 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the role of named entities for content preservation in text style transfer
Jun 20, 2022Text style transfer techniques are gaining popularity in Natural Language Processing, finding various applications such as text detoxification, sentiment, or formality transfer. However, the majority of the existing approaches were tested on such domains as online communications on public platforms, music, or entertainment yet none of them were applied to the domains which are typical for task-oriented production systems, such as personal plans arrangements (e.g. booking of flights or reserving a table in a restaurant). We fill this gap by studying formality transfer in this domain. We noted that the texts in this domain are full of named entities, which are very important for keeping the original sense of the text. Indeed, if for example, someone communicates the destination city of a flight it must not be altered. Thus, we concentrate on the role of named entities in content preservation for formality text style transfer. We collect a new dataset for the evaluation of content similarity measures in text style transfer. It is taken from a corpus of task-oriented dialogues and contains many important entities related to realistic requests that make this dataset particularly useful for testing style transfer models before using them in production. Besides, we perform an error analysis of a pre-trained formality transfer model and introduce a simple technique to use information about named entities to enhance the performance of baseline content similarity measures used in text style transfer.
Beyond Plain Toxic: Detection of Inappropriate Statements on Flammable Topics for the Russian Language
Mar 04, 2022
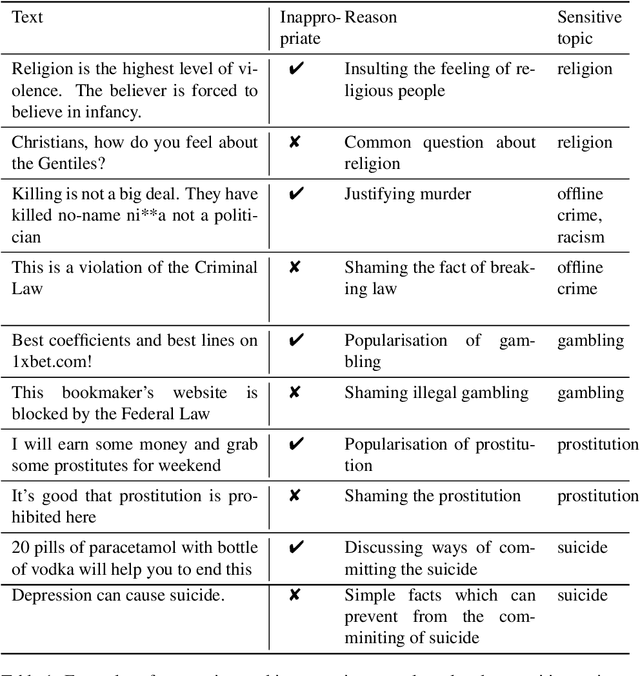
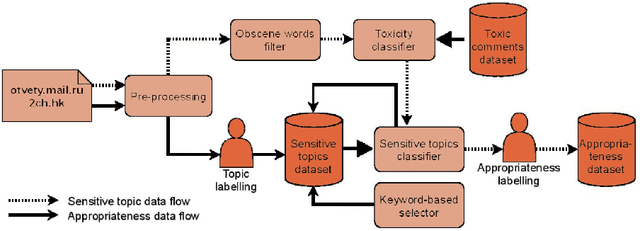

Toxicity on the Internet, such as hate speech, offenses towards particular users or groups of people, or the use of obscene words, is an acknowledged problem. However, there also exist other types of inappropriate messages which are usually not viewed as toxic, e.g. as they do not contain explicit offences. Such messages can contain covered toxicity or generalizations, incite harmful actions (crime, suicide, drug use), provoke "heated" discussions. Such messages are often related to particular sensitive topics, e.g. on politics, sexual minorities, social injustice which more often than other topics, e.g. cars or computing, yield toxic emotional reactions. At the same time, clearly not all messages within such flammable topics are inappropriate. Towards this end, in this work, we present two text collections labelled according to binary notion of inapropriateness and a multinomial notion of sensitive topic. Assuming that the notion of inappropriateness is common among people of the same culture, we base our approach on human intuitive understanding of what is not acceptable and harmful. To objectivise the notion of inappropriateness, we define it in a data-driven way though crowdsourcing. Namely we run a large-scale annotation study asking workers if a given chatbot textual statement could harm reputation of a company created it. Acceptably high values of inter-annotator agreement suggest that the notion of inappropriateness exists and can be uniformly understood by different people. To define the notion of sensitive topics in an objective way we use on guidelines suggested commonly by specialists of legal and PR department of a large public company as potentially harmful.
