 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCL-BU at SemEval-2026 Task 3: Fine-tuning XLM-RoBERTa for Multilingual Dimensional Sentiment Regression
Apr 10, 2026Dimensional Aspect-Based Sentiment Analysis (DimABSA) extends traditional ABSA from categorical polarity labels to continuous valence-arousal (VA) regression. This paper describes a system developed for Track A - Subtask 1 (Dimensional Aspect Sentiment Regression), aiming to predict real-valued VA scores in the [1, 9] range for each given aspect in a text. A fine-tuning approach based on XLM-RoBERTa-base is adopted, constructing the input as [CLS] T [SEP] a_i [SEP] and training dual regression heads with sigmoid-scaled outputs for valence and arousal prediction. Separate models are trained for each language-domain combination (English and Chinese across restaurant, laptop, and finance domains), and training and development sets are merged for final test predictions. In development experiments, the fine-tuning approach is compared against several large language models including GPT-5.2, LLaMA-3-70B, LLaMA-3.3-70B, and LLaMA-4-Maverick under a few-shot prompting setting, demonstrating that task-specific fine-tuning substantially and consistently outperforms these LLM-based methods across all evaluation datasets. The code is publicly available at https://github.com/tongwu17/SemEval-2026-Task3-Track-A.
RuOpinionNE-2024: Extraction of Opinion Tuples from Russian News Texts
Apr 09, 2025In this paper, we introduce the Dialogue Evaluation shared task on extraction of structured opinions from Russian news texts. The task of the contest is to extract opinion tuples for a given sentence; the tuples are composed of a sentiment holder, its target, an expression and sentiment from the holder to the target. In total, the task received more than 100 submissions. The participants experimented mainly with large language models in zero-shot, few-shot and fine-tuning formats. The best result on the test set was obtained with fine-tuning of a large language model. We also compared 30 prompts and 11 open source language models with 3-32 billion parameters in the 1-shot and 10-shot settings and found the best models and prompts.
Large Language Models in Targeted Sentiment Analysis
Apr 18, 2024



In this paper we investigate the use of decoder-based generative transformers for extracting sentiment towards the named entities in Russian news articles. We study sentiment analysis capabilities of instruction-tuned large language models (LLMs). We consider the dataset of RuSentNE-2023 in our study. The first group of experiments was aimed at the evaluation of zero-shot capabilities of LLMs with closed and open transparencies. The second covers the fine-tuning of Flan-T5 using the "chain-of-thought" (CoT) three-hop reasoning framework (THoR). We found that the results of the zero-shot approaches are similar to the results achieved by baseline fine-tuned encoder-based transformers (BERT-base). Reasoning capabilities of the fine-tuned Flan-T5 models with THoR achieve at least 5% increment with the base-size model compared to the results of the zero-shot experiment. The best results of sentiment analysis on RuSentNE-2023 were achieved by fine-tuned Flan-T5-xl, which surpassed the results of previous state-of-the-art transformer-based classifiers. Our CoT application framework is publicly available: https://github.com/nicolay-r/Reasoning-for-Sentiment-Analysis-Framework
nicolay-r at SemEval-2024 Task 3: Using Flan-T5 for Reasoning Emotion Cause in Conversations with Chain-of-Thought on Emotion States
Apr 04, 2024



Emotion expression is one of the essential traits of conversations. It may be self-related or caused by another speaker. The variety of reasons may serve as a source of the further emotion causes: conversation history, speaker's emotional state, etc. Inspired by the most recent advances in Chain-of-Thought, in this work, we exploit the existing three-hop reasoning approach (THOR) to perform large language model instruction-tuning for answering: emotion states (THOR-state), and emotion caused by one speaker to the other (THOR-cause). We equip THOR-cause with the reasoning revision (rr) for devising a reasoning path in fine-tuning. In particular, we rely on the annotated speaker emotion states to revise reasoning path. Our final submission, based on Flan-T5-base (250M) and the rule-based span correction technique, preliminary tuned with THOR-state and fine-tuned with THOR-cause-rr on competition training data, results in 3rd and 4th places (F1-proportional) and 5th place (F1-strict) among 15 participating teams. Our THOR implementation fork is publicly available: https://github.com/nicolay-r/THOR-ECAC
RuSentNE-2023: Evaluating Entity-Oriented Sentiment Analysis on Russian News Texts
May 28, 2023



