 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models in Targeted Sentiment Analysis
Apr 18, 2024



In this paper we investigate the use of decoder-based generative transformers for extracting sentiment towards the named entities in Russian news articles. We study sentiment analysis capabilities of instruction-tuned large language models (LLMs). We consider the dataset of RuSentNE-2023 in our study. The first group of experiments was aimed at the evaluation of zero-shot capabilities of LLMs with closed and open transparencies. The second covers the fine-tuning of Flan-T5 using the "chain-of-thought" (CoT) three-hop reasoning framework (THoR). We found that the results of the zero-shot approaches are similar to the results achieved by baseline fine-tuned encoder-based transformers (BERT-base). Reasoning capabilities of the fine-tuned Flan-T5 models with THoR achieve at least 5% increment with the base-size model compared to the results of the zero-shot experiment. The best results of sentiment analysis on RuSentNE-2023 were achieved by fine-tuned Flan-T5-xl, which surpassed the results of previous state-of-the-art transformer-based classifiers. Our CoT application framework is publicly available: https://github.com/nicolay-r/Reasoning-for-Sentiment-Analysis-Framework
RuSentNE-2023: Evaluating Entity-Oriented Sentiment Analysis on Russian News Texts
May 28, 2023



The paper describes the RuSentNE-2023 evaluation devoted to targeted sentiment analysis in Russian news texts. The task is to predict sentiment towards a named entity in a single sentence. The dataset for RuSentNE-2023 evaluation is based on the Russian news corpus RuSentNE having rich sentiment-related annotation. The corpus is annotated with named entities and sentiments towards these entities, along with related effects and emotional states. The evaluation was organized using the CodaLab competition framework. The main evaluation measure was macro-averaged measure of positive and negative classes. The best results achieved were of 66% Macro F-measure (Positive+Negative classes). We also tested ChatGPT on the test set from our evaluation and found that the zero-shot answers provided by ChatGPT reached 60% of the F-measure, which corresponds to 4th place in the evaluation. ChatGPT also provided detailed explanations of its conclusion. This can be considered as quite high for zero-shot application.
Transfer Learning for Improving Results on Russian Sentiment Datasets
Jul 06, 2021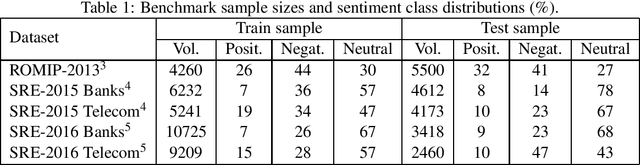
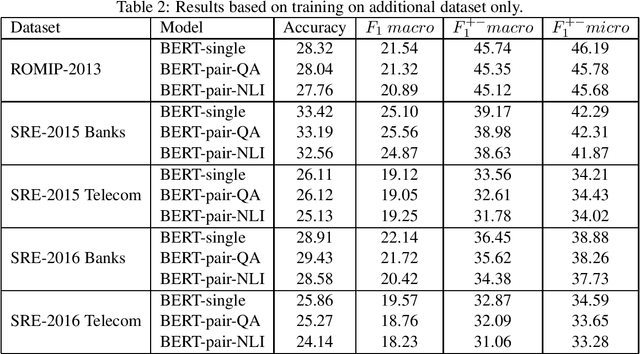
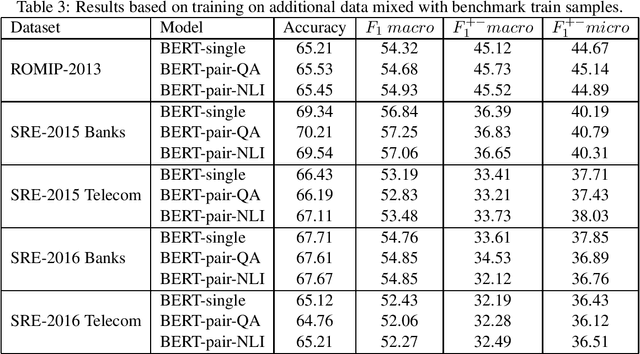
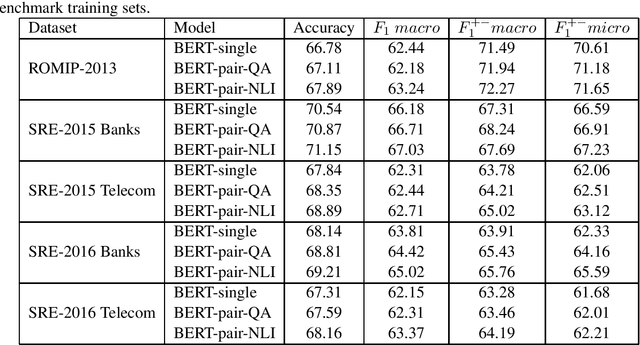
In this study, we test transfer learning approach on Russian sentiment benchmark datasets using additional train sample created with distant supervision technique. We compare several variants of combining additional data with benchmark train samples. The best results were achieved using three-step approach of sequential training on general, thematic and original train samples. For most datasets, the results were improved by more than 3% to the current state-of-the-art methods. The BERT-NLI model treating sentiment classification problem as a natural language inference task reached the human level of sentiment analysis on one of the datasets.
Improving Results on Russian Sentiment Datasets
Jul 28, 2020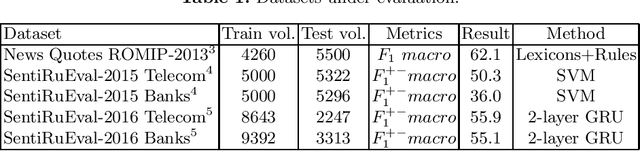


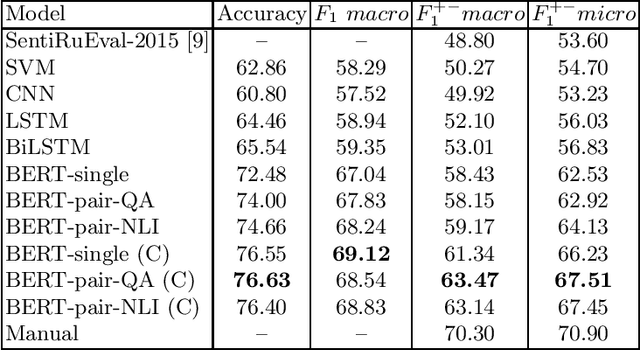
In this study, we test standard neural network architectures (CNN, LSTM, BiLSTM) and recently appeared BERT architectures on previous Russian sentiment evaluation datasets. We compare two variants of Russian BERT and show that for all sentiment tasks in this study the conversational variant of Russian BERT performs better. The best results were achieved by BERT-NLI model, which treats sentiment classification tasks as a natural language inference task. On one of the datasets, this model practically achieves the human level.