 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoWit-24: A Richly Annotated Dataset of Wordplay in News Headlines
Mar 03, 2025



We present KoWit-24, a dataset with fine-grained annotation of wordplay in 2,700 Russian news headlines. KoWit-24 annotations include the presence of wordplay, its type, wordplay anchors, and words/phrases the wordplay refers to. Unlike the majority of existing humor collections of canned jokes, KoWit-24 provides wordplay contexts -- each headline is accompanied by the news lead and summary. The most common type of wordplay in the dataset is the transformation of collocations, idioms, and named entities -- the mechanism that has been underrepresented in previous humor datasets. Our experiments with five LLMs show that there is ample room for improvement in wordplay detection and interpretation tasks. The dataset and evaluation scripts are available at https://github.com/Humor-Research/KoWit-24
How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
Feb 20, 2025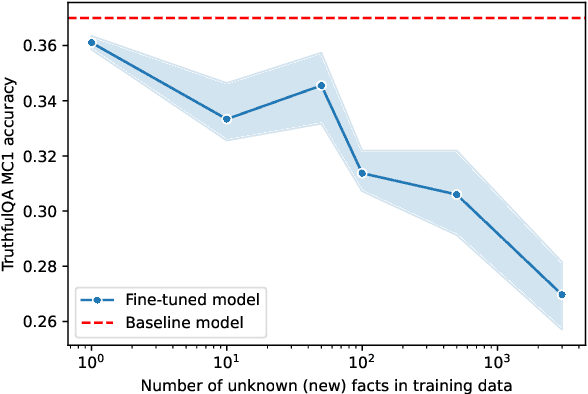

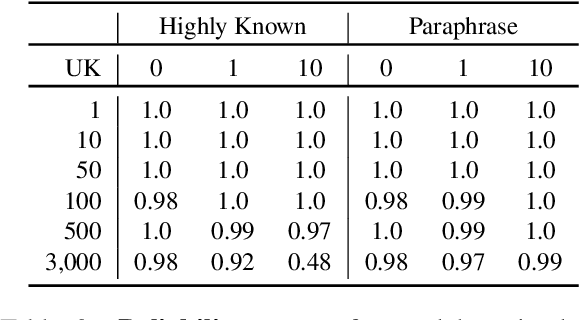
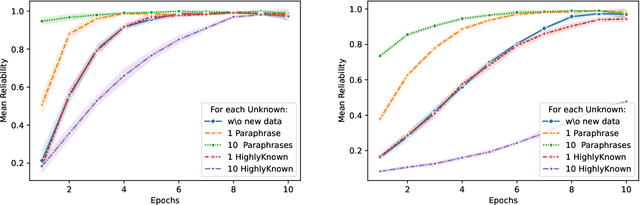
The performance of Large Language Models (LLMs) on many tasks is greatly limited by the knowledge learned during pre-training and stored in the model's parameters. Low-rank adaptation (LoRA) is a popular and efficient training technique for updating or domain-specific adaptation of LLMs. In this study, we investigate how new facts can be incorporated into the LLM using LoRA without compromising the previously learned knowledge. We fine-tuned Llama-3.1-8B-instruct using LoRA with varying amounts of new knowledge. Our experiments have shown that the best results are obtained when the training data contains a mixture of known and new facts. However, this approach is still potentially harmful because the model's performance on external question-answering benchmarks declines after such fine-tuning. When the training data is biased towards certain entities, the model tends to regress to few overrepresented answers. In addition, we found that the model becomes more confident and refuses to provide an answer in only few cases. These findings highlight the potential pitfalls of LoRA-based LLM updates and underscore the importance of training data composition and tuning parameters to balance new knowledge integration and general model capabilities.