Taxonomy Enrichment with Text and Graph Vector Representations
Jan 21, 2022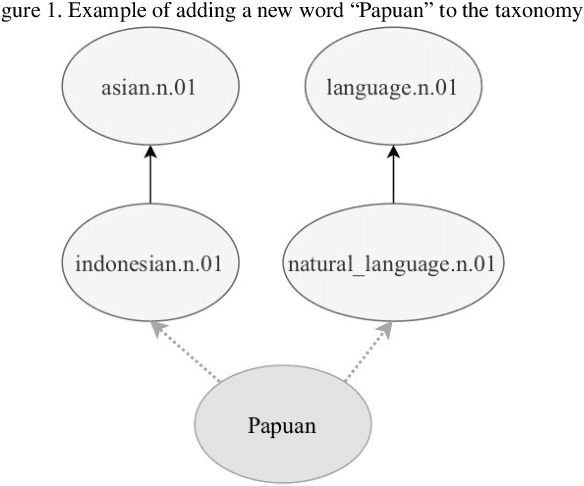
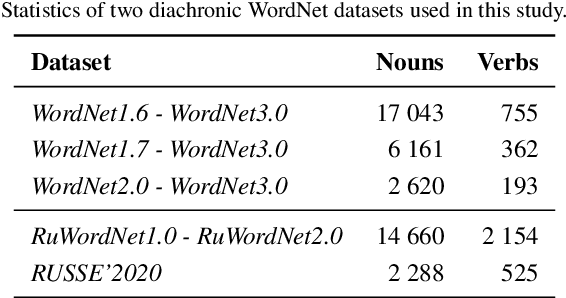
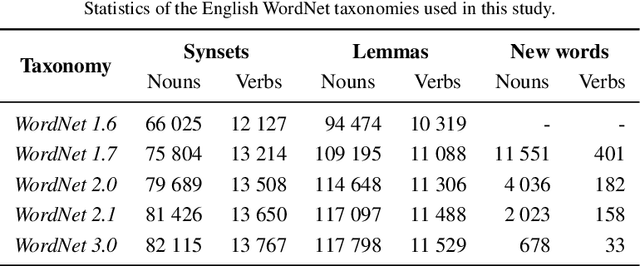
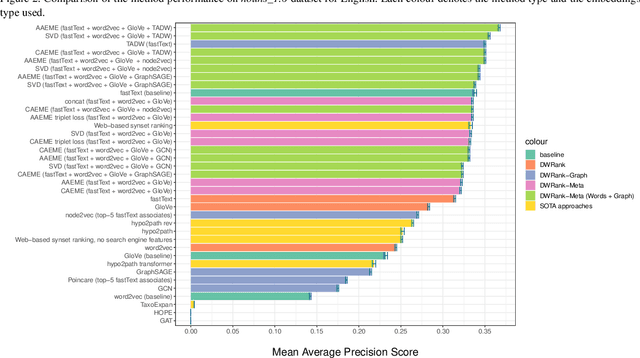
Knowledge graphs such as DBpedia, Freebase or Wikidata always contain a taxonomic backbone that allows the arrangement and structuring of various concepts in accordance with the hypo-hypernym ("class-subclass") relationship. With the rapid growth of lexical resources for specific domains, the problem of automatic extension of the existing knowledge bases with new words is becoming more and more widespread. In this paper, we address the problem of taxonomy enrichment which aims at adding new words to the existing taxonomy. We present a new method that allows achieving high results on this task with little effort. It uses the resources which exist for the majority of languages, making the method universal. We extend our method by incorporating deep representations of graph structures like node2vec, Poincar\'e embeddings, GCN etc. that have recently demonstrated promising results on various NLP tasks. Furthermore, combining these representations with word embeddings allows us to beat the state of the art. We conduct a comprehensive study of the existing approaches to taxonomy enrichment based on word and graph vector representations and their fusion approaches. We also explore the ways of using deep learning architectures to extend the taxonomic backbones of knowledge graphs. We create a number of datasets for taxonomy extension for English and Russian. We achieve state-of-the-art results across different datasets and provide an in-depth error analysis of mistakes.
