 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Assisted Cervical Cancer Screening for Cytology Samples in Developing Countries
Apr 29, 2025Cervical cancer remains a significant health challenge, with high incidence and mortality rates, particularly in transitioning countries. Conventional Liquid-Based Cytology(LBC) is a labor-intensive process, requires expert pathologists and is highly prone to errors, highlighting the need for more efficient screening methods. This paper introduces an innovative approach that integrates low-cost biological microscopes with our simple and efficient AI algorithms for automated whole-slide analysis. Our system uses a motorized microscope to capture cytology images, which are then processed through an AI pipeline involving image stitching, cell segmentation, and classification. We utilize the lightweight UNet-based model involving human-in-the-loop approach to train our segmentation model with minimal ROIs. CvT-based classification model, trained on the SIPaKMeD dataset, accurately categorizes five cell types. Our framework offers enhanced accuracy and efficiency in cervical cancer screening compared to various state-of-art methods, as demonstrated by different evaluation metrics.
Domain-adaptative Continual Learning for Low-resource Tasks: Evaluation on Nepali
Dec 18, 2024Continual learning has emerged as an important research direction due to the infeasibility of retraining large language models (LLMs) from scratch in the event of new data availability. Of great interest is the domain-adaptive pre-training (DAPT) paradigm, which focuses on continually training a pre-trained language model to adapt it to a domain it was not originally trained on. In this work, we evaluate the feasibility of DAPT in a low-resource setting, namely the Nepali language. We use synthetic data to continue training Llama 3 8B to adapt it to the Nepali language in a 4-bit QLoRA setting. We evaluate