 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't lose the message while paraphrasing: A study on content preserving style transfer
Aug 17, 2023Text style transfer techniques are gaining popularity in natural language processing allowing paraphrasing text in the required form: from toxic to neural, from formal to informal, from old to the modern English language, etc. Solving the task is not sufficient to generate some neural/informal/modern text, but it is important to preserve the original content unchanged. This requirement becomes even more critical in some applications such as style transfer of goal-oriented dialogues where the factual information shall be kept to preserve the original message, e.g. ordering a certain type of pizza to a certain address at a certain time. The aspect of content preservation is critical for real-world applications of style transfer studies, but it has received little attention. To bridge this gap we perform a comparison of various style transfer models on the example of the formality transfer domain. To perform a study of the content preservation abilities of various style transfer methods we create a parallel dataset of formal vs. informal task-oriented dialogues. The key difference between our dataset and the existing ones like GYAFC [17] is the presence of goal-oriented dialogues with predefined semantic slots essential to be kept during paraphrasing, e.g. named entities. This additional annotation allowed us to conduct a precise comparative study of several state-of-the-art techniques for style transfer. Another result of our study is a modification of the unsupervised method LEWIS [19] which yields a substantial improvement over the original method and all evaluated baselines on the proposed task.
Studying the role of named entities for content preservation in text style transfer
Jun 20, 2022Text style transfer techniques are gaining popularity in Natural Language Processing, finding various applications such as text detoxification, sentiment, or formality transfer. However, the majority of the existing approaches were tested on such domains as online communications on public platforms, music, or entertainment yet none of them were applied to the domains which are typical for task-oriented production systems, such as personal plans arrangements (e.g. booking of flights or reserving a table in a restaurant). We fill this gap by studying formality transfer in this domain. We noted that the texts in this domain are full of named entities, which are very important for keeping the original sense of the text. Indeed, if for example, someone communicates the destination city of a flight it must not be altered. Thus, we concentrate on the role of named entities in content preservation for formality text style transfer. We collect a new dataset for the evaluation of content similarity measures in text style transfer. It is taken from a corpus of task-oriented dialogues and contains many important entities related to realistic requests that make this dataset particularly useful for testing style transfer models before using them in production. Besides, we perform an error analysis of a pre-trained formality transfer model and introduce a simple technique to use information about named entities to enhance the performance of baseline content similarity measures used in text style transfer.
A Joint Approach to Compound Splitting and Idiomatic Compound Detection
Mar 21, 2020

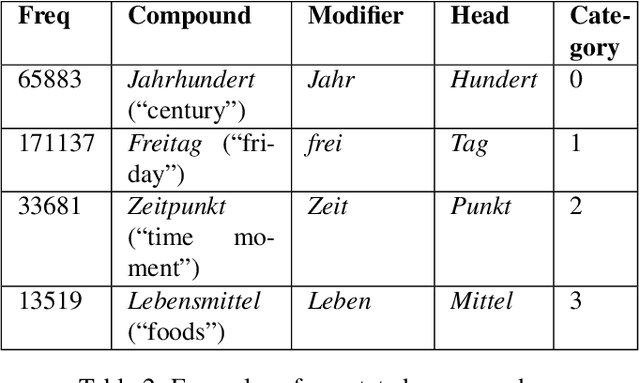
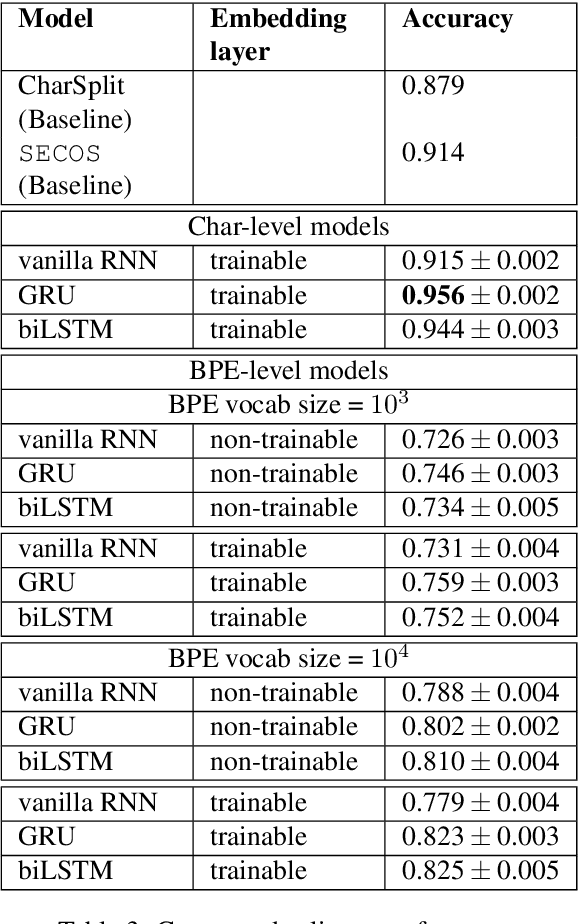
Applications such as machine translation, speech recognition, and information retrieval require efficient handling of noun compounds as they are one of the possible sources for out-of-vocabulary (OOV) words. In-depth processing of noun compounds requires not only splitting them into smaller components (or even roots) but also the identification of instances that should remain unsplitted as they are of idiomatic nature. We develop a two-fold deep learning-based approach of noun compound splitting and idiomatic compound detection for the German language that we train using a newly collected corpus of annotated German compounds. Our neural noun compound splitter operates on a sub-word level and outperforms the current state of the art by about 5%.