 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Idioms in Sentences and Conversations Across High-, Medium-, and Low-Resource Languages
Jun 01, 2026Idiomatic expressions pose a major challenge for multilingual NLP because their meanings shift between figurative and literal usage, often requiring context for accurate interpretation. Prior work has focused on high-resource languages typically evaluates isolated idiom-meaning questions, overlooking realistic discourse. We introduce MIDI, a multilingual idiom dataset spanning 3 high-, 3 medium-, and 12 low-resource languages, curated by native speakers. Unlike previous datasets, MIDI provides idioms embedded in both sentence-level and conversational contexts, capturing both literal and figurative readings. Benchmarking state-of-the-art models shows that idiom comprehension degrades in low-resource languages and that, in all resource tiers, literal interpretations are substantially harder than figurative ones. Conversational context improves performance but does not eliminate these disparities. Through controlled tests and interventions on hidden representations, we further separate memorization from reasoning, exposing core limitations of current models.
Leveraging LLM Parametric Knowledge for Fact Checking without Retrieval
Mar 05, 2026Trustworthiness is a core research challenge for agentic AI systems built on Large Language Models (LLMs). To enhance trust, natural language claims from diverse sources, including human-written text, web content, and model outputs, are commonly checked for factuality by retrieving external knowledge and using an LLM to verify the faithfulness of claims to the retrieved evidence. As a result, such methods are constrained by retrieval errors and external data availability, while leaving the models intrinsic fact-verification capabilities largely unused. We propose the task of fact-checking without retrieval, focusing on the verification of arbitrary natural language claims, independent of their source. To study this setting, we introduce a comprehensive evaluation framework focused on generalization, testing robustness to (i) long-tail knowledge, (ii) variation in claim sources, (iii) multilinguality, and (iv) long-form generation. Across 9 datasets, 18 methods and 3 models, our experiments indicate that logit-based approaches often underperform compared to those that leverage internal model representations. Building on this finding, we introduce INTRA, a method that exploits interactions between internal representations and achieves state-of-the-art performance with strong generalization. More broadly, our work establishes fact-checking without retrieval as a promising research direction that can complement retrieval-based frameworks, improve scalability, and enable the use of such systems as reward signals during training or as components integrated into the generation process.
Do I look like a `cat.n.01` to you? A Taxonomy Image Generation Benchmark
Mar 13, 2025This paper explores the feasibility of using text-to-image models in a zero-shot setup to generate images for taxonomy concepts. While text-based methods for taxonomy enrichment are well-established, the potential of the visual dimension remains unexplored. To address this, we propose a comprehensive benchmark for Taxonomy Image Generation that assesses models' abilities to understand taxonomy concepts and generate relevant, high-quality images. The benchmark includes common-sense and randomly sampled WordNet concepts, alongside the LLM generated predictions. The 12 models are evaluated using 9 novel taxonomy-related text-to-image metrics and human feedback. Moreover, we pioneer the use of pairwise evaluation with GPT-4 feedback for image generation. Experimental results show that the ranking of models differs significantly from standard T2I tasks. Playground-v2 and FLUX consistently outperform across metrics and subsets and the retrieval-based approach performs poorly. These findings highlight the potential for automating the curation of structured data resources.
Self-Taught Self-Correction for Small Language Models
Mar 11, 2025Although large language models (LLMs) have achieved remarkable performance across various tasks, they remain prone to errors. A key challenge is enabling them to self-correct. While prior research has relied on external tools or large proprietary models, this work explores self-correction in small language models (SLMs) through iterative fine-tuning using solely self-generated data. We introduce the Self-Taught Self-Correction (STaSC) algorithm, which incorporates multiple algorithmic design choices. Experimental results on a question-answering task demonstrate that STaSC effectively learns self-correction, leading to significant performance improvements. Our analysis further provides insights into the mechanisms of self-correction and the impact of different design choices on learning dynamics and overall performance. To support future research, we release our user-friendly codebase and lightweight models.
