 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Classification of Long Documents Using Transformers
Mar 21, 2022
Several methods have been proposed for classifying long textual documents using Transformers. However, there is a lack of consensus on a benchmark to enable a fair comparison among different approaches. In this paper, we provide a comprehensive evaluation of the relative efficacy measured against various baselines and diverse datasets -- both in terms of accuracy as well as time and space overheads. Our datasets cover binary, multi-class, and multi-label classification tasks and represent various ways information is organized in a long text (e.g. information that is critical to making the classification decision is at the beginning or towards the end of the document). Our results show that more complex models often fail to outperform simple baselines and yield inconsistent performance across datasets. These findings emphasize the need for future studies to consider comprehensive baselines and datasets that better represent the task of long document classification to develop robust models.
Quantifying Social Biases in NLP: A Generalization and Empirical Comparison of Extrinsic Fairness Metrics
Jun 28, 2021
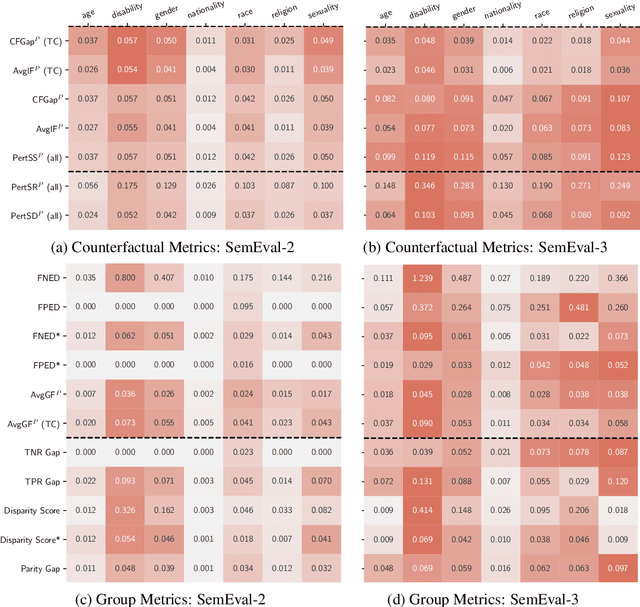
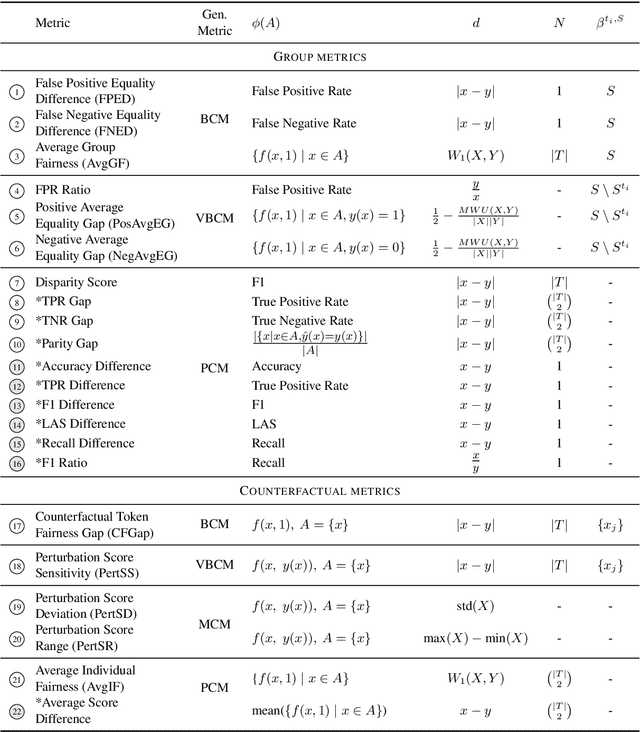
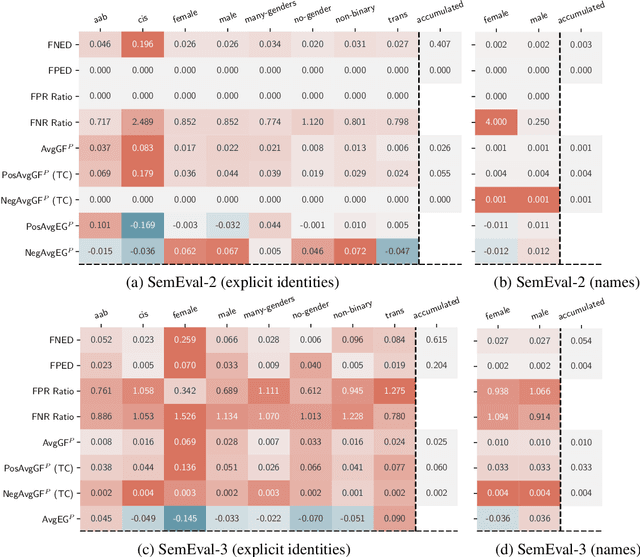
