Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Social Biases in NLP: A Generalization and Empirical Comparison of Extrinsic Fairness Metrics
Paper and Code
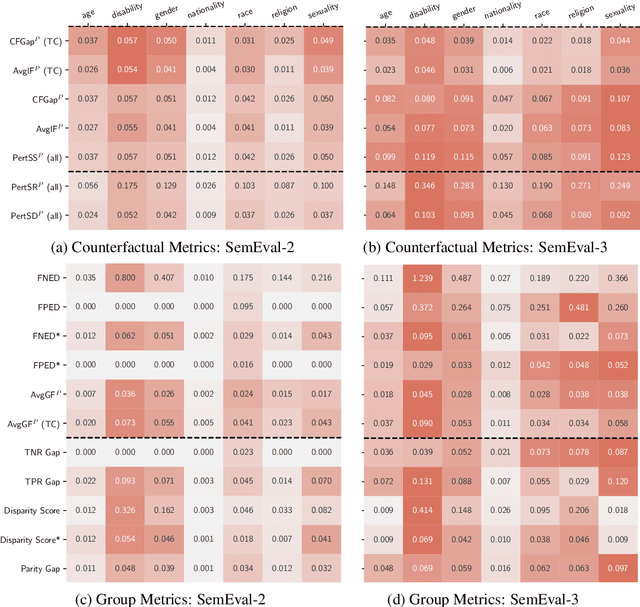
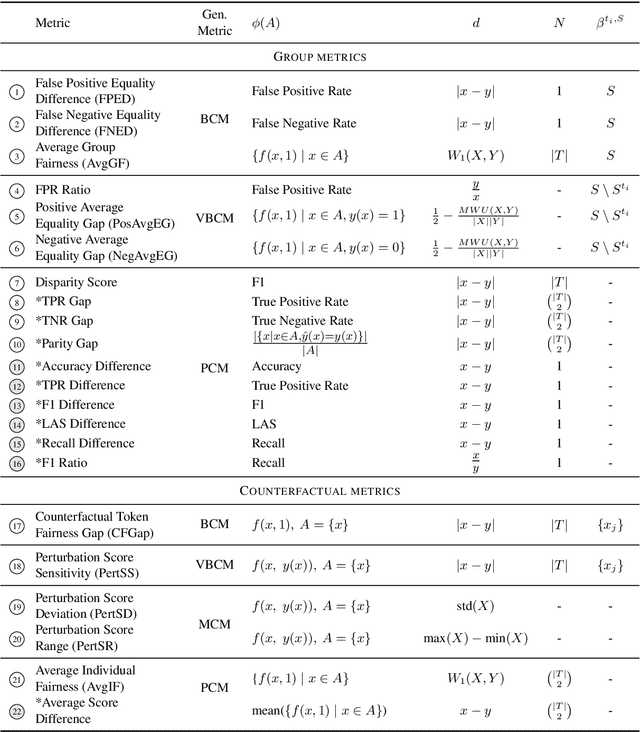
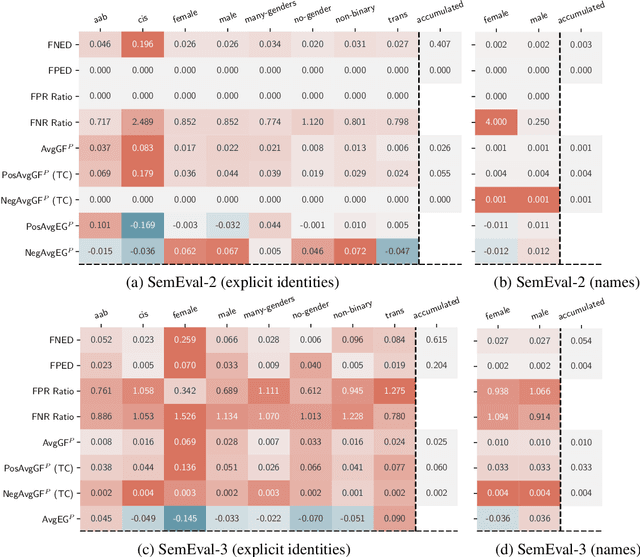
Measuring bias is key for better understanding and addressing unfairness in NLP/ML models. This is often done via fairness metrics which quantify the differences in a model's behaviour across a range of demographic groups. In this work, we shed more light on the differences and similarities between the fairness metrics used in NLP. First, we unify a broad range of existing metrics under three generalized fairness metrics, revealing the connections between them. Next, we carry out an extensive empirical comparison of existing metrics and demonstrate that the observed differences in bias measurement can be systematically explained via differences in parameter choices for our generalized metrics.
* Accepted for publication in Transaction of the Association for
Computational Linguistics (TACL), 2021. The arXiv version is a pre-MIT Press
publication version
View paper on