 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikipedia-based Datasets in Russian Information Retrieval Benchmark RusBEIR
Nov 07, 2025In this paper, we present a novel series of Russian information retrieval datasets constructed from the "Did you know..." section of Russian Wikipedia. Our datasets support a range of retrieval tasks, including fact-checking, retrieval-augmented generation, and full-document retrieval, by leveraging interesting facts and their referenced Wikipedia articles annotated at the sentence level with graded relevance. We describe the methodology for dataset creation that enables the expansion of existing Russian Information Retrieval (IR) resources. Through extensive experiments, we extend the RusBEIR research by comparing lexical retrieval models, such as BM25, with state-of-the-art neural architectures fine-tuned for Russian, as well as multilingual models. Results of our experiments show that lexical methods tend to outperform neural models on full-document retrieval, while neural approaches better capture lexical semantics in shorter texts, such as in fact-checking or fine-grained retrieval. Using our newly created datasets, we also analyze the impact of document length on retrieval performance and demonstrate that combining retrieval with neural reranking consistently improves results. Our contribution expands the resources available for Russian information retrieval research and highlights the importance of accurate evaluation of retrieval models to achieve optimal performance. All datasets are publicly available at HuggingFace. To facilitate reproducibility and future research, we also release the full implementation on GitHub.
Iterative Layer-wise Distillation for Efficient Compression of Large Language Models
Nov 07, 2025This work investigates distillation methods for large language models (LLMs) with the goal of developing compact models that preserve high performance. Several existing approaches are reviewed, with a discussion of their respective strengths and limitations. An improved method based on the ShortGPT approach has been developed, building upon the idea of incorporating iterative evaluation of layer importance. At each step, importance is assessed by measuring performance degradation when individual layers are removed, using a set of representative datasets. This process is combined with further training using a joint loss function based on KL divergence and mean squared error. Experiments on the Qwen2.5-3B model show that the number of layers can be reduced from 36 to 28 (resulting in a 2.47 billion parameter model) with only a 9.7% quality loss, and to 24 layers with an 18% loss. The findings suggest that the middle transformer layers contribute less to inference, underscoring the potential of the proposed method for creating efficient models. The results demonstrate the effectiveness of iterative distillation and fine-tuning, making the approach suitable for deployment in resource-limited settings.
Building Russian Benchmark for Evaluation of Information Retrieval Models
Apr 17, 2025



We introduce RusBEIR, a comprehensive benchmark designed for zero-shot evaluation of information retrieval (IR) models in the Russian language. Comprising 17 datasets from various domains, it integrates adapted, translated, and newly created datasets, enabling systematic comparison of lexical and neural models. Our study highlights the importance of preprocessing for lexical models in morphologically rich languages and confirms BM25 as a strong baseline for full-document retrieval. Neural models, such as mE5-large and BGE-M3, demonstrate superior performance on most datasets, but face challenges with long-document retrieval due to input size constraints. RusBEIR offers a unified, open-source framework that promotes research in Russian-language information retrieval.
RuOpinionNE-2024: Extraction of Opinion Tuples from Russian News Texts
Apr 09, 2025In this paper, we introduce the Dialogue Evaluation shared task on extraction of structured opinions from Russian news texts. The task of the contest is to extract opinion tuples for a given sentence; the tuples are composed of a sentiment holder, its target, an expression and sentiment from the holder to the target. In total, the task received more than 100 submissions. The participants experimented mainly with large language models in zero-shot, few-shot and fine-tuning formats. The best result on the test set was obtained with fine-tuning of a large language model. We also compared 30 prompts and 11 open source language models with 3-32 billion parameters in the 1-shot and 10-shot settings and found the best models and prompts.
Facilitating large language model Russian adaptation with Learned Embedding Propagation
Dec 30, 2024Rapid advancements of large language model (LLM) technologies led to the introduction of powerful open-source instruction-tuned LLMs that have the same text generation quality as the state-of-the-art counterparts such as GPT-4. While the emergence of such models accelerates the adoption of LLM technologies in sensitive-information environments the authors of such models don not disclose the training data necessary for replication of the results thus making the achievements model-exclusive. Since those open-source models are also multilingual this in turn reduces the benefits of training a language specific LLMs as improved inference computation efficiency becomes the only guaranteed advantage of such costly procedure. More cost-efficient options such as vocabulary extension and subsequent continued pre-training are also inhibited by the lack of access to high-quality instruction-tuning data since it is the major factor behind the resulting LLM task-solving capabilities. To address the limitations and cut the costs of the language adaptation pipeline we propose Learned Embedding Propagation (LEP). Unlike existing approaches our method has lower training data size requirements due to minimal impact on existing LLM knowledge which we reinforce using novel ad-hoc embedding propagation procedure that allows to skip the instruction-tuning step and instead implant the new language knowledge directly into any existing instruct-tuned variant. We evaluated four Russian vocabulary adaptations for LLaMa-3-8B and Mistral-7B, showing that LEP is competitive with traditional instruction-tuning methods, achieving performance comparable to OpenChat 3.5 and LLaMa-3-8B-Instruct, with further improvements via self-calibration and continued tuning enhancing task-solving capabilities.
