 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of Plan-Guided Summarization for Narrative Texts: the Case of Small Language Models
Apr 12, 2025



Plan-guided summarization attempts to reduce hallucinations in small language models (SLMs) by grounding generated summaries to the source text, typically by targeting fine-grained details such as dates or named entities. In this work, we investigate whether plan-based approaches in SLMs improve summarization in long document, narrative tasks. Narrative texts' length and complexity often mean they are difficult to summarize faithfully. We analyze existing plan-guided solutions targeting fine-grained details, and also propose our own higher-level, narrative-based plan formulation. Our results show that neither approach significantly improves on a baseline without planning in either summary quality or faithfulness. Human evaluation reveals that while plan-guided approaches are often well grounded to their plan, plans are equally likely to contain hallucinations compared to summaries. As a result, the plan-guided summaries are just as unfaithful as those from models without planning. Our work serves as a cautionary tale to plan-guided approaches to summarization, especially for long, complex domains such as narrative texts.
Factual Confidence of LLMs: on Reliability and Robustness of Current Estimators
Jun 19, 2024Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
UniMorph 4.0: Universal Morphology
May 10, 2022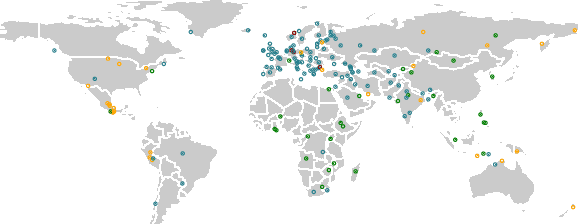

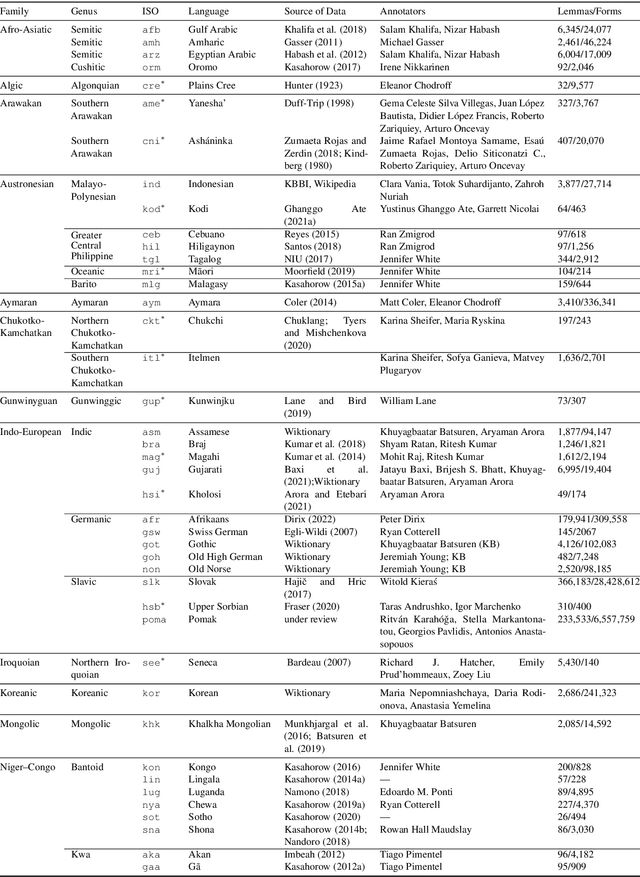
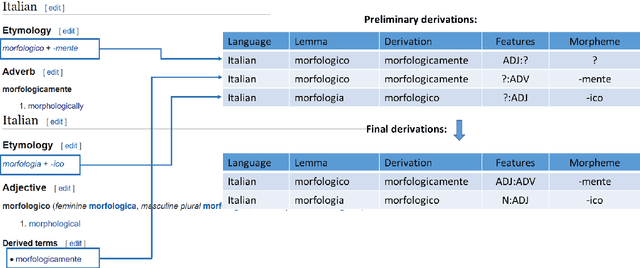
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Quantifying Social Biases in NLP: A Generalization and Empirical Comparison of Extrinsic Fairness Metrics
Jun 28, 2021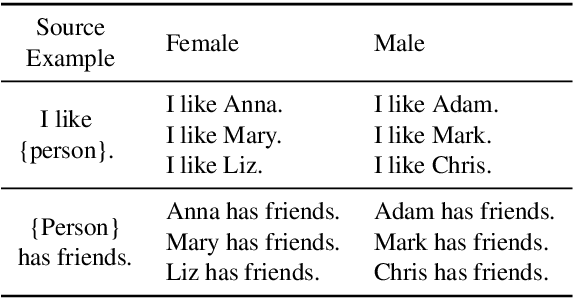
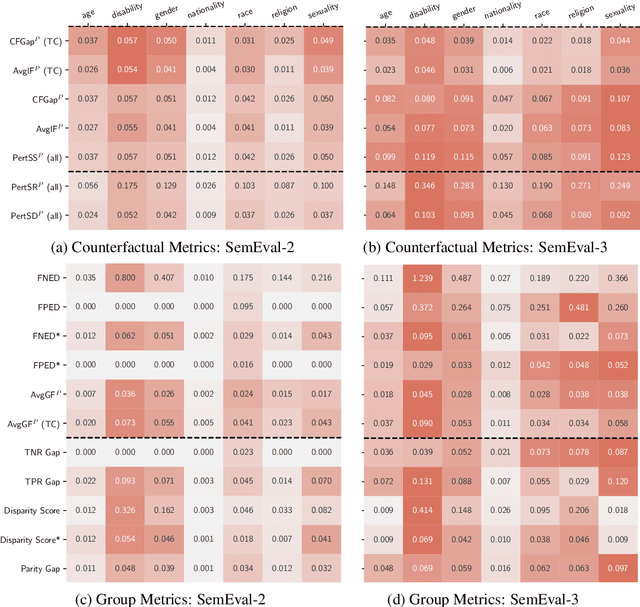
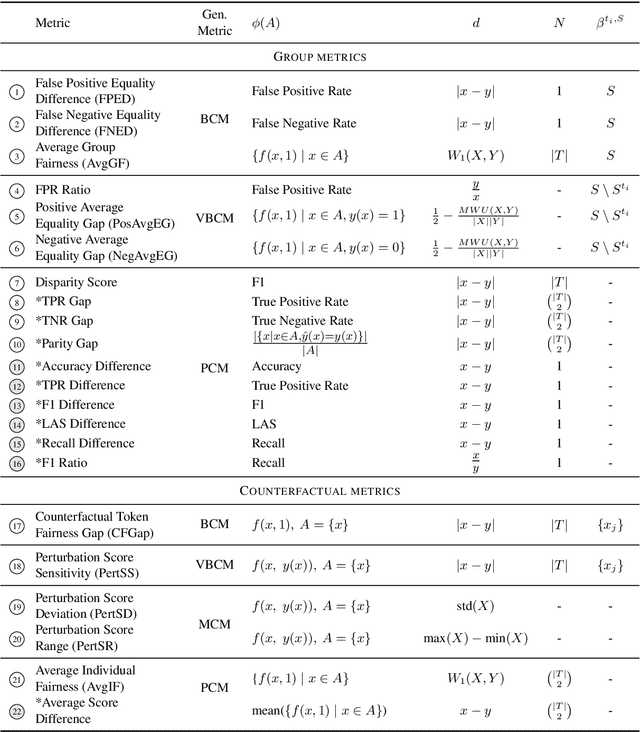
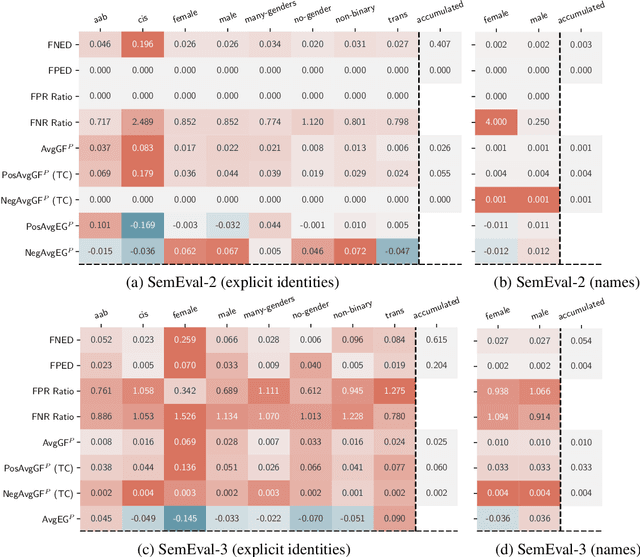
Measuring bias is key for better understanding and addressing unfairness in NLP/ML models. This is often done via fairness metrics which quantify the differences in a model's behaviour across a range of demographic groups. In this work, we shed more light on the differences and similarities between the fairness metrics used in NLP. First, we unify a broad range of existing metrics under three generalized fairness metrics, revealing the connections between them. Next, we carry out an extensive empirical comparison of existing metrics and demonstrate that the observed differences in bias measurement can be systematically explained via differences in parameter choices for our generalized metrics.
