 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Based Neural Networks for Sentiment Attitude Extraction using Distant Supervision
Paper and Code

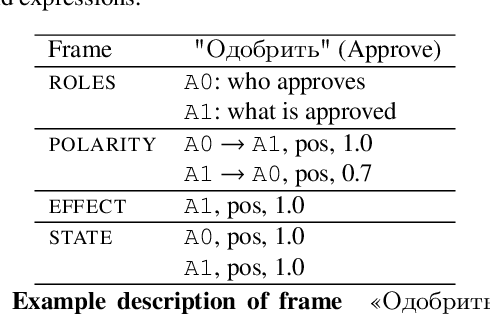

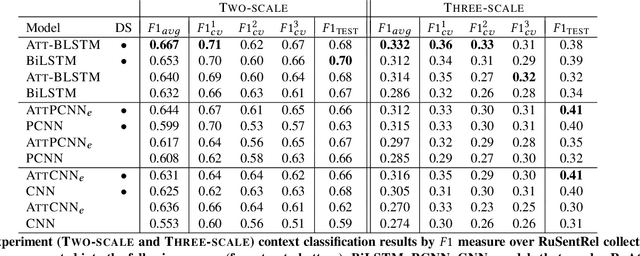
In the sentiment attitude extraction task, the aim is to identify <<attitudes>> -- sentiment relations between entities mentioned in text. In this paper, we provide a study on attention-based context encoders in the sentiment attitude extraction task. For this task, we adapt attentive context encoders of two types: (1) feature-based; (2) self-based. In our study, we utilize the corpus of Russian analytical texts RuSentRel and automatically constructed news collection RuAttitudes for enriching the training set. We consider the problem of attitude extraction as two-class (positive, negative) and three-class (positive, negative, neutral) classification tasks for whole documents. Our experiments with the RuSentRel corpus show that the three-class classification models, which employ the RuAttitudes corpus for training, result in 10% increase and extra 3% by F1, when model architectures include the attention mechanism. We also provide the analysis of attention weight distributions in dependence on the term type.