the adapted model on its performance, forgetting, and knowledge acquisition. We compare the base model and the final model on their Nepali generation abilities, their performance on popular benchmarks, and run case-studies to probe their linguistic knowledge in Nepali. We see some unsurprising forgetting in the final model, but also surprisingly find that increasing the number of shots during evaluation yields better percent increases in the final model (as high as 19.29% increase) compared to the base model (4.98%), suggesting latent retention. We also explore layer-head self-attention heatmaps to establish dependency resolution abilities of the final model in Nepali.
Cross-modal Contrastive Learning with Asymmetric Co-attention Network for Video Moment Retrieval
Dec 12, 2023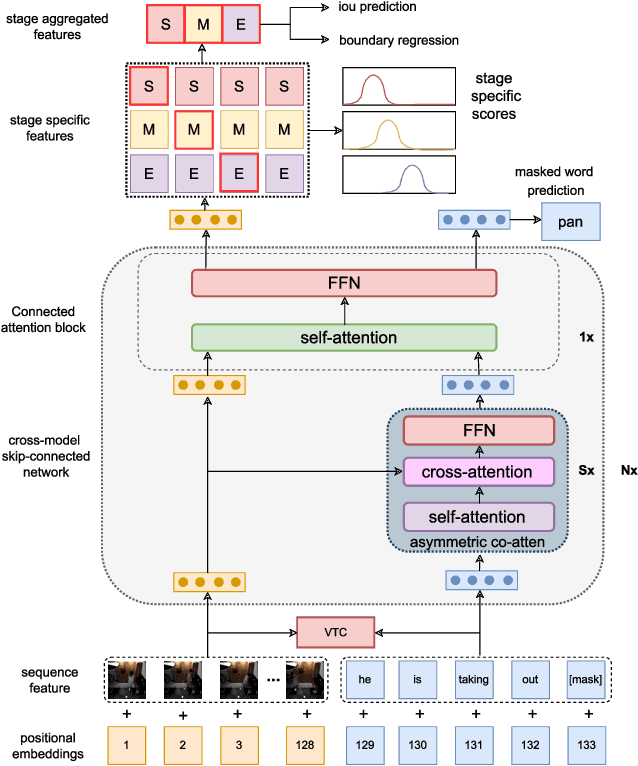
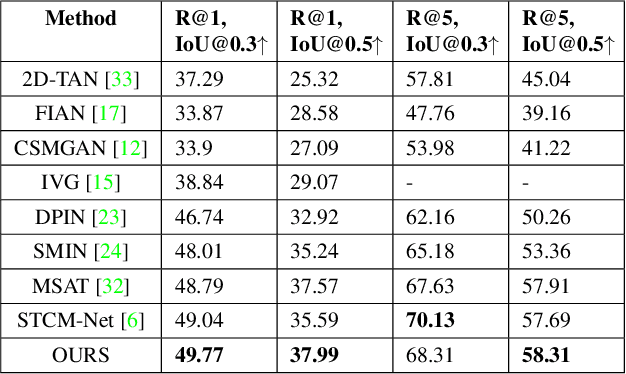
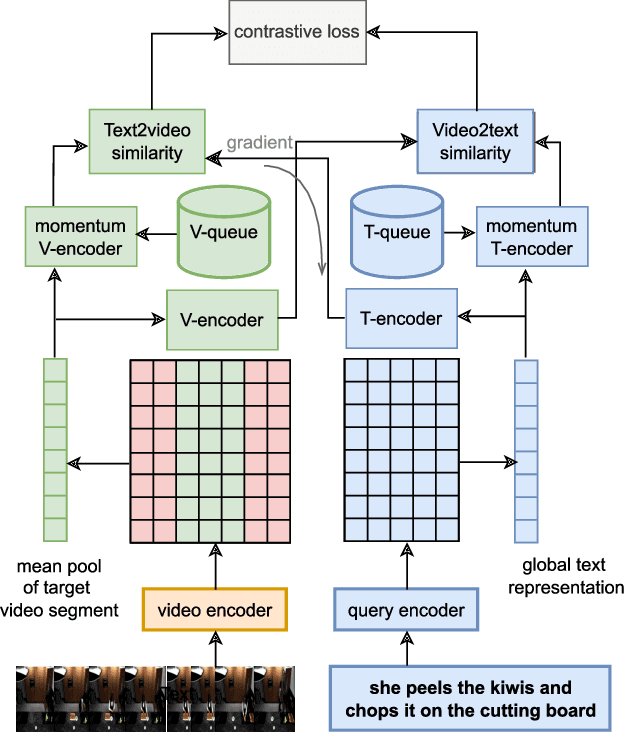
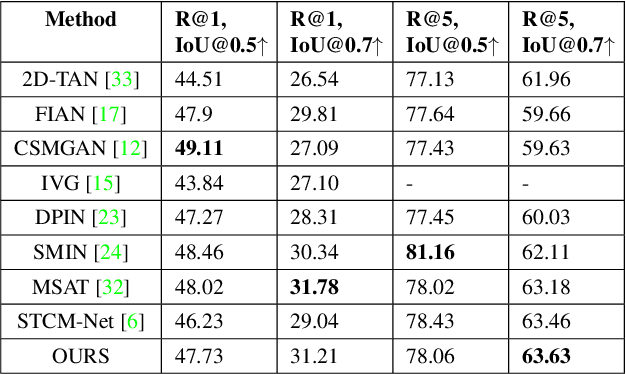
Video moment retrieval is a challenging task requiring fine-grained interactions between video and text modalities. Recent work in image-text pretraining has demonstrated that most existing pretrained models suffer from information asymmetry due to the difference in length between visual and textual sequences. We question whether the same problem also exists in the video-text domain with an auxiliary need to preserve both spatial and temporal information. Thus, we evaluate a recently proposed solution involving the addition of an asymmetric co-attention network for video grounding tasks. Additionally, we incorporate momentum contrastive loss for robust, discriminative representation learning in both modalities. We note that the integration of these supplementary modules yields better performance compared to state-of-the-art models on the TACoS dataset and comparable results on ActivityNet Captions, all while utilizing significantly fewer parameters with respect to baseline.