Morphologically Aware Word-Level Translation
Nov 15, 2020

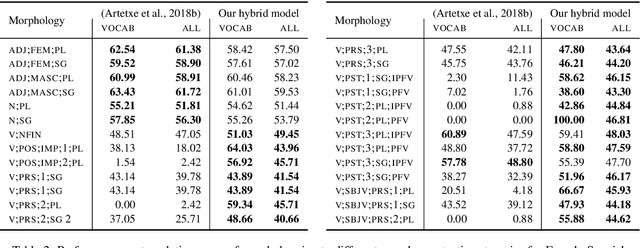

We propose a novel morphologically aware probability model for bilingual lexicon induction, which jointly models lexeme translation and inflectional morphology in a structured way. Our model exploits the basic linguistic intuition that the lexeme is the key lexical unit of meaning, while inflectional morphology provides additional syntactic information. This approach leads to substantial performance improvements - 19% average improvement in accuracy across 6 language pairs over the state of the art in the supervised setting and 16% in the weakly supervised setting. As another contribution, we highlight issues associated with modern BLI that stem from ignoring inflectional morphology, and propose three suggestions for improving the task.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020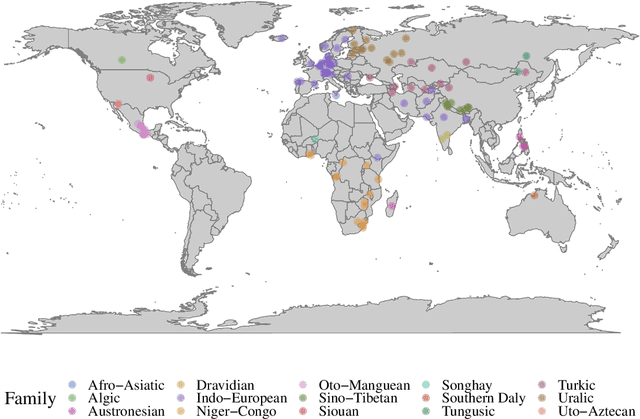
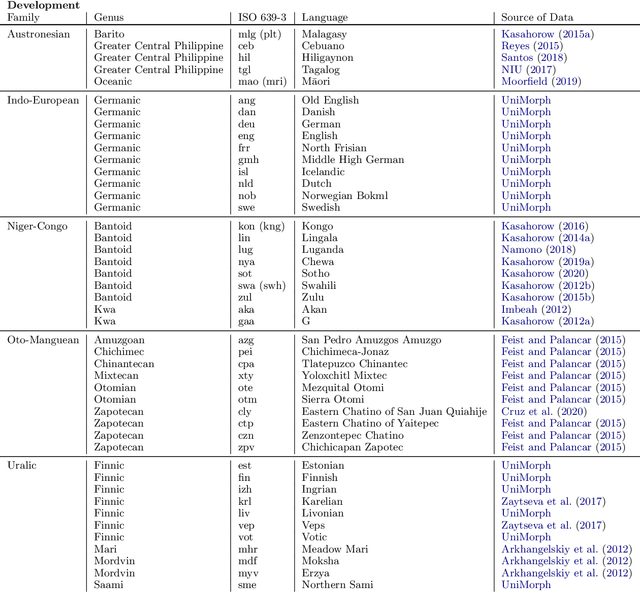
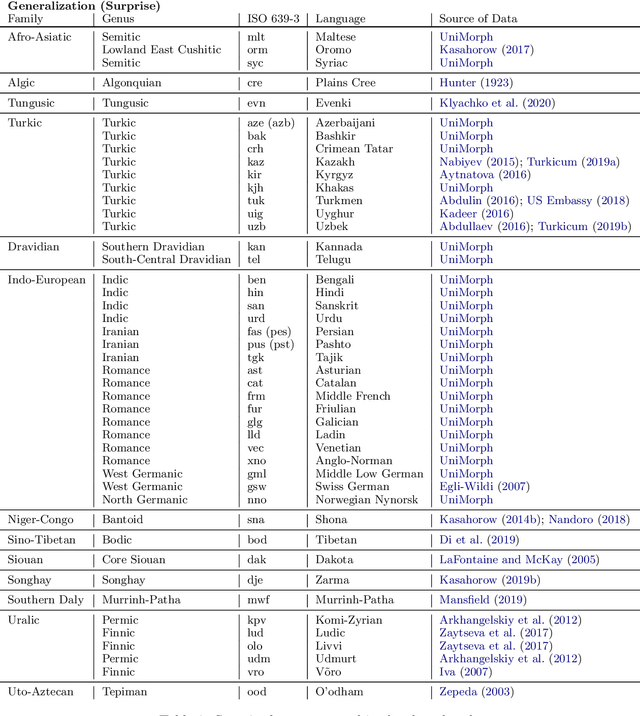
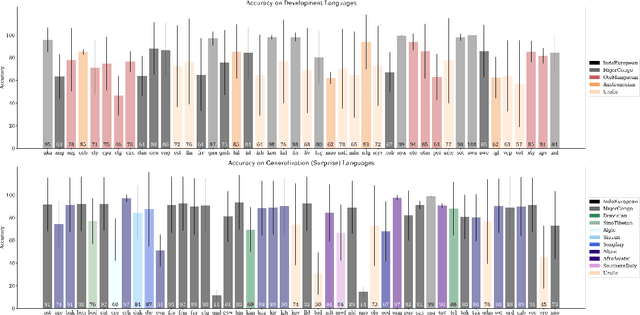
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.
