 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Plain Toxic: Detection of Inappropriate Statements on Flammable Topics for the Russian Language
Paper and Code

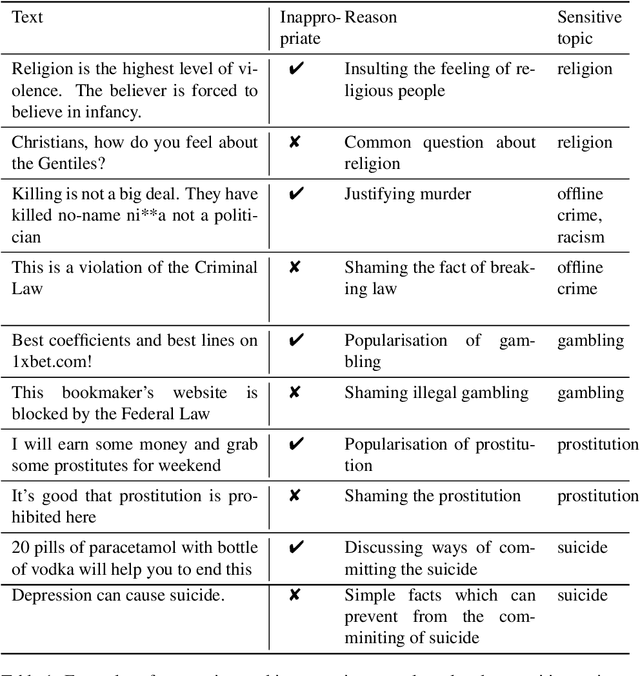
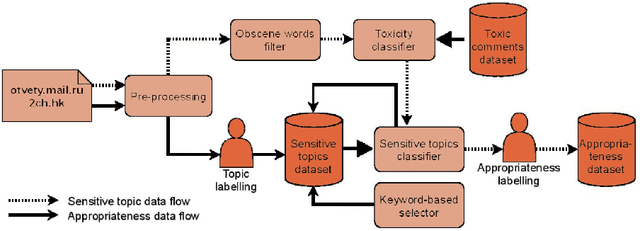

Toxicity on the Internet, such as hate speech, offenses towards particular users or groups of people, or the use of obscene words, is an acknowledged problem. However, there also exist other types of inappropriate messages which are usually not viewed as toxic, e.g. as they do not contain explicit offences. Such messages can contain covered toxicity or generalizations, incite harmful actions (crime, suicide, drug use), provoke "heated" discussions. Such messages are often related to particular sensitive topics, e.g. on politics, sexual minorities, social injustice which more often than other topics, e.g. cars or computing, yield toxic emotional reactions. At the same time, clearly not all messages within such flammable topics are inappropriate. Towards this end, in this work, we present two text collections labelled according to binary notion of inapropriateness and a multinomial notion of sensitive topic. Assuming that the notion of inappropriateness is common among people of the same culture, we base our approach on human intuitive understanding of what is not acceptable and harmful. To objectivise the notion of inappropriateness, we define it in a data-driven way though crowdsourcing. Namely we run a large-scale annotation study asking workers if a given chatbot textual statement could harm reputation of a company created it. Acceptably high values of inter-annotator agreement suggest that the notion of inappropriateness exists and can be uniformly understood by different people. To define the notion of sensitive topics in an objective way we use on guidelines suggested commonly by specialists of legal and PR department of a large public company as potentially harmful.