NEREL: A Russian Dataset with Nested Named Entities, Relations and Events
Sep 03, 2021
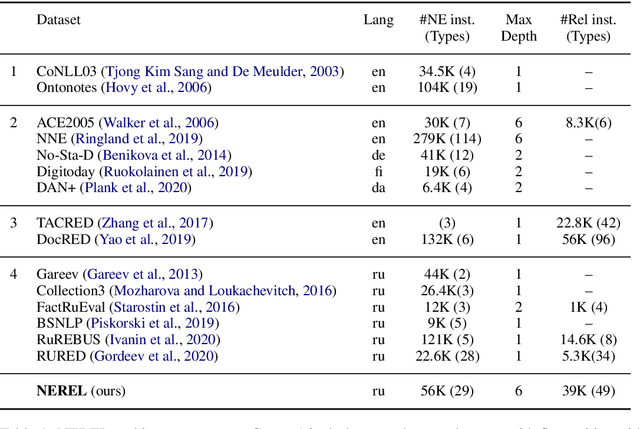
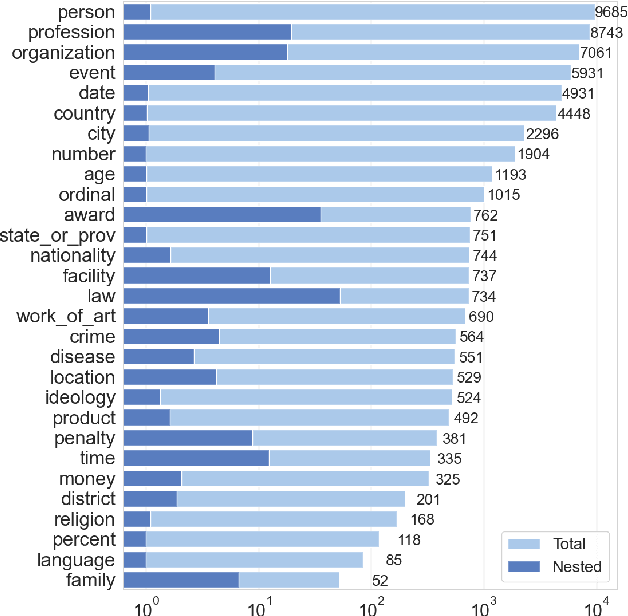
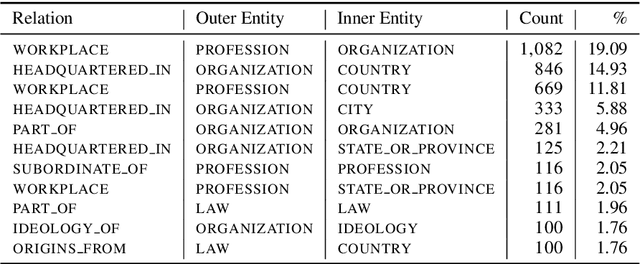
In this paper, we present NEREL, a Russian dataset for named entity recognition and relation extraction. NEREL is significantly larger than existing Russian datasets: to date it contains 56K annotated named entities and 39K annotated relations. Its important difference from previous datasets is annotation of nested named entities, as well as relations within nested entities and at the discourse level. NEREL can facilitate development of novel models that can extract relations between nested named entities, as well as relations on both sentence and document levels. NEREL also contains the annotation of events involving named entities and their roles in the events. The NEREL collection is available via https://github.com/nerel-ds/NEREL.