Don't Forget the Long Tail! A Comprehensive Analysis of Morphological Generalization in Bilingual Lexicon Induction
Sep 06, 2019


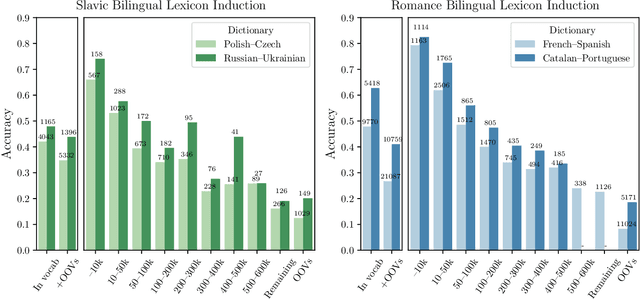
Human translators routinely have to translate rare inflections of words - due to the Zipfian distribution of words in a language. When translating from Spanish, a good translator would have no problem identifying the proper translation of a statistically rare inflection such as habl\'aramos. Note the lexeme itself, hablar, is relatively common. In this work, we investigate whether state-of-the-art bilingual lexicon inducers are capable of learning this kind of generalization. We introduce 40 morphologically complete dictionaries in 10 languages and evaluate three of the state-of-the-art models on the task of translation of less frequent morphological forms. We demonstrate that the performance of state-of-the-art models drops considerably when evaluated on infrequent morphological inflections and then show that adding a simple morphological constraint at training time improves the performance, proving that the bilingual lexicon inducers can benefit from better encoding of morphology.