Measuring bias is key for better understanding and addressing unfairness in NLP/ML models. This is often done via fairness metrics which quantify the differences in a model's behaviour across a range of demographic groups. In this work, we shed more light on the differences and similarities between the fairness metrics used in NLP. First, we unify a broad range of existing metrics under three generalized fairness metrics, revealing the connections between them. Next, we carry out an extensive empirical comparison of existing metrics and demonstrate that the observed differences in bias measurement can be systematically explained via differences in parameter choices for our generalized metrics.
The USFD Spoken Language Translation System for IWSLT 2014
Sep 13, 2015
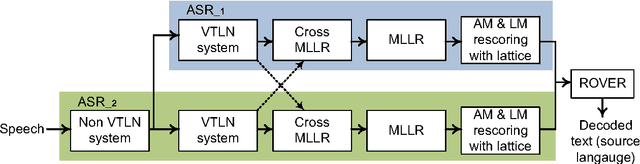
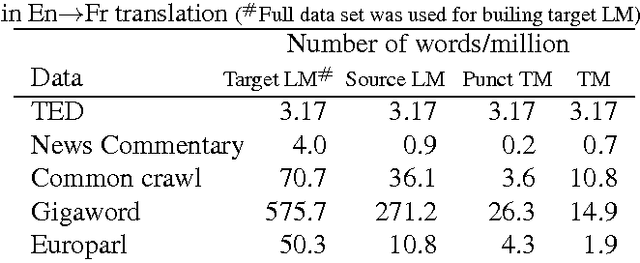
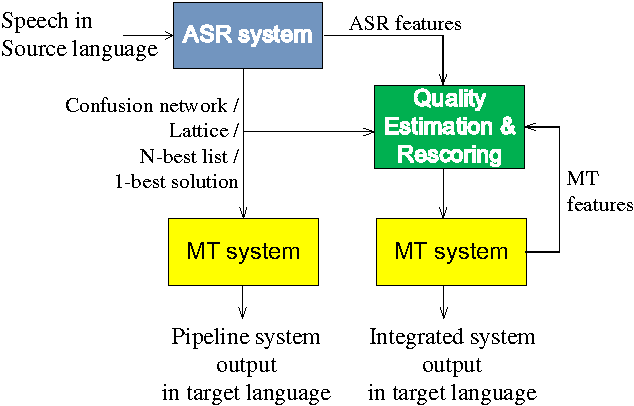
The University of Sheffield (USFD) participated in the International Workshop for Spoken Language Translation (IWSLT) in 2014. In this paper, we will introduce the USFD SLT system for IWSLT. Automatic speech recognition (ASR) is achieved by two multi-pass deep neural network systems with adaptation and rescoring techniques. Machine translation (MT) is achieved by a phrase-based system. The USFD primary system incorporates state-of-the-art ASR and MT techniques and gives a BLEU score of 23.45 and 14.75 on the English-to-French and English-to-German speech-to-text translation task with the IWSLT 2014 data. The USFD contrastive systems explore the integration of ASR and MT by using a quality estimation system to rescore the ASR outputs, optimising towards better translation. This gives a further 0.54 and 0.26 BLEU improvement respectively on the IWSLT 2012 and 2014 evaluation data.