Visualising Argumentation Graphs with Graph Embeddings and t-SNE
Jul 01, 2021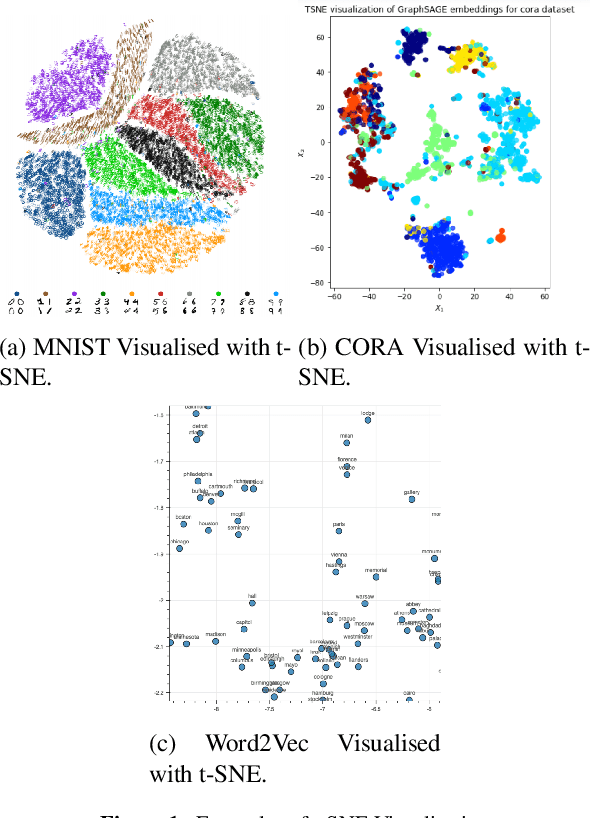

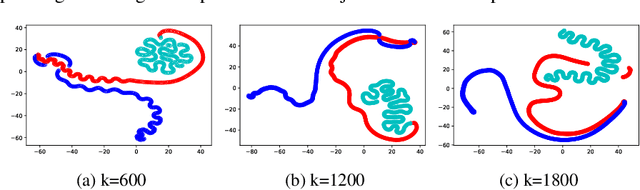
This paper applies t-SNE, a visualisation technique familiar from Deep Neural Network research to argumentation graphs by applying it to the output of graph embeddings generated using several different methods. It shows that such a visualisation approach can work for argumentation and show interesting structural properties of argumentation graphs, opening up paths for further research in the area.
FatNet: A Feature-attentive Network for 3D Point Cloud Processing
Apr 07, 2021

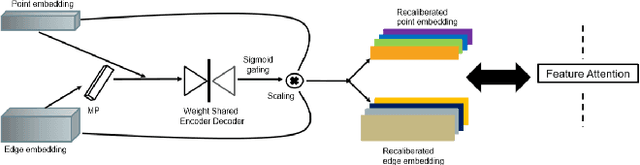
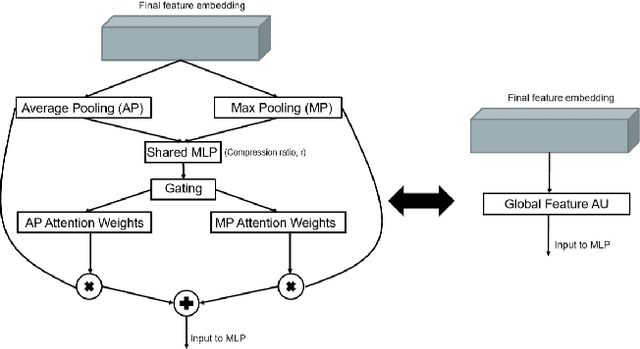
The application of deep learning to 3D point clouds is challenging due to its lack of order. Inspired by the point embeddings of PointNet and the edge embeddings of DGCNNs, we propose three improvements to the task of point cloud analysis. First, we introduce a novel feature-attentive neural network layer, a FAT layer, that combines both global point-based features and local edge-based features in order to generate better embeddings. Second, we find that applying the same attention mechanism across two different forms of feature map aggregation, max pooling and average pooling, gives better performance than either alone. Third, we observe that residual feature reuse in this setting propagates information more effectively between the layers, and makes the network easier to train. Our architecture achieves state-of-the-art results on the task of point cloud classification, as demonstrated on the ModelNet40 dataset, and an extremely competitive performance on the ShapeNet part segmentation challenge.