The paper describes the RuSentNE-2023 evaluation devoted to targeted sentiment analysis in Russian news texts. The task is to predict sentiment towards a named entity in a single sentence. The dataset for RuSentNE-2023 evaluation is based on the Russian news corpus RuSentNE having rich sentiment-related annotation. The corpus is annotated with named entities and sentiments towards these entities, along with related effects and emotional states. The evaluation was organized using the CodaLab competition framework. The main evaluation measure was macro-averaged measure of positive and negative classes. The best results achieved were of 66% Macro F-measure (Positive+Negative classes). We also tested ChatGPT on the test set from our evaluation and found that the zero-shot answers provided by ChatGPT reached 60% of the F-measure, which corresponds to 4th place in the evaluation. ChatGPT also provided detailed explanations of its conclusion. This can be considered as quite high for zero-shot application.
Attention-Based Neural Networks for Sentiment Attitude Extraction using Distant Supervision
Jun 30, 2020
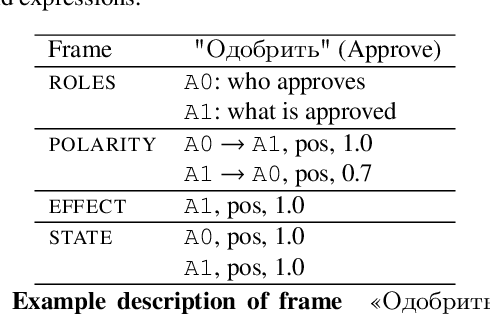

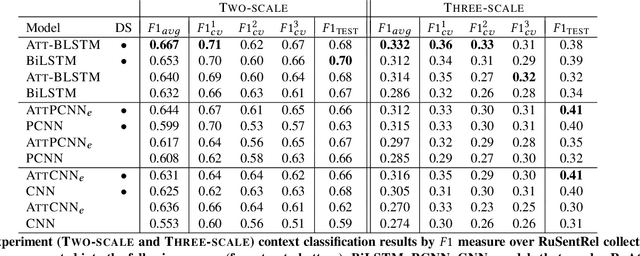
In the sentiment attitude extraction task, the aim is to identify <<attitudes>> -- sentiment relations between entities mentioned in text. In this paper, we provide a study on attention-based context encoders in the sentiment attitude extraction task. For this task, we adapt attentive context encoders of two types: (1) feature-based; (2) self-based. In our study, we utilize the corpus of Russian analytical texts RuSentRel and automatically constructed news collection RuAttitudes for enriching the training set. We consider the problem of attitude extraction as two-class (positive, negative) and three-class (positive, negative, neutral) classification tasks for whole documents. Our experiments with the RuSentRel corpus show that the three-class classification models, which employ the RuAttitudes corpus for training, result in 10% increase and extra 3% by F1, when model architectures include the attention mechanism. We also provide the analysis of attention weight distributions in dependence on the term type.
* 10 pages, 9 figures. The preprint of an article published in the proceedings of the 10th International Conference on Web Intelligence, Mining and Semantics (WIMS 2020). The final authenticated publication is available online at https://doi.org/10.1145/3405962.3405985. arXiv admin note: substantial text overlap with arXiv:2006.11605
Studying Attention Models in Sentiment Attitude Extraction Task
Jun 20, 2020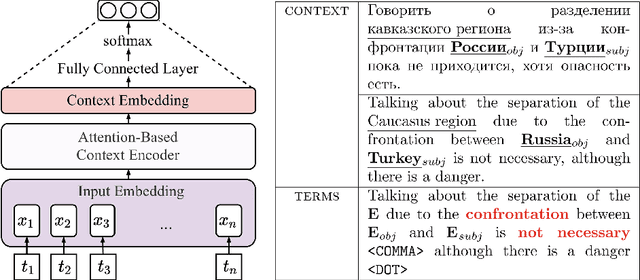

