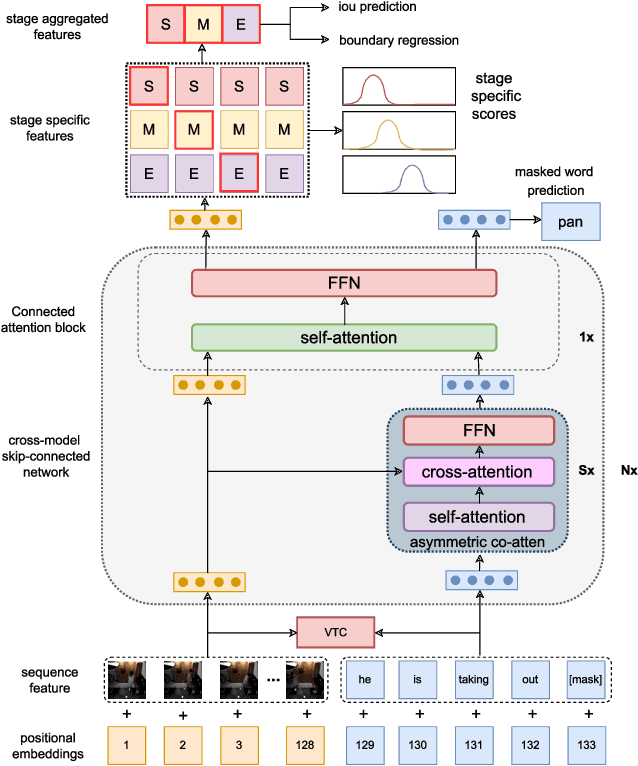
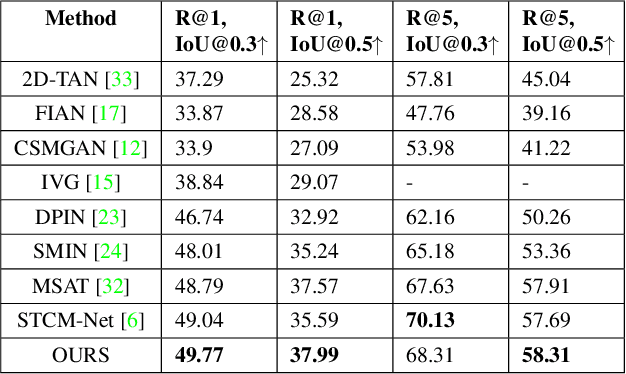
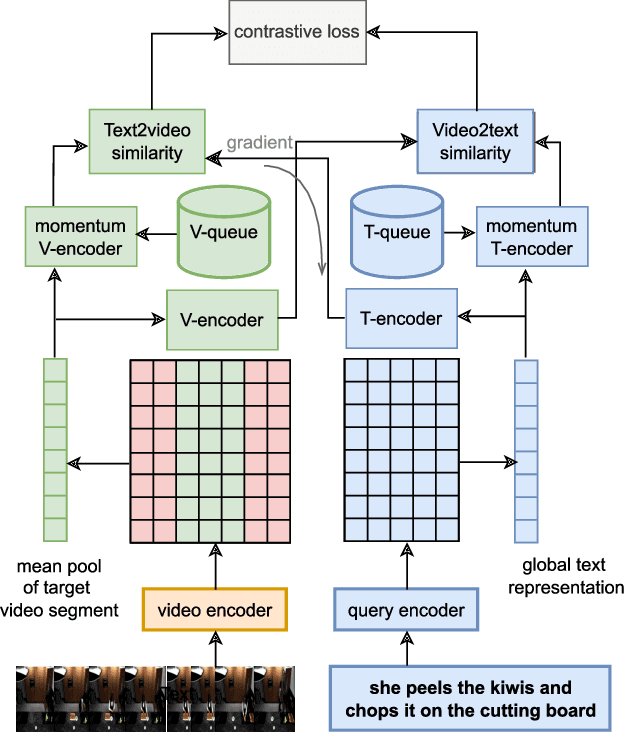
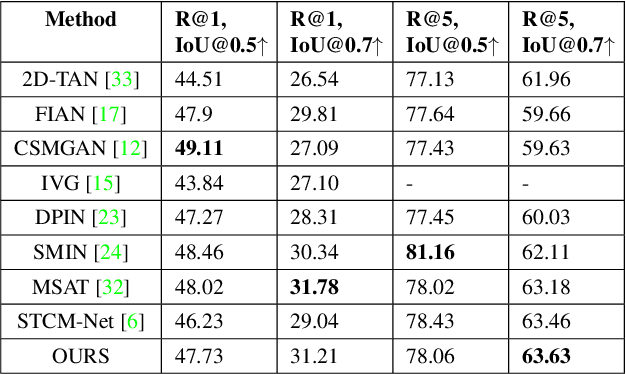
Video moment retrieval is a challenging task requiring fine-grained interactions between video and text modalities. Recent work in image-text pretraining has demonstrated that most existing pretrained models suffer from information asymmetry due to the difference in length between visual and textual sequences. We question whether the same problem also exists in the video-text domain with an auxiliary need to preserve both spatial and temporal information. Thus, we evaluate a recently proposed solution involving the addition of an asymmetric co-attention network for video grounding tasks. Additionally, we incorporate momentum contrastive loss for robust, discriminative representation learning in both modalities. We note that the integration of these supplementary modules yields better performance compared to state-of-the-art models on the TACoS dataset and comparable results on ActivityNet Captions, all while utilizing significantly fewer parameters with respect to baseline.