 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Teachers Can Use Large Language Models and Bloom's Taxonomy to Create Educational Quizzes
Jan 11, 2024Question generation (QG) is a natural language processing task with an abundance of potential benefits and use cases in the educational domain. In order for this potential to be realized, QG systems must be designed and validated with pedagogical needs in mind. However, little research has assessed or designed QG approaches with the input from real teachers or students. This paper applies a large language model-based QG approach where questions are generated with learning goals derived from Bloom's taxonomy. The automatically generated questions are used in multiple experiments designed to assess how teachers use them in practice. The results demonstrate that teachers prefer to write quizzes with automatically generated questions, and that such quizzes have no loss in quality compared to handwritten versions. Further, several metrics indicate that automatically generated questions can even improve the quality of the quizzes created, showing the promise for large scale use of QG in the classroom setting.
How Useful are Educational Questions Generated by Large Language Models?
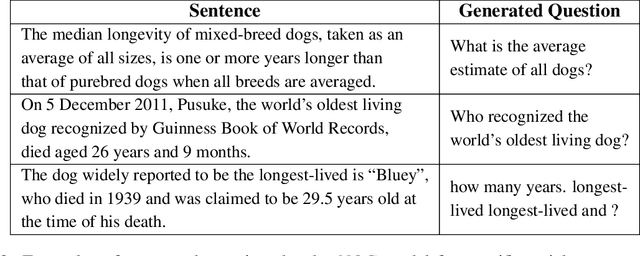
Apr 13, 2023Controllable text generation (CTG) by large language models has a huge potential to transform education for teachers and students alike. Specifically, high quality and diverse question generation can dramatically reduce the load on teachers and improve the quality of their educational content. Recent work in this domain has made progress with generation, but fails to show that real teachers judge the generated questions as sufficiently useful for the classroom setting; or if instead the questions have errors and/or pedagogically unhelpful content. We conduct a human evaluation with teachers to assess the quality and usefulness of outputs from combining CTG and question taxonomies (Bloom's and a difficulty taxonomy). The results demonstrate that the questions generated are high quality and sufficiently useful, showing their promise for widespread use in the classroom setting.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019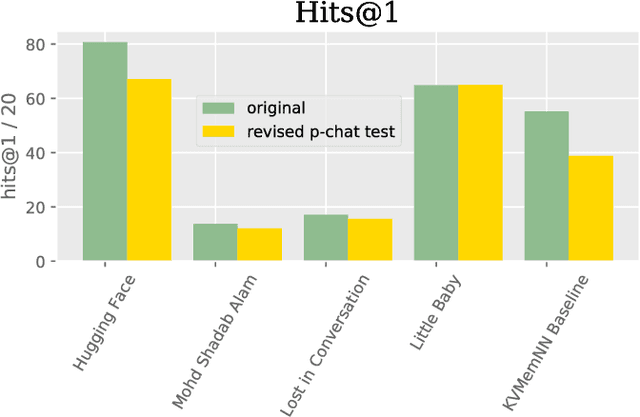

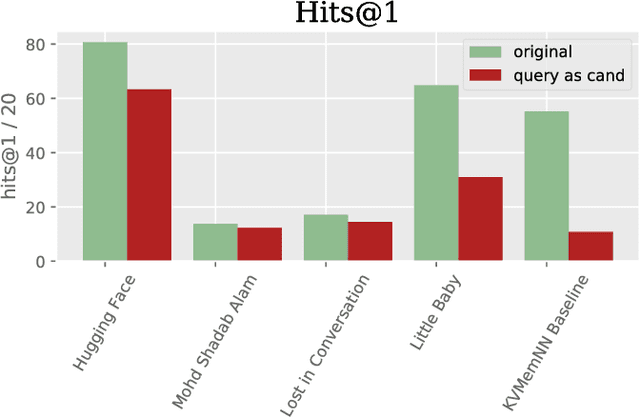
