 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Teachers Can Use Large Language Models and Bloom's Taxonomy to Create Educational Quizzes
Jan 11, 2024
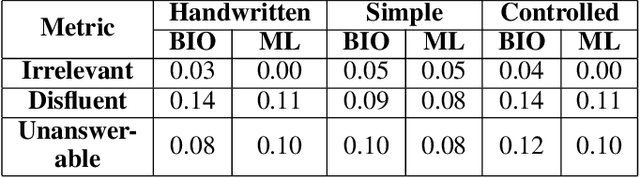

Question generation (QG) is a natural language processing task with an abundance of potential benefits and use cases in the educational domain. In order for this potential to be realized, QG systems must be designed and validated with pedagogical needs in mind. However, little research has assessed or designed QG approaches with the input from real teachers or students. This paper applies a large language model-based QG approach where questions are generated with learning goals derived from Bloom's taxonomy. The automatically generated questions are used in multiple experiments designed to assess how teachers use them in practice. The results demonstrate that teachers prefer to write quizzes with automatically generated questions, and that such quizzes have no loss in quality compared to handwritten versions. Further, several metrics indicate that automatically generated questions can even improve the quality of the quizzes created, showing the promise for large scale use of QG in the classroom setting.
Evaluating Dependencies in Fact Editing for Language Models: Specificity and Implication Awareness
Dec 04, 2023

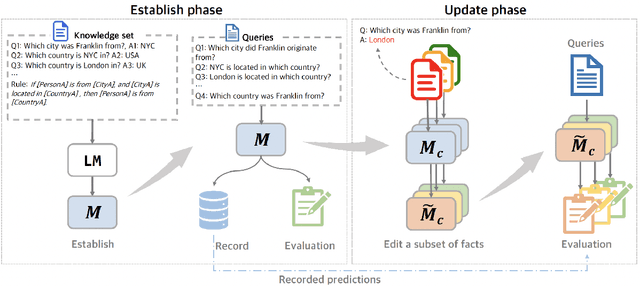
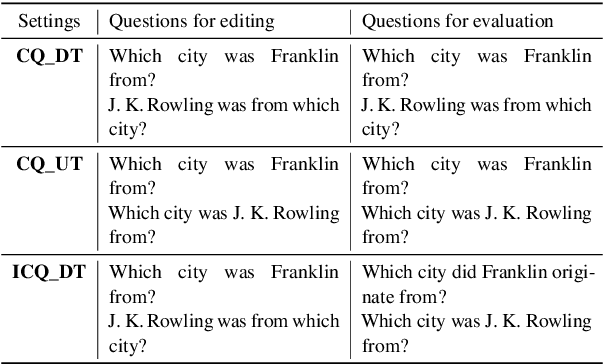
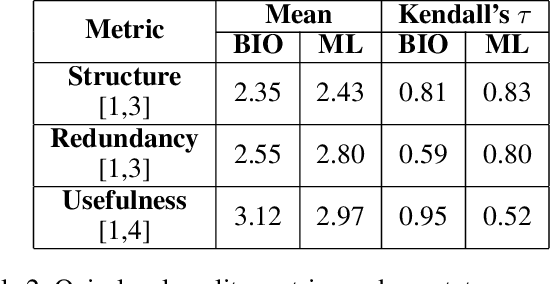
The potential of using a large language model (LLM) as a knowledge base (KB) has sparked significant interest. To manage the knowledge acquired by LLMs, we need to ensure that the editing of learned facts respects internal logical constraints, which are known as dependency of knowledge. Existing work on editing LLMs has partially addressed the issue of dependency, when the editing of a fact should apply to its lexical variations without disrupting irrelevant ones. However, they neglect the dependency between a fact and its logical implications. We propose an evaluation protocol with an accompanying question-answering dataset, DepEdit, that provides a comprehensive assessment of the editing process considering the above notions of dependency. Our protocol involves setting up a controlled environment in which we edit facts and monitor their impact on LLMs, along with their implications based on If-Then rules. Extensive experiments on DepEdit show that existing knowledge editing methods are sensitive to the surface form of knowledge, and that they have limited performance in inferring the implications of edited facts.
