 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Approach to Compound Splitting and Idiomatic Compound Detection
Paper and Code


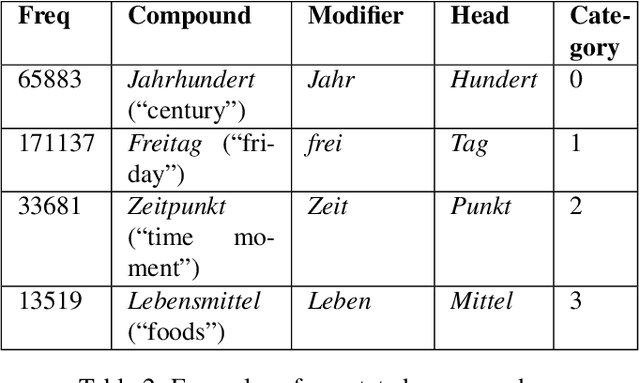
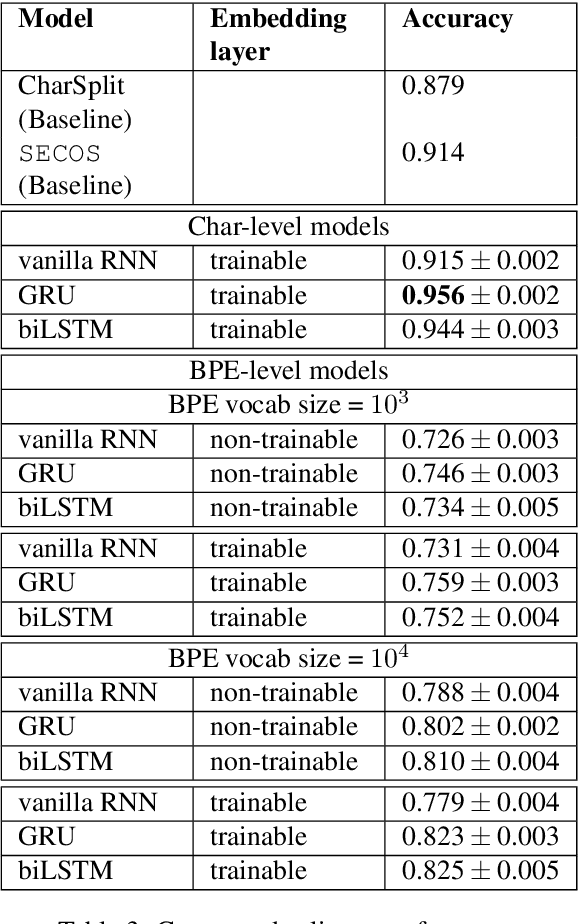
Applications such as machine translation, speech recognition, and information retrieval require efficient handling of noun compounds as they are one of the possible sources for out-of-vocabulary (OOV) words. In-depth processing of noun compounds requires not only splitting them into smaller components (or even roots) but also the identification of instances that should remain unsplitted as they are of idiomatic nature. We develop a two-fold deep learning-based approach of noun compound splitting and idiomatic compound detection for the German language that we train using a newly collected corpus of annotated German compounds. Our neural noun compound splitter operates on a sub-word level and outperforms the current state of the art by about 5%.