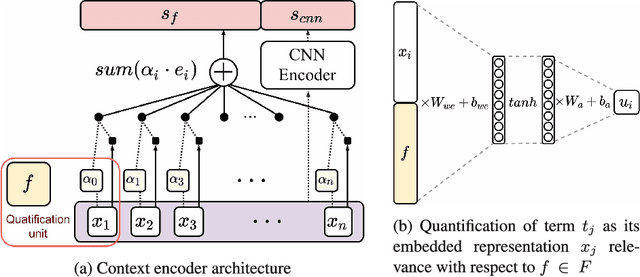
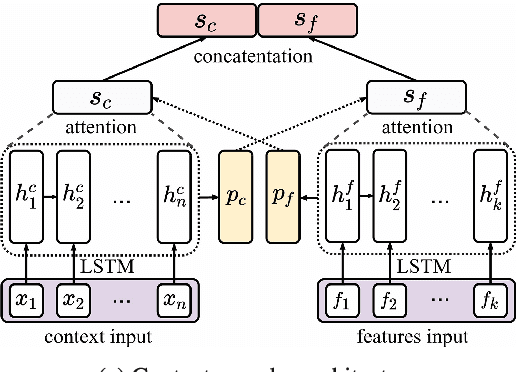
In the sentiment attitude extraction task, the aim is to identify <<attitudes>> -- sentiment relations between entities mentioned in text. In this paper, we provide a study on attention-based context encoders in the sentiment attitude extraction task. For this task, we adapt attentive context encoders of two types: (i) feature-based; (ii) self-based. Our experiments with a corpus of Russian analytical texts RuSentRel illustrate that the models trained with attentive encoders outperform ones that were trained without them and achieve 1.5-5.9% increase by F1. We also provide the analysis of attention weight distributions in dependence on the term type.
* This is a preprint of an article published in the Proceedings of the 25th International Conference on Natural Language and Information Systems. The final authenticated publication is available online at https://doi.org/10.1007/978-3-030-51310-8_15
Sentiment Frames for Attitude Extraction in Russian
Jun 19, 2020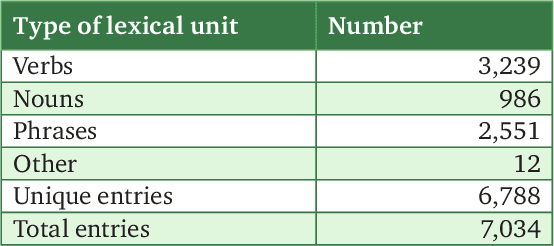
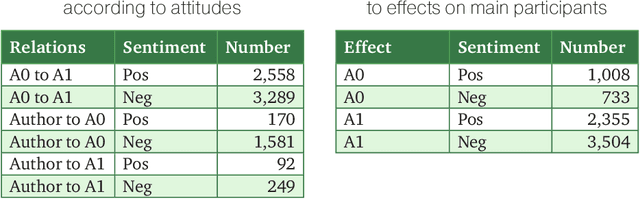

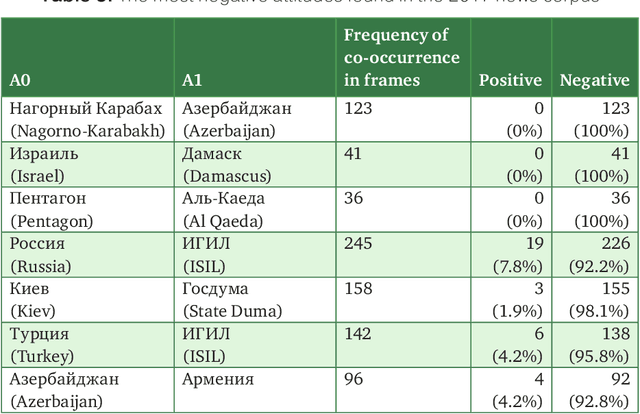
Texts can convey several types of inter-related information concerning opinions and attitudes. Such information includes the author's attitude towards mentioned entities, attitudes of the entities towards each other, positive and negative effects on the entities in the described situations. In this paper, we described the lexicon RuSentiFrames for Russian, where predicate words and expressions are collected and linked to so-called sentiment frames conveying several types of presupposed information on attitudes and effects. We applied the created frames in the task of extracting attitudes from a large news collection.
* 12 pages, 1 figure, 6 tables
Extracting Sentiment Attitudes From Analytical Texts
Aug 27, 2018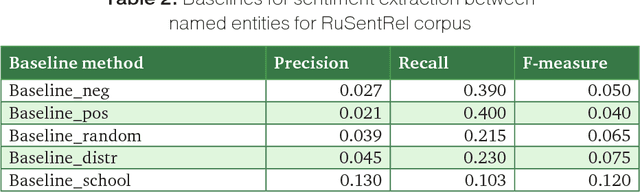
In this paper we present the RuSentRel corpus including analytical texts in the sphere of international relations. For each document we annotated sentiments from the author to mentioned named entities, and sentiments of relations between mentioned entities. In the current experiments, we considered the problem of extracting sentiment relations between entities for the whole documents as a three-class machine learning task. We experimented with conventional machine-learning methods (Naive Bayes, SVM, Random Forest).