Ensemble Distillation for Unsupervised Constituency Parsing
Oct 03, 2023We investigate the unsupervised constituency parsing task, which organizes words and phrases of a sentence into a hierarchical structure without using linguistically annotated data. We observe that existing unsupervised parsers capture differing aspects of parsing structures, which can be leveraged to enhance unsupervised parsing performance. To this end, we propose a notion of "tree averaging," based on which we further propose a novel ensemble method for unsupervised parsing. To improve inference efficiency, we further distill the ensemble knowledge into a student model; such an ensemble-then-distill process is an effective approach to mitigate the over-smoothing problem existing in common multi-teacher distilling methods. Experiments show that our method surpasses all previous approaches, consistently demonstrating its effectiveness and robustness across various runs, with different ensemble components, and under domain-shift conditions.
How Useful are Educational Questions Generated by Large Language Models?
Apr 13, 2023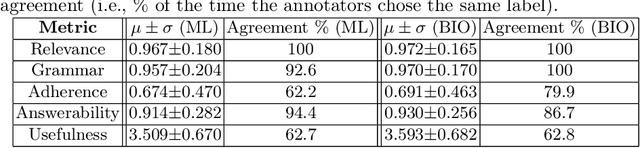
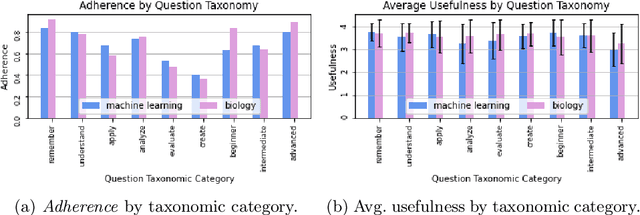
Controllable text generation (CTG) by large language models has a huge potential to transform education for teachers and students alike. Specifically, high quality and diverse question generation can dramatically reduce the load on teachers and improve the quality of their educational content. Recent work in this domain has made progress with generation, but fails to show that real teachers judge the generated questions as sufficiently useful for the classroom setting; or if instead the questions have errors and/or pedagogically unhelpful content. We conduct a human evaluation with teachers to assess the quality and usefulness of outputs from combining CTG and question taxonomies (Bloom's and a difficulty taxonomy). The results demonstrate that the questions generated are high quality and sufficiently useful, showing their promise for widespread use in the classroom setting.
The Stable Entropy Hypothesis and Entropy-Aware Decoding: An Analysis and Algorithm for Robust Natural Language Generation
Feb 14, 2023



State-of-the-art language generation models can degenerate when applied to open-ended generation problems such as text completion, story generation, or dialog modeling. This degeneration usually shows up in the form of incoherence, lack of vocabulary diversity, and self-repetition or copying from the context. In this paper, we postulate that ``human-like'' generations usually lie in a narrow and nearly flat entropy band, and violation of these entropy bounds correlates with degenerate behavior. Our experiments show that this stable narrow entropy zone exists across models, tasks, and domains and confirm the hypothesis that violations of this zone correlate with degeneration. We then use this insight to propose an entropy-aware decoding algorithm that respects these entropy bounds resulting in less degenerate, more contextual, and "human-like" language generation in open-ended text generation settings.