Konstruktor: A Strong Baseline for Simple Knowledge Graph Question Answering
Sep 24, 2024While being one of the most popular question types, simple questions such as "Who is the author of Cinderella?", are still not completely solved. Surprisingly, even the most powerful modern Large Language Models are prone to errors when dealing with such questions, especially when dealing with rare entities. At the same time, as an answer may be one hop away from the question entity, one can try to develop a method that uses structured knowledge graphs (KGs) to answer such questions. In this paper, we introduce Konstruktor - an efficient and robust approach that breaks down the problem into three steps: (i) entity extraction and entity linking, (ii) relation prediction, and (iii) querying the knowledge graph. Our approach integrates language models and knowledge graphs, exploiting the power of the former and the interpretability of the latter. We experiment with two named entity recognition and entity linking methods and several relation detection techniques. We show that for relation detection, the most challenging step of the workflow, a combination of relation classification/generation and ranking outperforms other methods. We report Konstruktor's strong results on four datasets.
* 18 pages, 2 figures, 7 tables
KazQAD: Kazakh Open-Domain Question Answering Dataset
Apr 06, 2024



We introduce KazQAD -- a Kazakh open-domain question answering (ODQA) dataset -- that can be used in both reading comprehension and full ODQA settings, as well as for information retrieval experiments. KazQAD contains just under 6,000 unique questions with extracted short answers and nearly 12,000 passage-level relevance judgements. We use a combination of machine translation, Wikipedia search, and in-house manual annotation to ensure annotation efficiency and data quality. The questions come from two sources: translated items from the Natural Questions (NQ) dataset (only for training) and the original Kazakh Unified National Testing (UNT) exam (for development and testing). The accompanying text corpus contains more than 800,000 passages from the Kazakh Wikipedia. As a supplementary dataset, we release around 61,000 question-passage-answer triples from the NQ dataset that have been machine-translated into Kazakh. We develop baseline retrievers and readers that achieve reasonable scores in retrieval (NDCG@10 = 0.389 MRR = 0.382), reading comprehension (EM = 38.5 F1 = 54.2), and full ODQA (EM = 17.8 F1 = 28.7) settings. Nevertheless, these results are substantially lower than state-of-the-art results for English QA collections, and we think that there should still be ample room for improvement. We also show that the current OpenAI's ChatGPTv3.5 is not able to answer KazQAD test questions in the closed-book setting with acceptable quality. The dataset is freely available under the Creative Commons licence (CC BY-SA) at https://github.com/IS2AI/KazQAD.
Answer Candidate Type Selection: Text-to-Text Language Model for Closed Book Question Answering Meets Knowledge Graphs
Oct 10, 2023Pre-trained Text-to-Text Language Models (LMs), such as T5 or BART yield promising results in the Knowledge Graph Question Answering (KGQA) task. However, the capacity of the models is limited and the quality decreases for questions with less popular entities. In this paper, we present a novel approach which works on top of the pre-trained Text-to-Text QA system to address this issue. Our simple yet effective method performs filtering and re-ranking of generated candidates based on their types derived from Wikidata "instance_of" property.
Large Language Models Meet Knowledge Graphs to Answer Factoid Questions
Oct 03, 2023Recently, it has been shown that the incorporation of structured knowledge into Large Language Models significantly improves the results for a variety of NLP tasks. In this paper, we propose a method for exploring pre-trained Text-to-Text Language Models enriched with additional information from Knowledge Graphs for answering factoid questions. More specifically, we propose an algorithm for subgraphs extraction from a Knowledge Graph based on question entities and answer candidates. Then, we procure easily interpreted information with Transformer-based models through the linearization of the extracted subgraphs. Final re-ranking of the answer candidates with the extracted information boosts Hits@1 scores of the pre-trained text-to-text language models by 4-6%.