Argument-Based Comparative Question Answering Evaluation Benchmark
Feb 20, 2025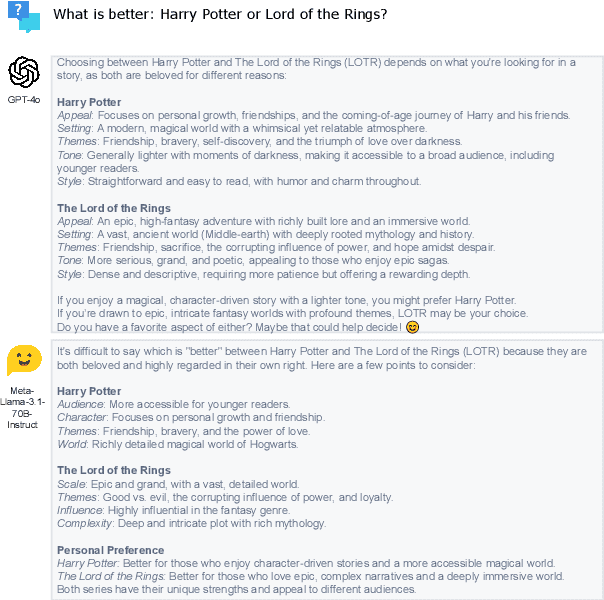

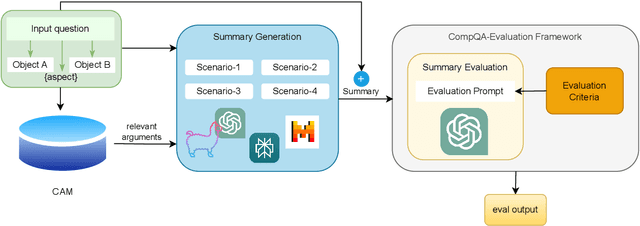
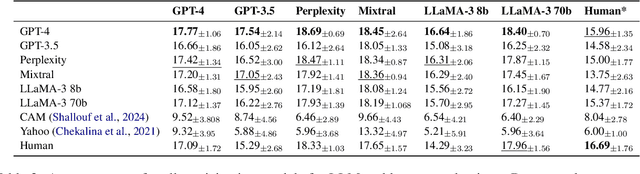
In this paper, we aim to solve the problems standing in the way of automatic comparative question answering. To this end, we propose an evaluation framework to assess the quality of comparative question answering summaries. We formulate 15 criteria for assessing comparative answers created using manual annotation and annotation from 6 large language models and two comparative question asnwering datasets. We perform our tests using several LLMs and manual annotation under different settings and demonstrate the constituency of both evaluations. Our results demonstrate that the Llama-3 70B Instruct model demonstrates the best results for summary evaluation, while GPT-4 is the best for answering comparative questions. All used data, code, and evaluation results are publicly available\footnote{\url{https://anonymous.4open.science/r/cqa-evaluation-benchmark-4561/README.md}}.
Wiping out the limitations of Large Language Models -- A Taxonomy for Retrieval Augmented Generation
Aug 07, 2024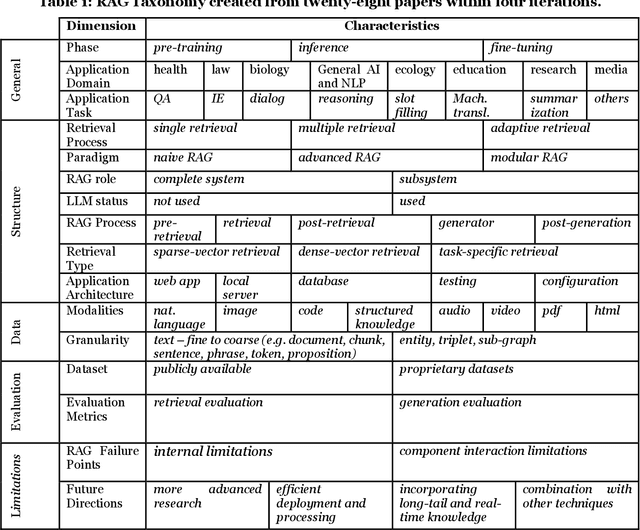
Current research on RAGs is distributed across various disciplines, and since the technology is evolving very quickly, its unit of analysis is mostly on technological innovations, rather than applications in business contexts. Thus, in this research, we aim to create a taxonomy to conceptualize a comprehensive overview of the constituting characteristics that define RAG applications, facilitating the adoption of this technology in the IS community. To the best of our knowledge, no RAG application taxonomies have been developed so far. We describe our methodology for developing the taxonomy, which includes the criteria for selecting papers, an explanation of our rationale for employing a Large Language Model (LLM)-supported approach to extract and identify initial characteristics, and a concise overview of our systematic process for conceptualizing the taxonomy. Our systematic taxonomy development process includes four iterative phases designed to refine and enhance our understanding and presentation of RAG's core dimensions. We have developed a total of five meta-dimensions and sixteen dimensions to comprehensively capture the concept of Retrieval-Augmented Generation (RAG) applications. When discussing our findings, we also detail the specific research areas and pose key research questions to guide future information system researchers as they explore the emerging topics of RAG systems.
