Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Results on Russian Sentiment Datasets
Paper and Code
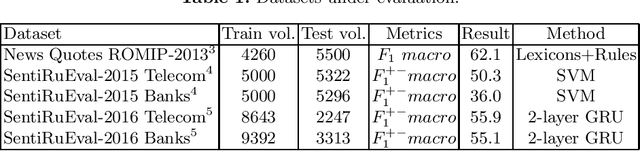


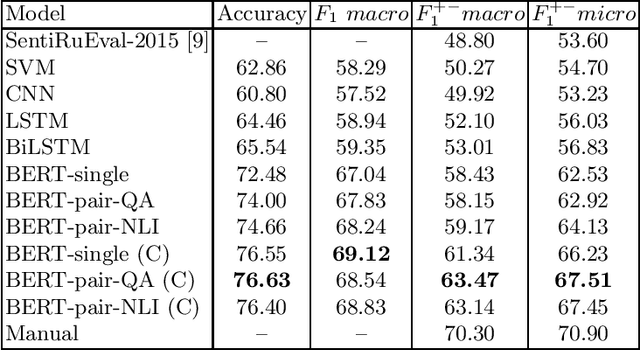
In this study, we test standard neural network architectures (CNN, LSTM, BiLSTM) and recently appeared BERT architectures on previous Russian sentiment evaluation datasets. We compare two variants of Russian BERT and show that for all sentiment tasks in this study the conversational variant of Russian BERT performs better. The best results were achieved by BERT-NLI model, which treats sentiment classification tasks as a natural language inference task. On one of the datasets, this model practically achieves the human level.
* 13 pages, 8 tables. Accepted to AINL-2020 conference
(https://ainlconf.ru/)
View paper on