Text Detoxification using Large Pre-trained Neural Models
Sep 18, 2021
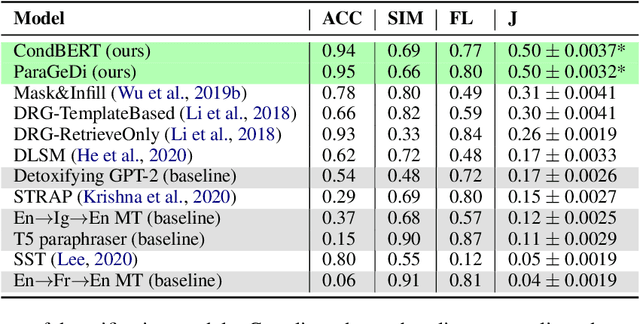
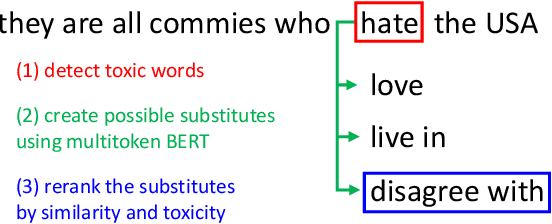

We present two novel unsupervised methods for eliminating toxicity in text. Our first method combines two recent ideas: (1) guidance of the generation process with small style-conditional language models and (2) use of paraphrasing models to perform style transfer. We use a well-performing paraphraser guided by style-trained language models to keep the text content and remove toxicity. Our second method uses BERT to replace toxic words with their non-offensive synonyms. We make the method more flexible by enabling BERT to replace mask tokens with a variable number of words. Finally, we present the first large-scale comparative study of style transfer models on the task of toxicity removal. We compare our models with a number of methods for style transfer. The models are evaluated in a reference-free way using a combination of unsupervised style transfer metrics. Both methods we suggest yield new SOTA results.
Methods for Detoxification of Texts for the Russian Language
May 19, 2021
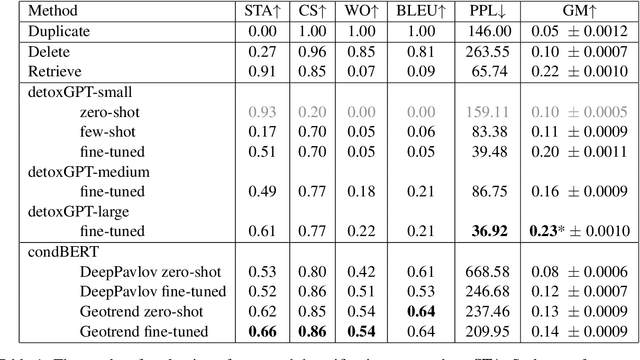
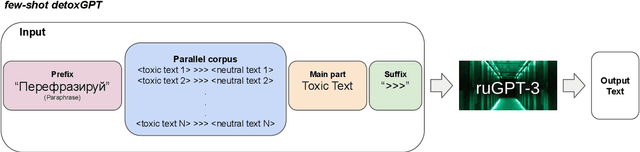
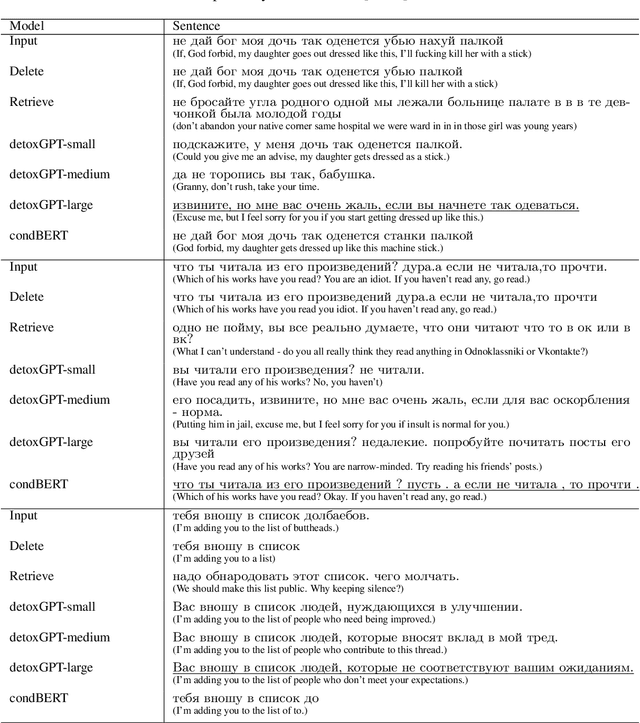
We introduce the first study of automatic detoxification of Russian texts to combat offensive language. Such a kind of textual style transfer can be used, for instance, for processing toxic content in social media. While much work has been done for the English language in this field, it has never been solved for the Russian language yet. We test two types of models - unsupervised approach based on BERT architecture that performs local corrections and supervised approach based on pretrained language GPT-2 model - and compare them with several baselines. In addition, we describe evaluation setup providing training datasets and metrics for automatic evaluation. The results show that the tested approaches can be successfully used for detoxification, although there is room for improvement.
Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company's Reputation
Mar 09, 2021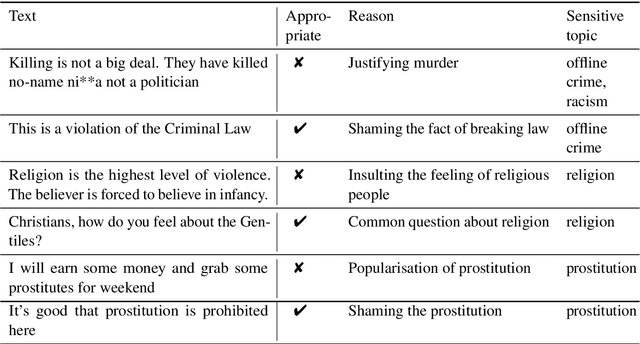


Not all topics are equally "flammable" in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labeling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labeled dataset and an appropriateness-labeled dataset. We also release pre-trained classification models trained on this data.
Studying Taxonomy Enrichment on Diachronic WordNet Versions
Nov 23, 2020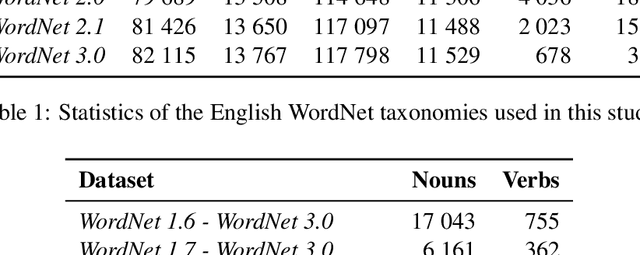
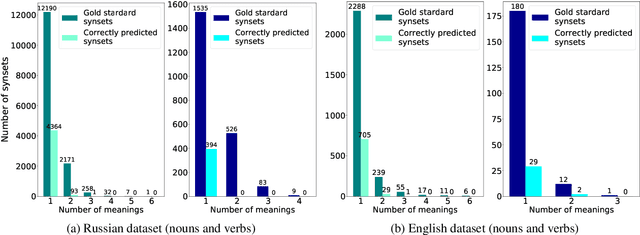
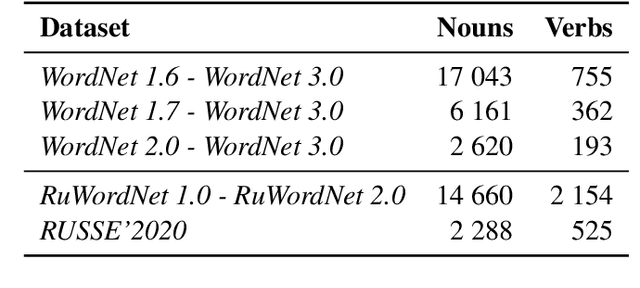
Ontologies, taxonomies, and thesauri are used in many NLP tasks. However, most studies are focused on the creation of these lexical resources rather than the maintenance of the existing ones. Thus, we address the problem of taxonomy enrichment. We explore the possibilities of taxonomy extension in a resource-poor setting and present methods which are applicable to a large number of languages. We create novel English and Russian datasets for training and evaluating taxonomy enrichment models and describe a technique of creating such datasets for other languages.