Using Interactive Feedback to Improve the Accuracy and Explainability of Question Answering Systems Post-Deployment
Apr 06, 2022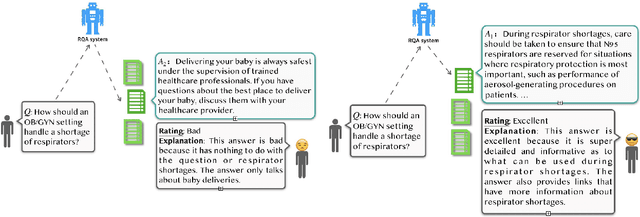
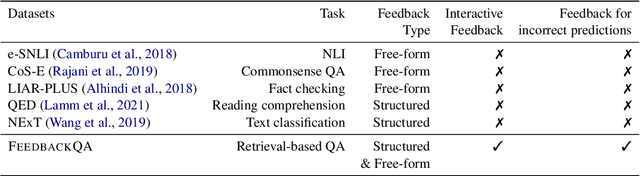
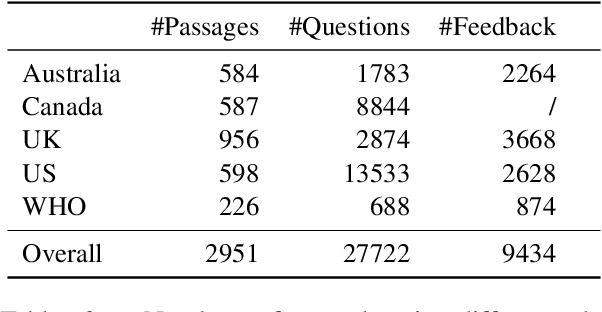
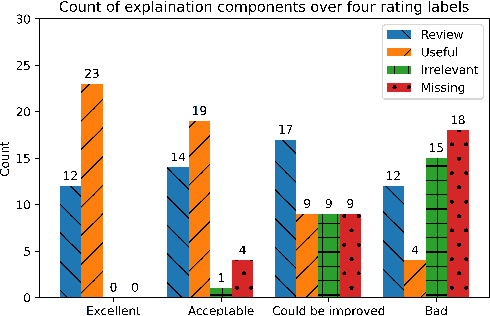
Most research on question answering focuses on the pre-deployment stage; i.e., building an accurate model for deployment. In this paper, we ask the question: Can we improve QA systems further \emph{post-}deployment based on user interactions? We focus on two kinds of improvements: 1) improving the QA system's performance itself, and 2) providing the model with the ability to explain the correctness or incorrectness of an answer. We collect a retrieval-based QA dataset, FeedbackQA, which contains interactive feedback from users. We collect this dataset by deploying a base QA system to crowdworkers who then engage with the system and provide feedback on the quality of its answers. The feedback contains both structured ratings and unstructured natural language explanations. We train a neural model with this feedback data that can generate explanations and re-score answer candidates. We show that feedback data not only improves the accuracy of the deployed QA system but also other stronger non-deployed systems. The generated explanations also help users make informed decisions about the correctness of answers. Project page: https://mcgill-nlp.github.io/feedbackqa/
Deep Discourse Analysis for Generating Personalized Feedback in Intelligent Tutor Systems
Mar 13, 2021
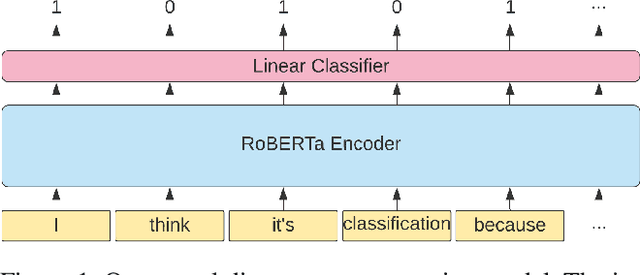
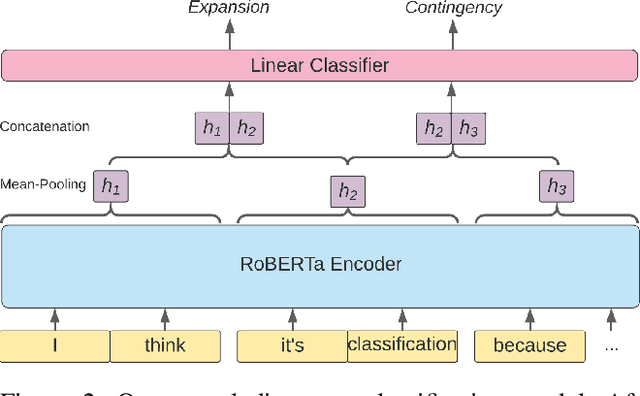

We explore creating automated, personalized feedback in an intelligent tutoring system (ITS). Our goal is to pinpoint correct and incorrect concepts in student answers in order to achieve better student learning gains. Although automatic methods for providing personalized feedback exist, they do not explicitly inform students about which concepts in their answers are correct or incorrect. Our approach involves decomposing students answers using neural discourse segmentation and classification techniques. This decomposition yields a relational graph over all discourse units covered by the reference solutions and student answers. We use this inferred relational graph structure and a neural classifier to match student answers with reference solutions and generate personalized feedback. Although the process is completely automated and data-driven, the personalized feedback generated is highly contextual, domain-aware and effectively targets each student's misconceptions and knowledge gaps. We test our method in a dialogue-based ITS and demonstrate that our approach results in high-quality feedback and significantly improved student learning gains.