Divided We Stand: A Novel Residual Group Attention Mechanism for Medical Image Segmentation
Dec 04, 2019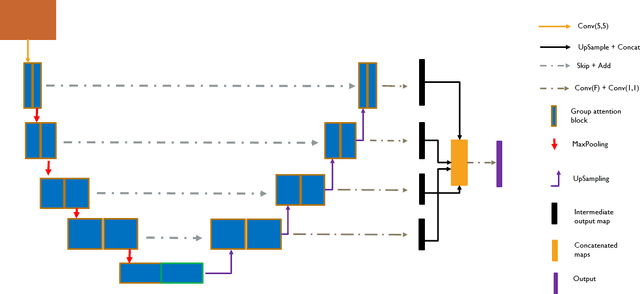
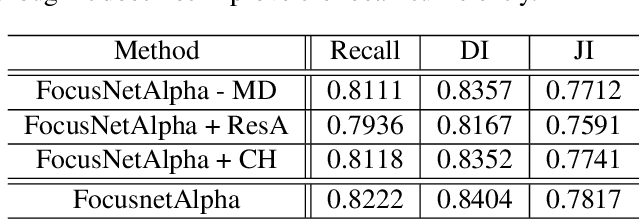

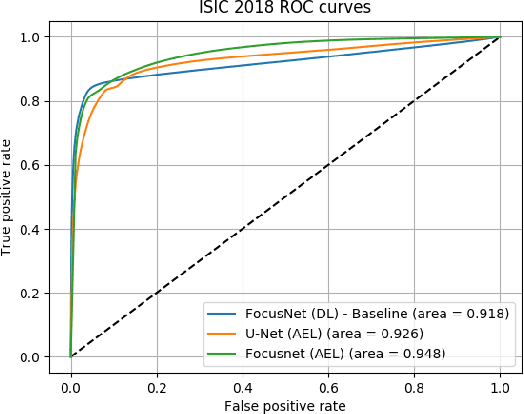
Given that convolutional neural networks extract features via learning convolution kernels, it makes sense to design better kernels which can in turn lead to better feature extraction. In this paper, we propose a new residual block for convolutional neural networks in the context of medical image segmentation. We combine attention mechanisms with group convolutions to create our group attention mechanism, which forms the fundamental building block of FocusNetAlpha - our convolutional autoencoder. We adapt a hybrid loss based on balanced cross entropy, tversky loss and the adaptive logarithmic loss to create a loss function that converges faster and more accurately to the minimum solution. On comparison with the different residual block variants, we observed a 5.6% increase in the IoU on the ISIC 2017 dataset over the basic residual block and a 1.3% increase over the resneXt group convolution block. Our results show that FocusNetAlpha achieves state-of-the-art results across all metrics for the ISIC 2018 melanoma segmentation, cell nuclei segmentation and the DRIVE retinal blood vessel segmentation datasets with fewer parameters and FLOPs. Our code and pre-trained models will be publicly available on GitHub to maximize reproducibility.
Penalizing small errors using an Adaptive Logarithmic Loss
Oct 22, 2019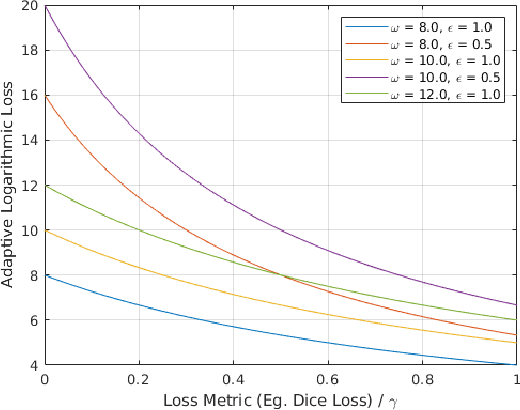
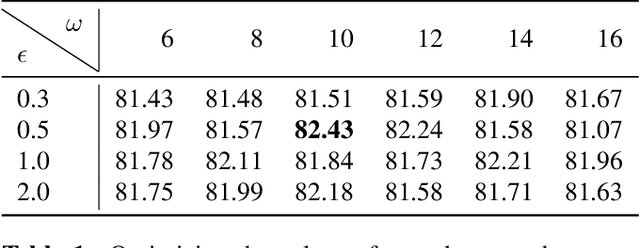
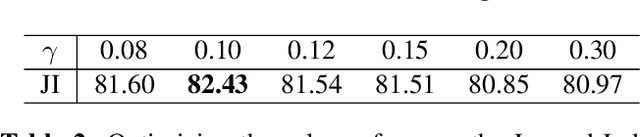
Loss functions are error metrics that quantify the difference between a prediction and its corresponding ground truth. Fundamentally, they define a functional landscape for traversal by gradient descent. Although numerous loss functions have been proposed to date in order to handle various machine learning problems, little attention has been given to enhancing these functions to better traverse the loss landscape. In this paper, we simultaneously and significantly mitigate two prominent problems in medical image segmentation namely: i) class imbalance between foreground and background pixels and ii) poor loss function convergence. To this end, we propose an adaptive logarithmic loss function. We compare this loss function with the existing state-of-the-art on the ISIC 2018 dataset, the nuclei segmentation dataset as well as the DRIVE retinal vessel segmentation dataset. We measure the performance of our methodology on benchmark metrics and demonstrate state-of-the-art performance. More generally, we show that our system can be used as a framework for better training of deep neural networks.