RUSSE'2020: Findings of the First Taxonomy Enrichment Task for the Russian language
May 22, 2020
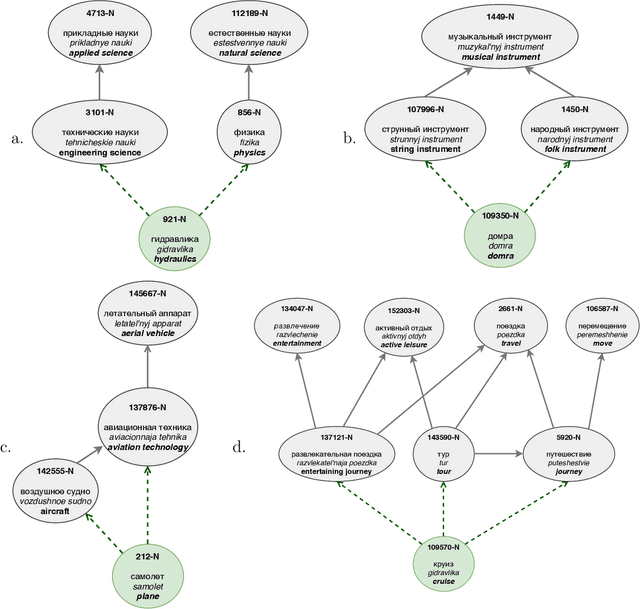
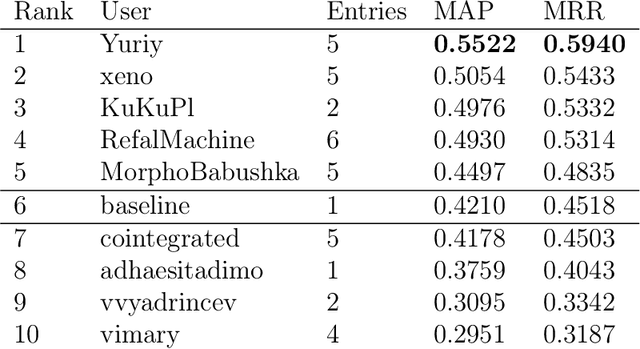
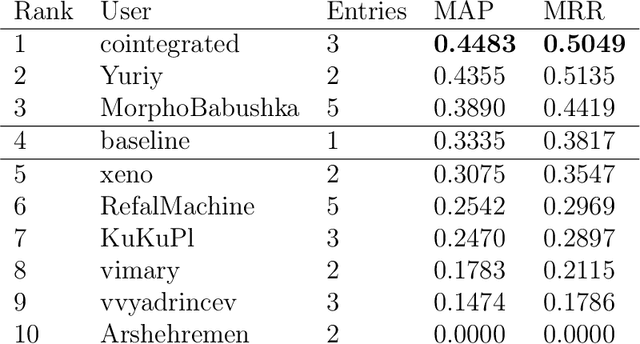
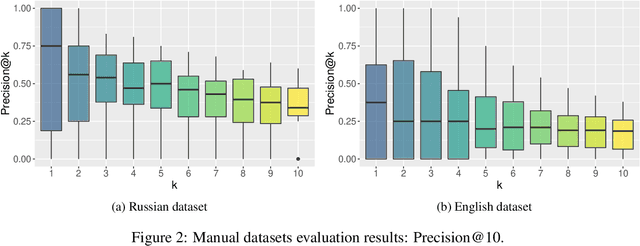
This paper describes the results of the first shared task on taxonomy enrichment for the Russian language. The participants were asked to extend an existing taxonomy with previously unseen words: for each new word their systems should provide a ranked list of possible (candidate) hypernyms. In comparison to the previous tasks for other languages, our competition has a more realistic task setting: new words were provided without definitions. Instead, we provided a textual corpus where these new terms occurred. For this evaluation campaign, we developed a new evaluation dataset based on unpublished RuWordNet data. The shared task features two tracks: "nouns" and "verbs". 16 teams participated in the task demonstrating high results with more than half of them outperforming the provided baseline.