HipoRank: Incorporating Hierarchical and Positional Information into Graph-based Unsupervised Long Document Extractive Summarization
May 01, 2020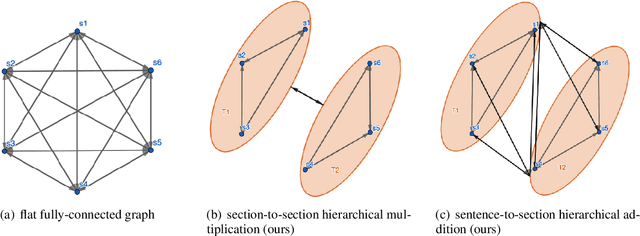
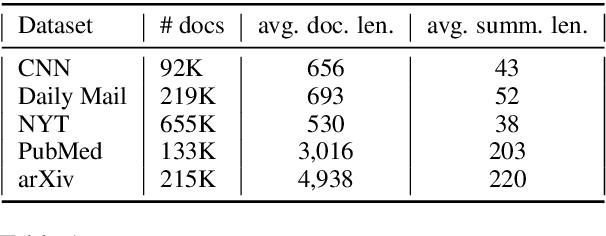
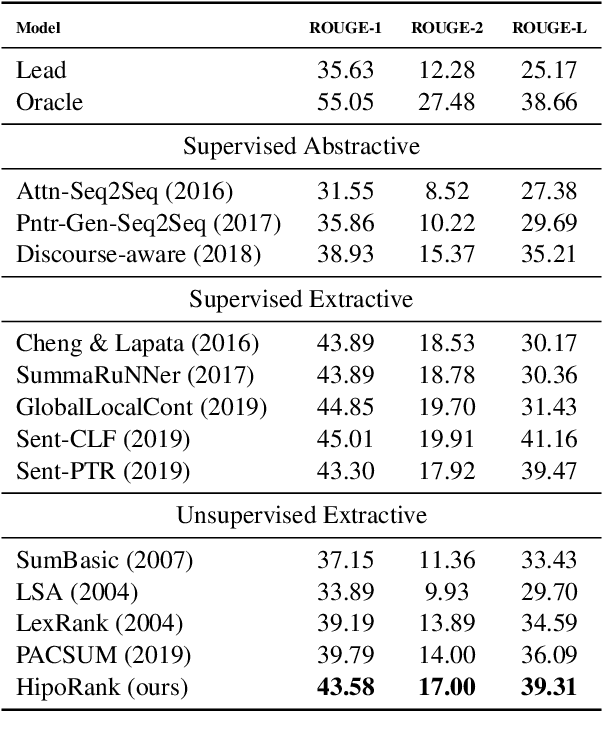
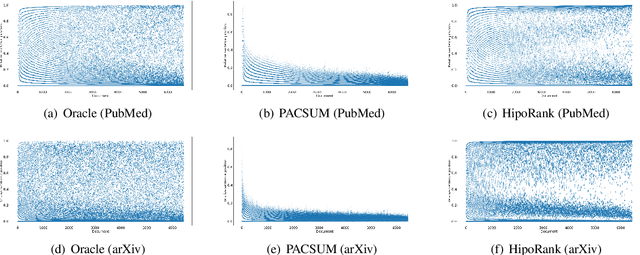
We propose a novel graph-based ranking model for unsupervised extractive summarization of long documents. Graph-based ranking models typically represent documents as undirected fully-connected graphs, where a node is a sentence, an edge is weighted based on sentence-pair similarity, and sentence importance is measured via node centrality. Our method leverages positional and hierarchical information grounded in discourse structure to augment a document's graph representation with hierarchy and directionality. Experimental results on PubMed and arXiv datasets show that our approach outperforms strong unsupervised baselines by wide margins and performs comparably to some of the state-of-the-art supervised models that are trained on hundreds of thousands of examples. In addition, we find that our method provides comparable improvements with various distributional sentence representations; including BERT and RoBERTa models fine-tuned on sentence similarity.