SAWNet: A Spatially Aware Deep Neural Network for 3D Point Cloud Processing
May 18, 2019
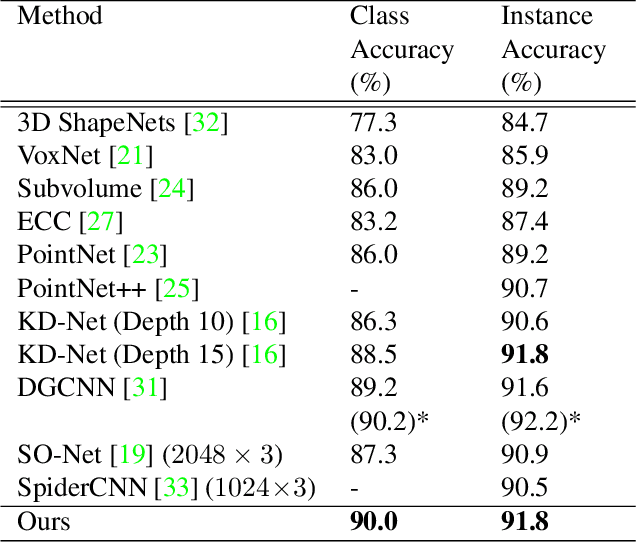
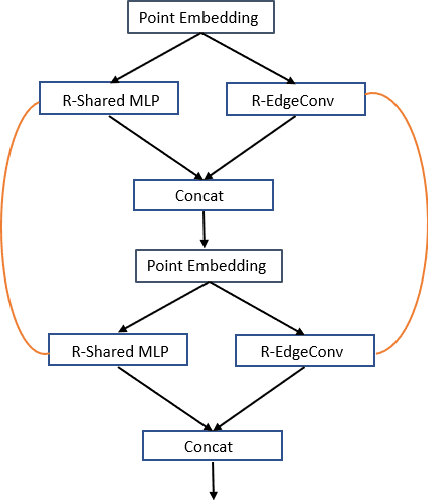
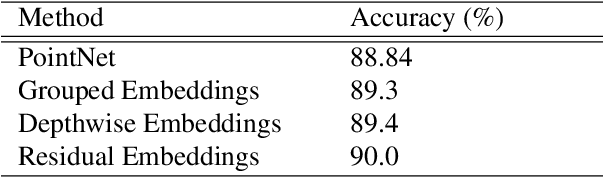
Deep neural networks have established themselves as the state-of-the-art methodology in almost all computer vision tasks to date. But their application to processing data lying on non-Euclidean domains is still a very active area of research. One such area is the analysis of point cloud data which poses a challenge due to its lack of order. Many recent techniques have been proposed, spearheaded by the PointNet architecture. These techniques use either global or local information from the point clouds to extract a latent representation for the points, which is then used for the task at hand (classification/segmentation). In our work, we introduce a neural network layer that combines both global and local information to produce better embeddings of these points. We enhance our architecture with residual connections, to pass information between the layers, which also makes the network easier to train. We achieve state-of-the-art results on the ModelNet40 dataset with our architecture, and our results are also highly competitive with the state-of-the-art on the ShapeNet part segmentation dataset and the indoor scene segmentation dataset. We plan to open source our pre-trained models on github to encourage the research community to test our networks on their data, or simply use them for benchmarking purposes.
