 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Seq2seq Coreference Resolution Using Entity Representations
Oct 16, 2025
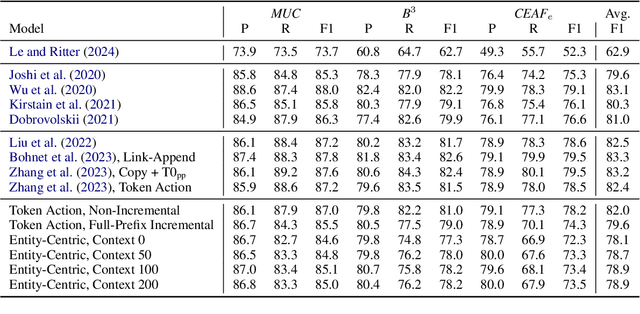
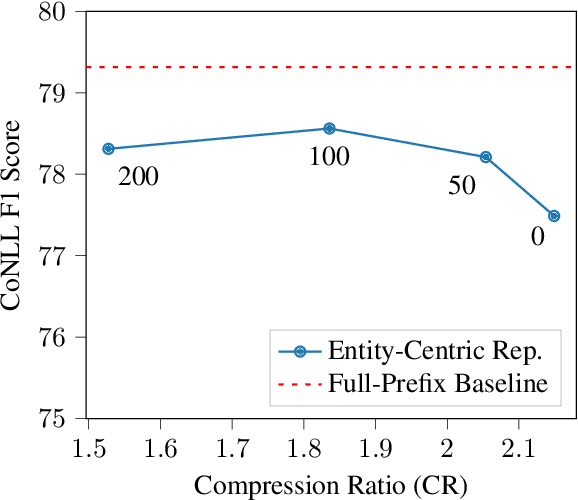
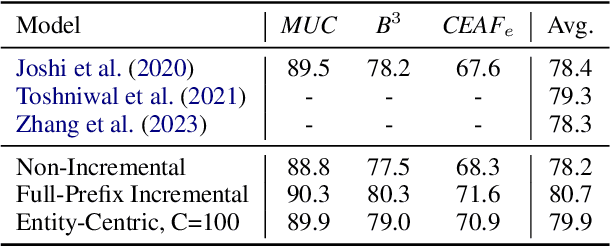
Seq2seq coreference models have introduced a new paradigm for coreference resolution by learning to generate text corresponding to coreference labels, without requiring task-specific parameters. While these models achieve new state-of-the-art performance, they do so at the cost of flexibility and efficiency. In particular, they do not efficiently handle incremental settings such as dialogue, where text must processed sequentially. We propose a compressed representation in order to improve the efficiency of these methods in incremental settings. Our method works by extracting and re-organizing entity-level tokens, and discarding the majority of other input tokens. On OntoNotes, our best model achieves just 0.6 CoNLL F1 points below a full-prefix, incremental baseline while achieving a compression ratio of 1.8. On LitBank, where singleton mentions are annotated, it passes state-of-the-art performance. Our results indicate that discarding a wide portion of tokens in seq2seq resolvers is a feasible strategy for incremental coreference resolution.
Exploration of Plan-Guided Summarization for Narrative Texts: the Case of Small Language Models
Apr 12, 2025



Plan-guided summarization attempts to reduce hallucinations in small language models (SLMs) by grounding generated summaries to the source text, typically by targeting fine-grained details such as dates or named entities. In this work, we investigate whether plan-based approaches in SLMs improve summarization in long document, narrative tasks. Narrative texts' length and complexity often mean they are difficult to summarize faithfully. We analyze existing plan-guided solutions targeting fine-grained details, and also propose our own higher-level, narrative-based plan formulation. Our results show that neither approach significantly improves on a baseline without planning in either summary quality or faithfulness. Human evaluation reveals that while plan-guided approaches are often well grounded to their plan, plans are equally likely to contain hallucinations compared to summaries. As a result, the plan-guided summaries are just as unfaithful as those from models without planning. Our work serves as a cautionary tale to plan-guided approaches to summarization, especially for long, complex domains such as narrative texts.
Sentence-Incremental Neural Coreference Resolution
May 26, 2023