What comes next? Extractive summarization by next-sentence prediction
Jan 12, 2019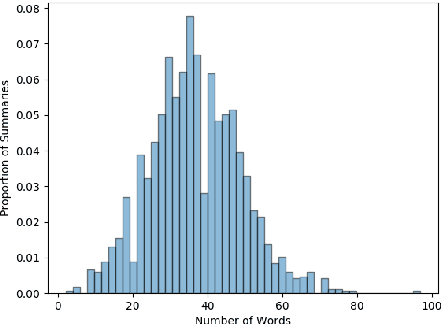
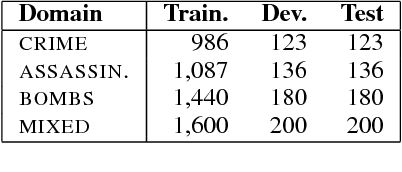
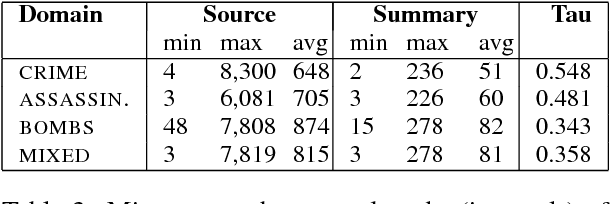
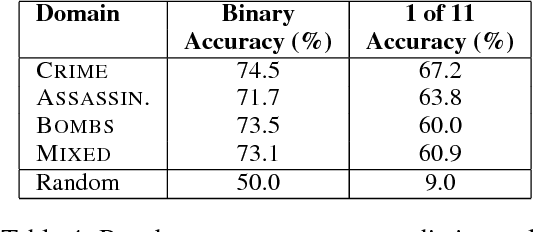
Existing approaches to automatic summarization assume that a length limit for the summary is given, and view content selection as an optimization problem to maximize informativeness and minimize redundancy within this budget. This framework ignores the fact that human-written summaries have rich internal structure which can be exploited to train a summarization system. We present NEXTSUM, a novel approach to summarization based on a model that predicts the next sentence to include in the summary using not only the source article, but also the summary produced so far. We show that such a model successfully captures summary-specific discourse moves, and leads to better content selection performance, in addition to automatically predicting how long the target summary should be. We perform experiments on the New York Times Annotated Corpus of summaries, where NEXTSUM outperforms lead and content-model summarization baselines by significant margins. We also show that the lengths of summaries produced by our system correlates with the lengths of the human-written gold standards.
Detecting Large Concept Extensions for Conceptual Analysis
Jun 18, 2017
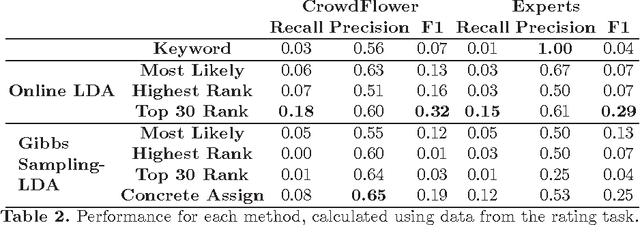
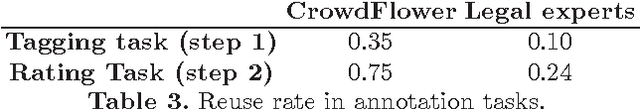
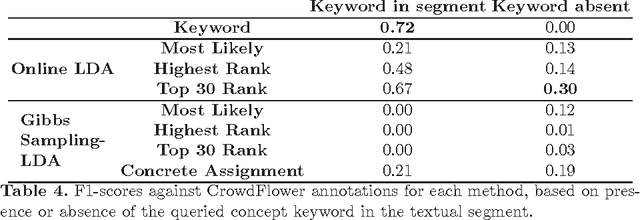
When performing a conceptual analysis of a concept, philosophers are interested in all forms of expression of a concept in a text---be it direct or indirect, explicit or implicit. In this paper, we experiment with topic-based methods of automating the detection of concept expressions in order to facilitate philosophical conceptual analysis. We propose six methods based on LDA, and evaluate them on a new corpus of court decision that we had annotated by experts and non-experts. Our results indicate that these methods can yield important improvements over the keyword heuristic, which is often used as a concept detection heuristic in many contexts. While more work remains to be done, this indicates that detecting concepts through topics can serve as a general-purpose method for at least some forms of concept expression that are not captured using naive keyword approaches.