The Impact of Cross-Lingual Adjustment of Contextual Word Representations on Zero-Shot Transfer
Apr 13, 2022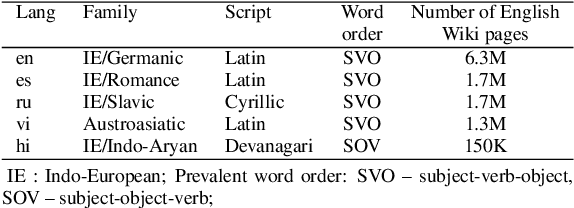
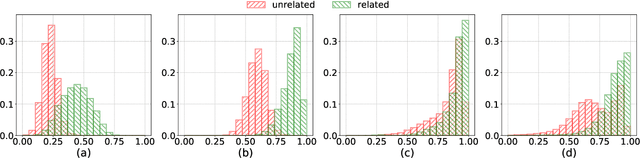

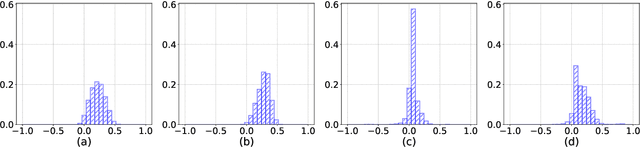
Large pre-trained multilingual models such as mBERT and XLM-R enabled effective cross-lingual zero-shot transfer in many NLP tasks. A cross-lingual adjustment of these models using a small parallel corpus can potentially further improve results. This is a more data efficient method compared to training a machine-translation system or a multi-lingual model from scratch using only parallel data. In this study, we experiment with zero-shot transfer of English models to four typologically different languages (Spanish, Russian, Vietnamese, and Hindi) and three NLP tasks (QA, NLI, and NER). We carry out a cross-lingual adjustment of an off-the-shelf mBERT model. We confirm prior finding that this adjustment makes embeddings of semantically similar words from different languages closer to each other, while keeping unrelated words apart. However, from the paired-differences histograms introduced in our work we can see that the adjustment only modestly affects the relative distances between related and unrelated words. In contrast, fine-tuning of mBERT on English data (for a specific task such as NER) draws embeddings of both related and unrelated words closer to each other. The cross-lingual adjustment of mBERT improves NLI in four languages and NER in two languages, while QA performance never improves and sometimes degrades. When we fine-tune a cross-lingual adjusted mBERT for a specific task (e.g., NLI), the cross-lingual adjustment of mBERT may still improve the separation between related and related words, but this works consistently only for the XNLI task. Our study contributes to a better understanding of cross-lingual transfer capabilities of large multilingual language models and of effectiveness of their cross-lingual adjustment in various NLP tasks.
NEREL: A Russian Dataset with Nested Named Entities, Relations and Events
Sep 03, 2021
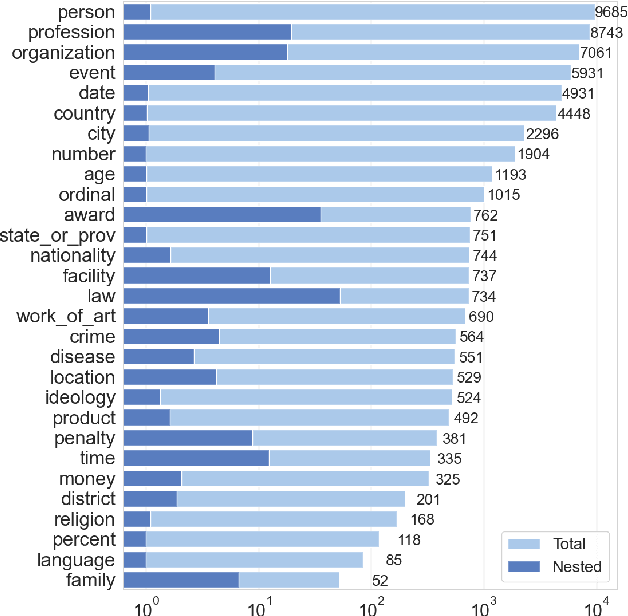
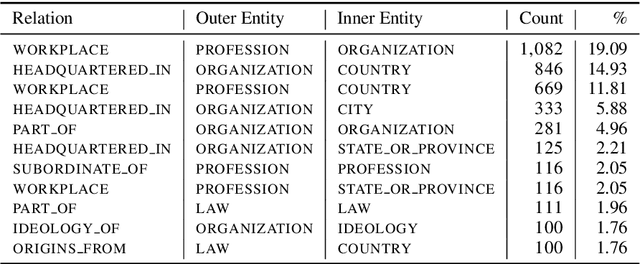
In this paper, we present NEREL, a Russian dataset for named entity recognition and relation extraction. NEREL is significantly larger than existing Russian datasets: to date it contains 56K annotated named entities and 39K annotated relations. Its important difference from previous datasets is annotation of nested named entities, as well as relations within nested entities and at the discourse level. NEREL can facilitate development of novel models that can extract relations between nested named entities, as well as relations on both sentence and document levels. NEREL also contains the annotation of events involving named entities and their roles in the events. The NEREL collection is available via https://github.com/nerel-ds/NEREL.