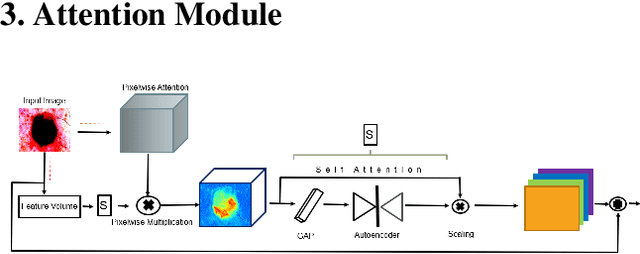
FocusNet: An attention-based Fully Convolutional Network for Medical Image Segmentation
Feb 08, 2019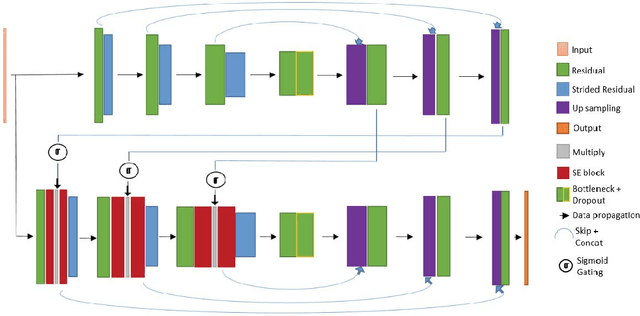
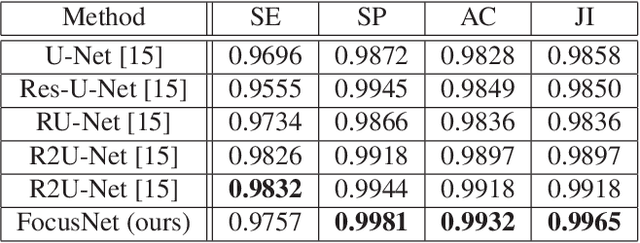
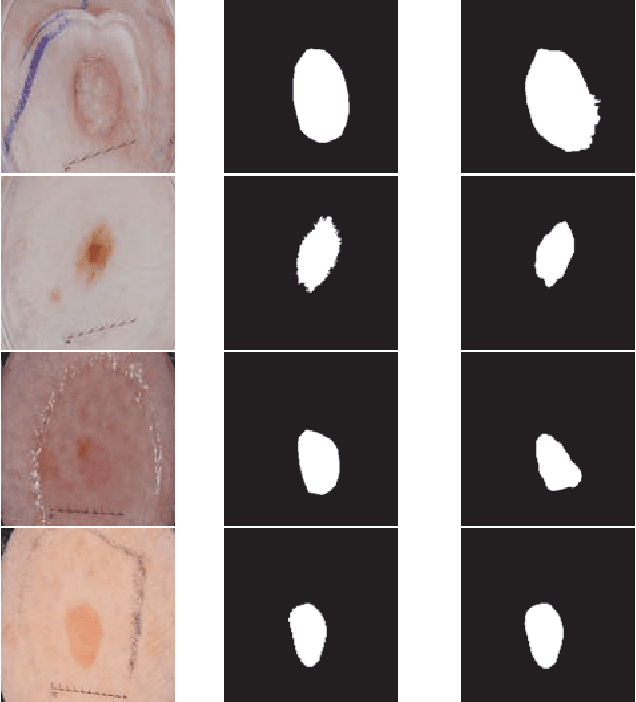
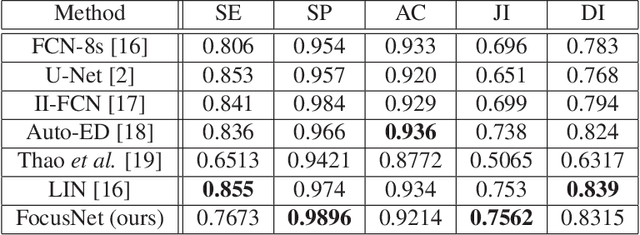
We propose a novel technique to incorporate attention within convolutional neural networks using feature maps generated by a separate convolutional autoencoder. Our attention architecture is well suited for incorporation with deep convolutional networks. We evaluate our model on benchmark segmentation datasets in skin cancer segmentation and lung lesion segmentation. Results show highly competitive performance when compared with U-Net and it's residual variant.