We propose a sentence-incremental neural coreference resolution system which incrementally builds clusters after marking mention boundaries in a shift-reduce method. The system is aimed at bridging two recent approaches at coreference resolution: (1) state-of-the-art non-incremental models that incur quadratic complexity in document length with high computational cost, and (2) memory network-based models which operate incrementally but do not generalize beyond pronouns. For comparison, we simulate an incremental setting by constraining non-incremental systems to form partial coreference chains before observing new sentences. In this setting, our system outperforms comparable state-of-the-art methods by 2 F1 on OntoNotes and 7 F1 on the CODI-CRAC 2021 corpus. In a conventional coreference setup, our system achieves 76.3 F1 on OntoNotes and 45.8 F1 on CODI-CRAC 2021, which is comparable to state-of-the-art baselines. We also analyze variations of our system and show that the degree of incrementality in the encoder has a surprisingly large effect on the resulting performance.
Deep Discourse Analysis for Generating Personalized Feedback in Intelligent Tutor Systems
Mar 13, 2021
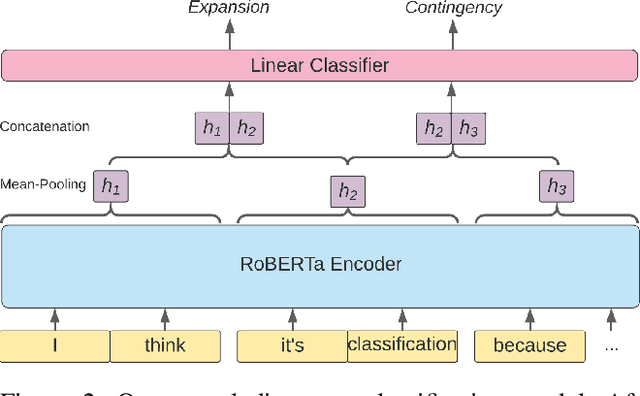

We explore creating automated, personalized feedback in an intelligent tutoring system (ITS). Our goal is to pinpoint correct and incorrect concepts in student answers in order to achieve better student learning gains. Although automatic methods for providing personalized feedback exist, they do not explicitly inform students about which concepts in their answers are correct or incorrect. Our approach involves decomposing students answers using neural discourse segmentation and classification techniques. This decomposition yields a relational graph over all discourse units covered by the reference solutions and student answers. We use this inferred relational graph structure and a neural classifier to match student answers with reference solutions and generate personalized feedback. Although the process is completely automated and data-driven, the personalized feedback generated is highly contextual, domain-aware and effectively targets each student's misconceptions and knowledge gaps. We test our method in a dialogue-based ITS and demonstrate that our approach results in high-quality feedback and significantly improved student learning gains.
Countering the Effects of Lead Bias in News Summarization via Multi-Stage Training and Auxiliary Losses
Sep 08, 2019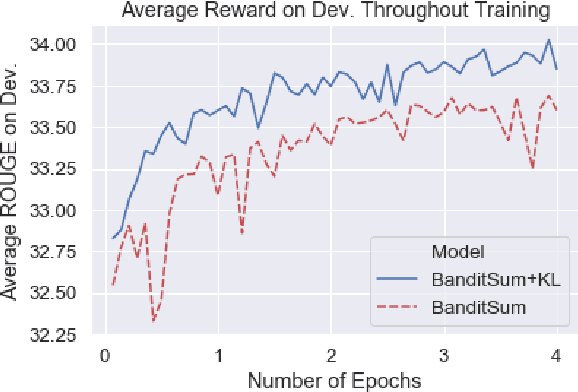
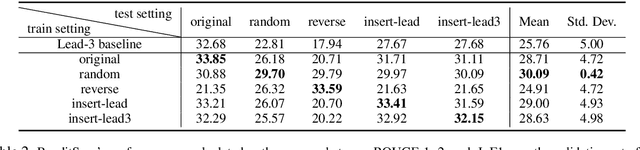
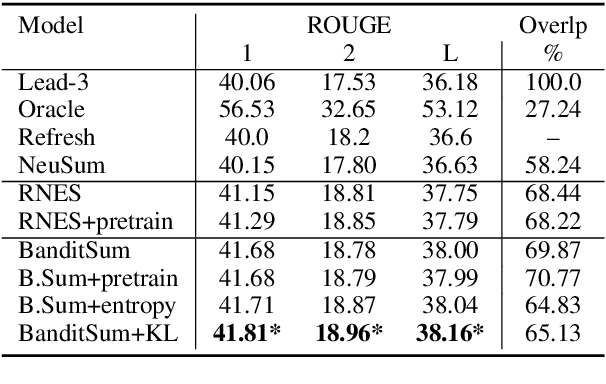
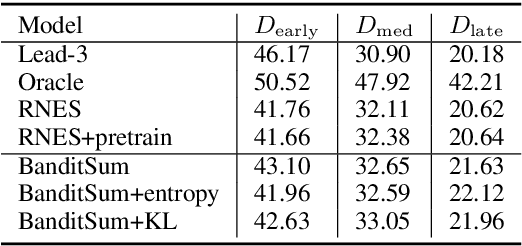
Sentence position is a strong feature for news summarization, since the lead often (but not always) summarizes the key points of the article. In this paper, we show that recent neural systems excessively exploit this trend, which although powerful for many inputs, is also detrimental when summarizing documents where important content should be extracted from later parts of the article. We propose two techniques to make systems sensitive to the importance of content in different parts of the article. The first technique employs 'unbiased' data; i.e., randomly shuffled sentences of the source document, to pretrain the model. The second technique uses an auxiliary ROUGE-based loss that encourages the model to distribute importance scores throughout a document by mimicking sentence-level ROUGE scores on the training data. We show that these techniques significantly improve the performance of a competitive reinforcement learning based extractive system, with the auxiliary loss being more powerful than pretraining.