Exploring Prompt-Based Methods for Zero-Shot Hypernym Prediction with Large Language Models
Jan 09, 2024This article investigates a zero-shot approach to hypernymy prediction using large language models (LLMs). The study employs a method based on text probability calculation, applying it to various generated prompts. The experiments demonstrate a strong correlation between the effectiveness of language model prompts and classic patterns, indicating that preliminary prompt selection can be carried out using smaller models before moving to larger ones. We also explore prompts for predicting co-hyponyms and improving hypernymy predictions by augmenting prompts with additional information through automatically identified co-hyponyms. An iterative approach is developed for predicting higher-level concepts, which further improves the quality on the BLESS dataset (MAP = 0.8).
Impact of Tokenization on LLaMa Russian Adaptation
Dec 05, 2023Latest instruction-tuned large language models (LLM) show great results on various tasks, however, they often face performance degradation for non-English input. There is evidence that the reason lies in inefficient tokenization caused by low language representation in pre-training data which hinders the comprehension of non-English instructions, limiting the potential of target language instruction-tuning. In this work we investigate the possibility of addressing the issue with vocabulary substitution in the context of LLaMa Russian language adaptation. We explore three variants of vocabulary adaptation and test their performance on Saiga instruction-tuning and fine-tuning on Russian Super Glue benchmark. The results of automatic evaluation show that vocabulary substitution not only improves the model's quality in Russian but also accelerates fine-tuning (35%) and inference (up to 60%) while reducing memory consumption. Additional human evaluation of the instruction-tuned models demonstrates that models with Russian-adapted vocabulary generate answers with higher user preference than the original Saiga-LLaMa model.
Taxonomy Enrichment with Text and Graph Vector Representations
Jan 21, 2022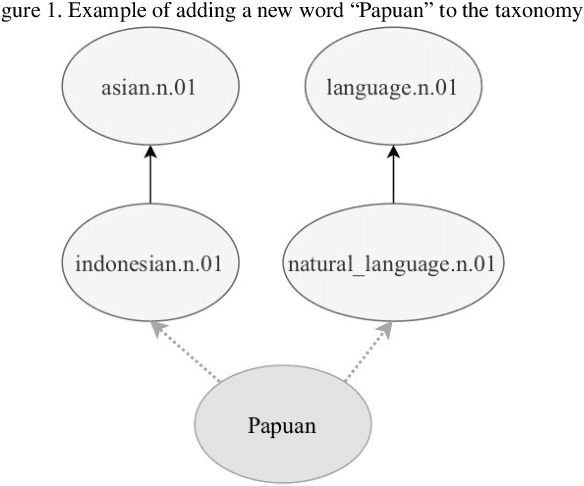
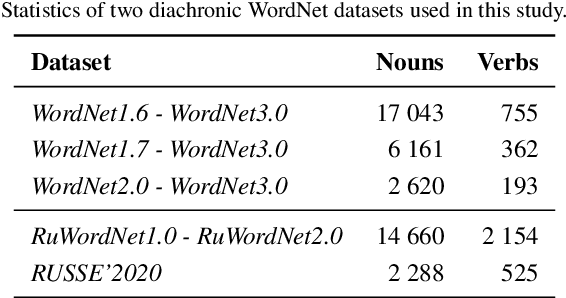
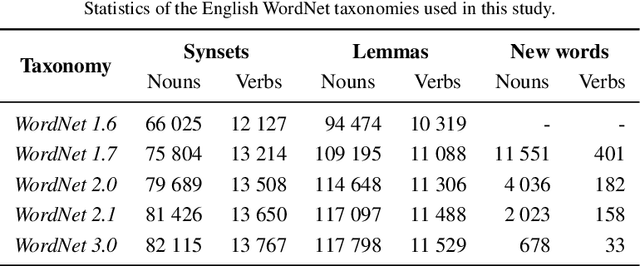
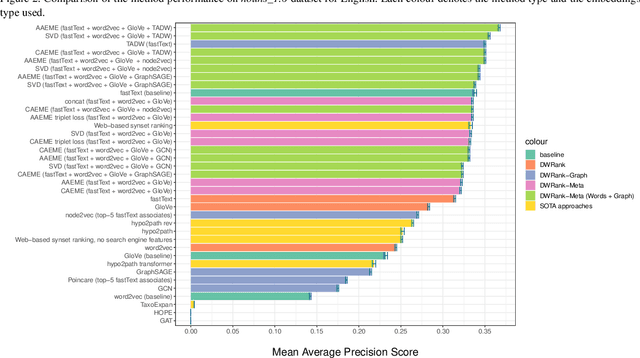
Knowledge graphs such as DBpedia, Freebase or Wikidata always contain a taxonomic backbone that allows the arrangement and structuring of various concepts in accordance with the hypo-hypernym ("class-subclass") relationship. With the rapid growth of lexical resources for specific domains, the problem of automatic extension of the existing knowledge bases with new words is becoming more and more widespread. In this paper, we address the problem of taxonomy enrichment which aims at adding new words to the existing taxonomy. We present a new method that allows achieving high results on this task with little effort. It uses the resources which exist for the majority of languages, making the method universal. We extend our method by incorporating deep representations of graph structures like node2vec, Poincar\'e embeddings, GCN etc. that have recently demonstrated promising results on various NLP tasks. Furthermore, combining these representations with word embeddings allows us to beat the state of the art. We conduct a comprehensive study of the existing approaches to taxonomy enrichment based on word and graph vector representations and their fusion approaches. We also explore the ways of using deep learning architectures to extend the taxonomic backbones of knowledge graphs. We create a number of datasets for taxonomy extension for English and Russian. We achieve state-of-the-art results across different datasets and provide an in-depth error analysis of mistakes.