Word Sense Disambiguation for 158 Languages using Word Embeddings Only
Mar 14, 2020
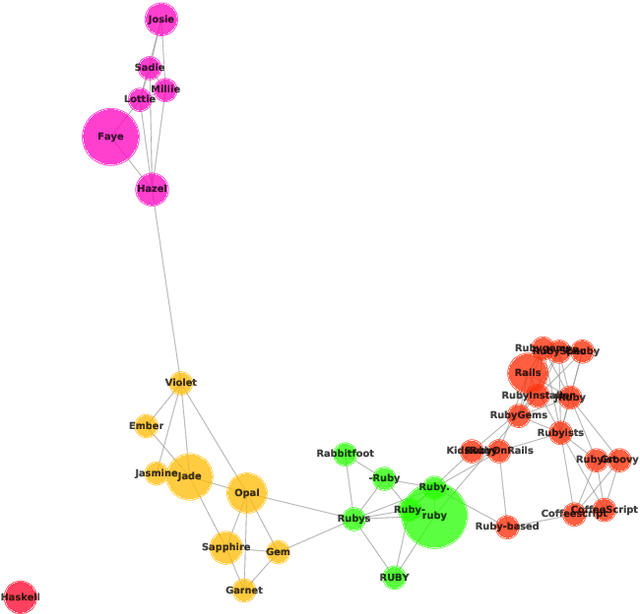

Disambiguation of word senses in context is easy for humans, but is a major challenge for automatic approaches. Sophisticated supervised and knowledge-based models were developed to solve this task. However, (i) the inherent Zipfian distribution of supervised training instances for a given word and/or (ii) the quality of linguistic knowledge representations motivate the development of completely unsupervised and knowledge-free approaches to word sense disambiguation (WSD). They are particularly useful for under-resourced languages which do not have any resources for building either supervised and/or knowledge-based models. In this paper, we present a method that takes as input a standard pre-trained word embedding model and induces a fully-fledged word sense inventory, which can be used for disambiguation in context. We use this method to induce a collection of sense inventories for 158 languages on the basis of the original pre-trained fastText word embeddings by Grave et al. (2018), enabling WSD in these languages. Models and system are available online.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019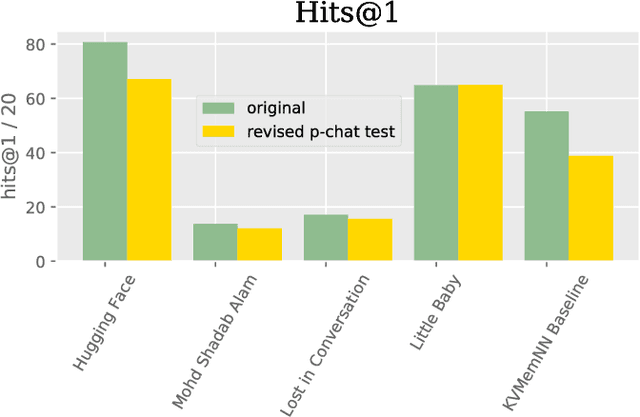

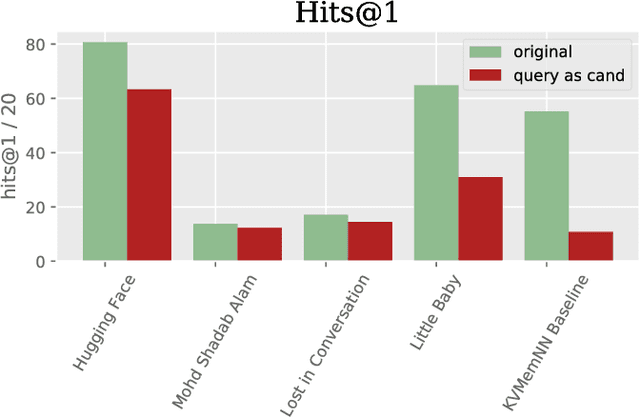
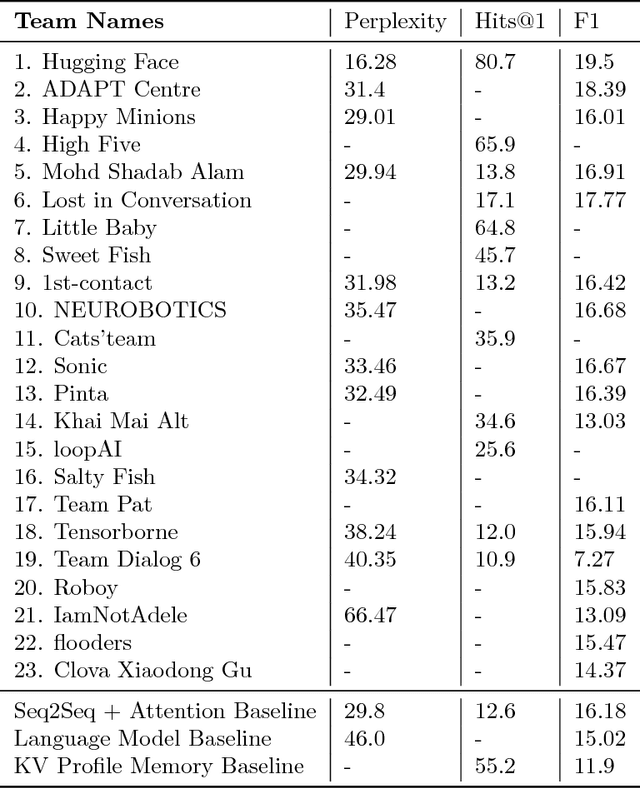
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).