 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIMPSE: Pragmatically Informative Multi-Document Summarization for Scholarly Reviews
Jun 11, 2024Scientific peer review is essential for the quality of academic publications. However, the increasing number of paper submissions to conferences has strained the reviewing process. This surge poses a burden on area chairs who have to carefully read an ever-growing volume of reviews and discern each reviewer's main arguments as part of their decision process. In this paper, we introduce \sys, a summarization method designed to offer a concise yet comprehensive overview of scholarly reviews. Unlike traditional consensus-based methods, \sys extracts both common and unique opinions from the reviews. We introduce novel uniqueness scores based on the Rational Speech Act framework to identify relevant sentences in the reviews. Our method aims to provide a pragmatic glimpse into all reviews, offering a balanced perspective on their opinions. Our experimental results with both automatic metrics and human evaluation show that \sys generates more discriminative summaries than baseline methods in terms of human evaluation while achieving comparable performance with these methods in terms of automatic metrics.
Evaluating Dependencies in Fact Editing for Language Models: Specificity and Implication Awareness
Dec 04, 2023

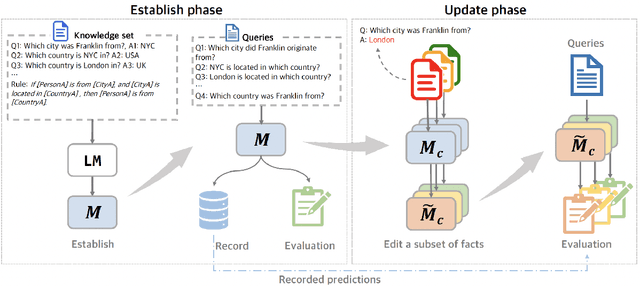
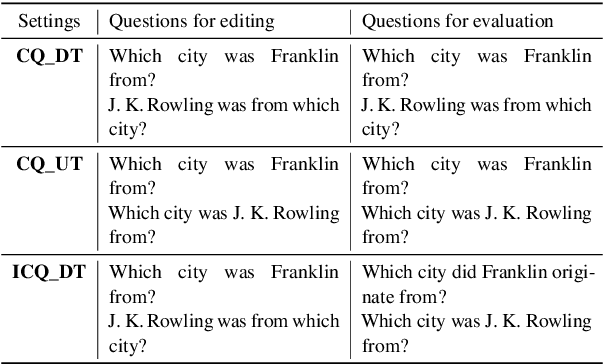
The potential of using a large language model (LLM) as a knowledge base (KB) has sparked significant interest. To manage the knowledge acquired by LLMs, we need to ensure that the editing of learned facts respects internal logical constraints, which are known as dependency of knowledge. Existing work on editing LLMs has partially addressed the issue of dependency, when the editing of a fact should apply to its lexical variations without disrupting irrelevant ones. However, they neglect the dependency between a fact and its logical implications. We propose an evaluation protocol with an accompanying question-answering dataset, DepEdit, that provides a comprehensive assessment of the editing process considering the above notions of dependency. Our protocol involves setting up a controlled environment in which we edit facts and monitor their impact on LLMs, along with their implications based on If-Then rules. Extensive experiments on DepEdit show that existing knowledge editing methods are sensitive to the surface form of knowledge, and that they have limited performance in inferring the implications of edited facts.
FashionBrain Project: A Vision for Understanding Europe's Fashion Data Universe
Oct 26, 2017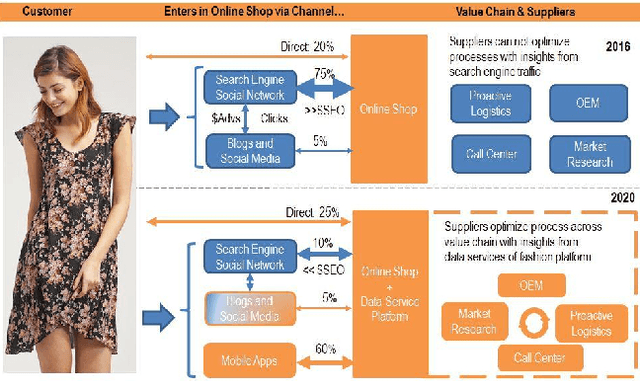

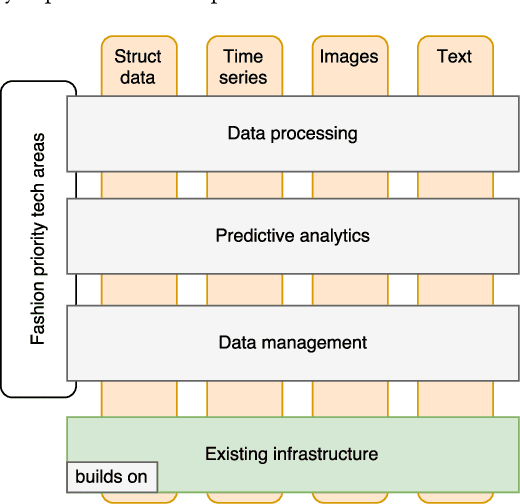
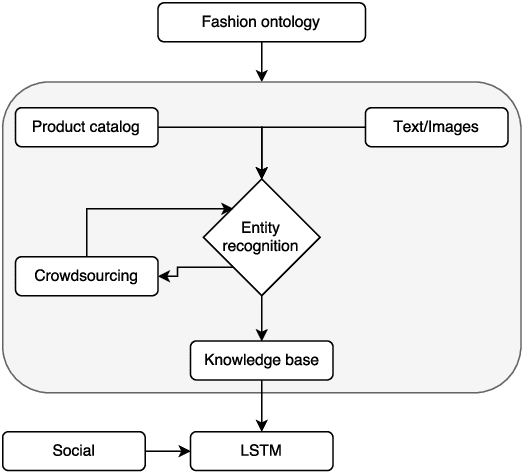
A core business in the fashion industry is the understanding and prediction of customer needs and trends. Search engines and social networks are at the same time a fundamental bridge and a costly middleman between the customer's purchase intention and the retailer. To better exploit Europe's distinctive characteristics e.g., multiple languages, fashion and cultural differences, it is pivotal to reduce retailers' dependence to search engines. This goal can be achieved by harnessing various data channels (manufacturers and distribution networks, online shops, large retailers, social media, market observers, call centers, press/magazines etc.) that retailers can leverage in order to gain more insight about potential buyers, and on the industry trends as a whole. This can enable the creation of novel on-line shopping experiences, the detection of influencers, and the prediction of upcoming fashion trends. In this paper, we provide an overview of the main research challenges and an analysis of the most promising technological solutions that we are investigating in the FashionBrain project.