Low-Resource Machine Translation through the Lens of Personalized Federated Learning
Jun 18, 2024



We present a new approach based on the Personalized Federated Learning algorithm MeritFed that can be applied to Natural Language Tasks with heterogeneous data. We evaluate it on the Low-Resource Machine Translation task, using the dataset from the Large-Scale Multilingual Machine Translation Shared Task (Small Track #2) and the subset of Sami languages from the multilingual benchmark for Finno-Ugric languages. In addition to its effectiveness, MeritFed is also highly interpretable, as it can be applied to track the impact of each language used for training. Our analysis reveals that target dataset size affects weight distribution across auxiliary languages, that unrelated languages do not interfere with the training, and auxiliary optimizer parameters have minimal impact. Our approach is easy to apply with a few lines of code, and we provide scripts for reproducing the experiments at https://github.com/VityaVitalich/MeritFed
TaxoLLaMA: WordNet-based Model for Solving Multiple Lexical Sematic Tasks
Mar 14, 2024In this paper, we explore the capabilities of LLMs in capturing lexical-semantic knowledge from WordNet on the example of the LLaMA-2-7b model and test it on multiple lexical semantic tasks. As the outcome of our experiments, we present TaxoLLaMA, the everything-in-one model, lightweight due to 4-bit quantization and LoRA. It achieves 11 SotA results, 4 top-2 results out of 16 tasks for the Taxonomy Enrichment, Hypernym Discovery, Taxonomy Construction, and Lexical Entailment tasks. Moreover, it demonstrates very strong zero-shot performance on Lexical Entailment and Taxonomy Construction with no fine-tuning. We also explore its hidden multilingual and domain adaptation capabilities with a little tuning or few-shot learning. All datasets, code, and model are available online at https://github.com/VityaVitalich/TaxoLLaMA
Large Language Models Meet Knowledge Graphs to Answer Factoid Questions
Oct 03, 2023Recently, it has been shown that the incorporation of structured knowledge into Large Language Models significantly improves the results for a variety of NLP tasks. In this paper, we propose a method for exploring pre-trained Text-to-Text Language Models enriched with additional information from Knowledge Graphs for answering factoid questions. More specifically, we propose an algorithm for subgraphs extraction from a Knowledge Graph based on question entities and answer candidates. Then, we procure easily interpreted information with Transformer-based models through the linearization of the extracted subgraphs. Final re-ranking of the answer candidates with the extracted information boosts Hits@1 scores of the pre-trained text-to-text language models by 4-6%.
RuArg-2022: Argument Mining Evaluation
Jun 18, 2022
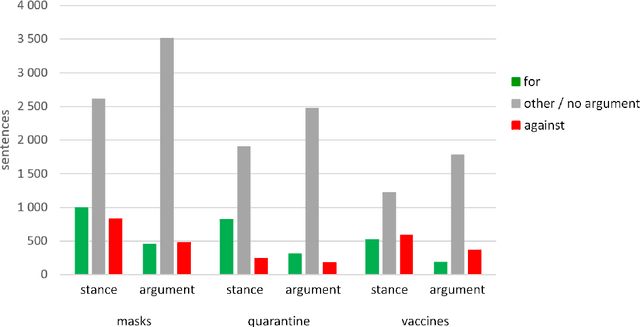
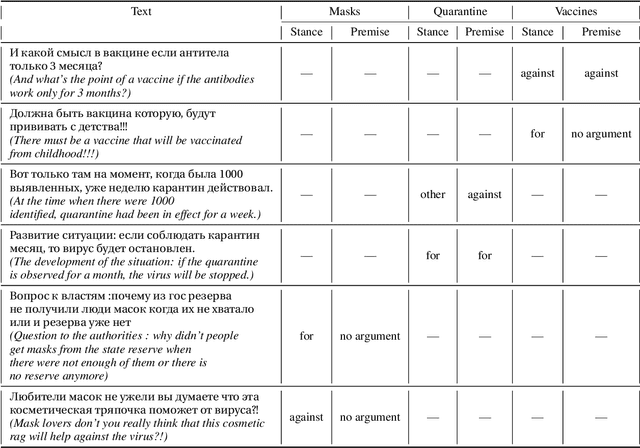
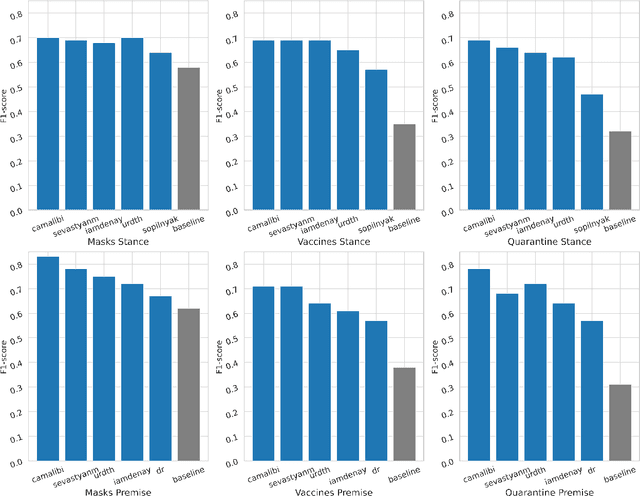
Argumentation analysis is a field of computational linguistics that studies methods for extracting arguments from texts and the relationships between them, as well as building argumentation structure of texts. This paper is a report of the organizers on the first competition of argumentation analysis systems dealing with Russian language texts within the framework of the Dialogue conference. During the competition, the participants were offered two tasks: stance detection and argument classification. A corpus containing 9,550 sentences (comments on social media posts) on three topics related to the COVID-19 pandemic (vaccination, quarantine, and wearing masks) was prepared, annotated, and used for training and testing. The system that won the first place in both tasks used the NLI (Natural Language Inference) variant of the BERT architecture, automatic translation into English to apply a specialized BERT model, retrained on Twitter posts discussing COVID-19, as well as additional masking of target entities. This system showed the following results: for the stance detection task an F1-score of 0.6968, for the argument classification task an F1-score of 0.7404. We hope that the prepared dataset and baselines will help to foster further research on argument mining for the Russian language.