A Systematic Evaluation of Transfer Learning and Pseudo-labeling with BERT-based Ranking Models
Mar 11, 2021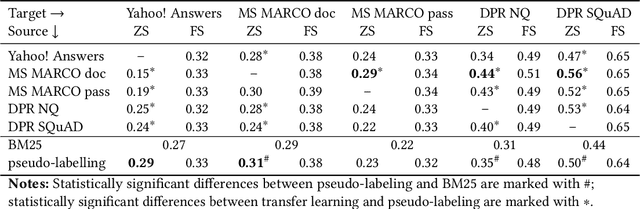

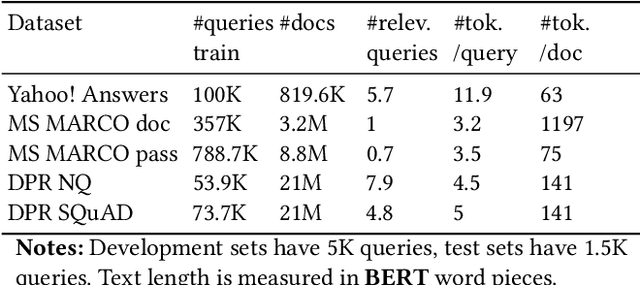
Due to high annotation costs, making the best use of existing human-created training data is an important research direction. We, therefore, carry out a systematic evaluation of transferability of BERT-based neural ranking models across five English datasets. Previous studies focused primarily on zero-shot and few-shot transfer from a large dataset to a dataset with a small number of queries. In contrast, each of our collections has a substantial number of queries, which enables a full-shot evaluation mode and improves reliability of our results. Furthermore, since source datasets licences often prohibit commercial use, we compare transfer learning to training on pseudo-labels generated by a BM25 scorer. We find that training on pseudo-labels -- possibly with subsequent fine-tuning using a modest number of annotated queries -- can produce a competitive or better model compared to transfer learning. However, there is a need to improve the stability and/or effectiveness of the few-shot training, which, in some cases, can degrade performance of a pretrained model.
RuBQ: A Russian Dataset for Question Answering over Wikidata
May 21, 2020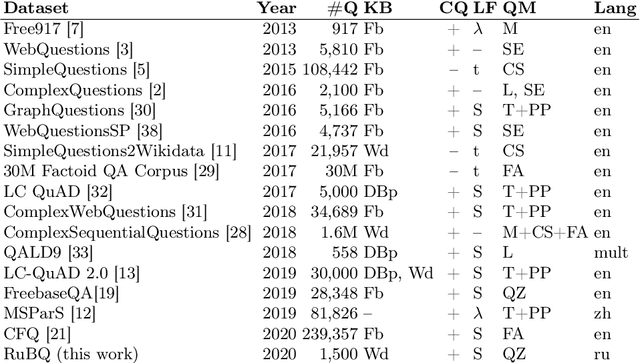
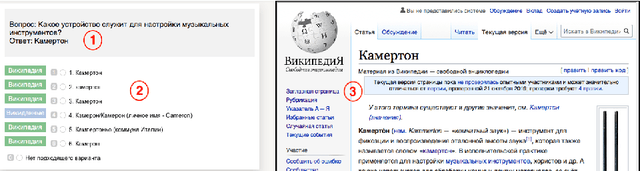


The paper presents RuBQ, the first Russian knowledge base question answering (KBQA) dataset. The high-quality dataset consists of 1,500 Russian questions of varying complexity, their English machine translations, SPARQL queries to Wikidata, reference answers, as well as a Wikidata sample of triples containing entities with Russian labels. The dataset creation started with a large collection of question-answer pairs from online quizzes. The data underwent automatic filtering, crowd-assisted entity linking, automatic generation of SPARQL queries, and their subsequent in-house verification.