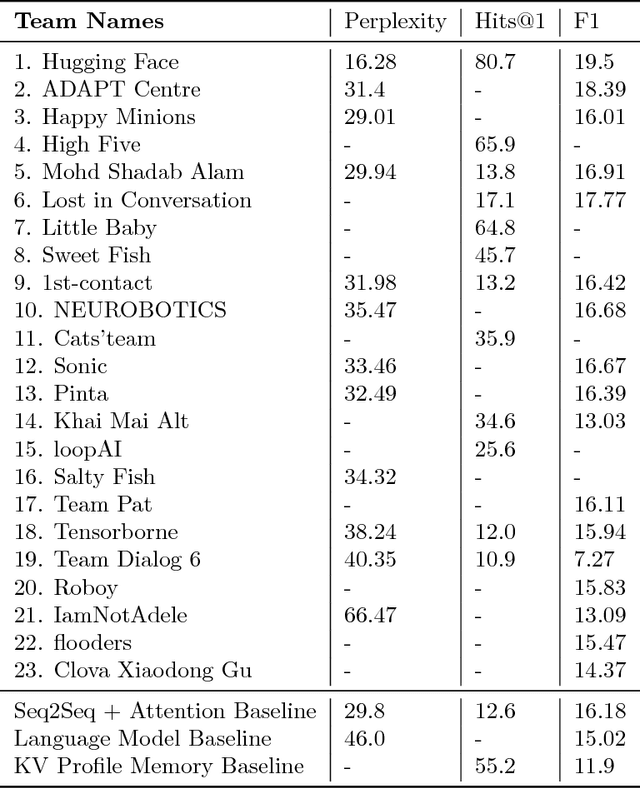
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
The RLLChatbot: a solution to the ConvAI challenge
Nov 08, 2018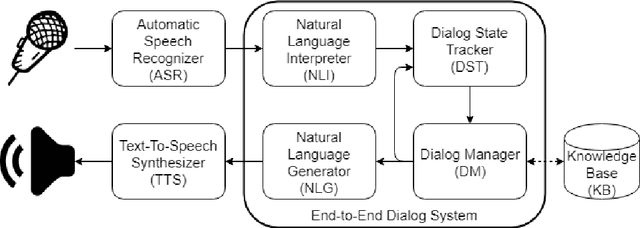

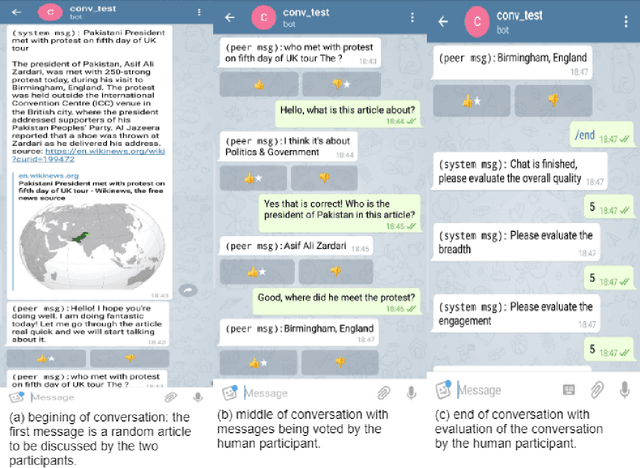
Current conversational systems can follow simple commands and answer basic questions, but they have difficulty maintaining coherent and open-ended conversations about specific topics. Competitions like the Conversational Intelligence (ConvAI) challenge are being organized to push the research development towards that goal. This article presents in detail the RLLChatbot that participated in the 2017 ConvAI challenge. The goal of this research is to better understand how current deep learning and reinforcement learning tools can be used to build a robust yet flexible open domain conversational agent. We provide a thorough description of how a dialog system can be built and trained from mostly public-domain datasets using an ensemble model. The first contribution of this work is a detailed description and analysis of different text generation models in addition to novel message ranking and selection methods. Moreover, a new open-source conversational dataset is presented. Training on this data significantly improves the Recall@k score of the ranking and selection mechanisms compared to our baseline model responsible for selecting the message returned at each interaction.
The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems
Feb 04, 2016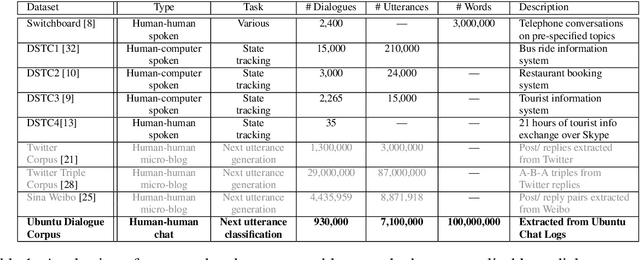
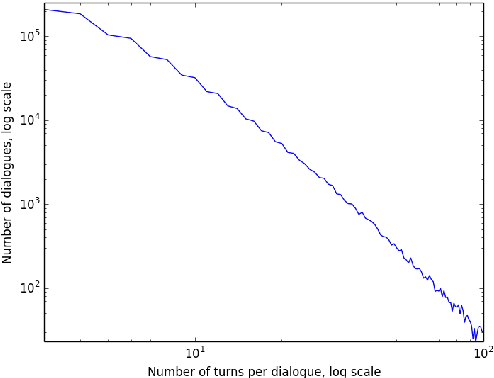
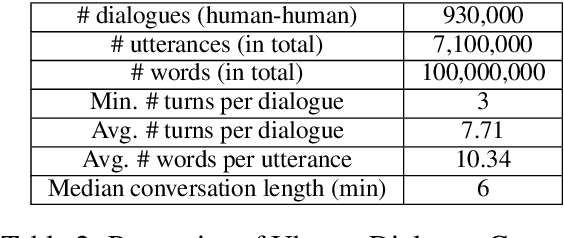
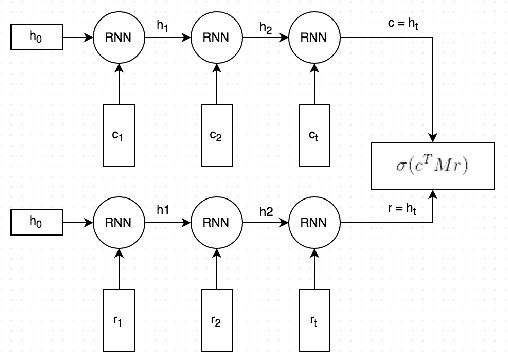
This paper introduces the Ubuntu Dialogue Corpus, a dataset containing almost 1 million multi-turn dialogues, with a total of over 7 million utterances and 100 million words. This provides a unique resource for research into building dialogue managers based on neural language models that can make use of large amounts of unlabeled data. The dataset has both the multi-turn property of conversations in the Dialog State Tracking Challenge datasets, and the unstructured nature of interactions from microblog services such as Twitter. We also describe two neural learning architectures suitable for analyzing this dataset, and provide benchmark performance on the task of selecting the best next response.