 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHipoRank: Incorporating Hierarchical and Positional Information into Graph-based Unsupervised Long Document Extractive Summarization
May 01, 2020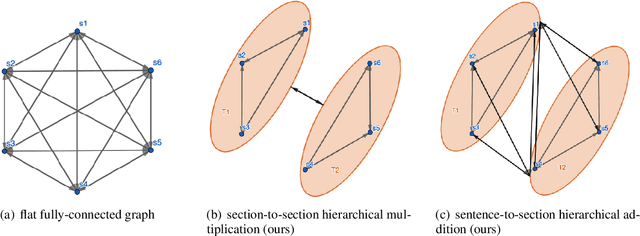
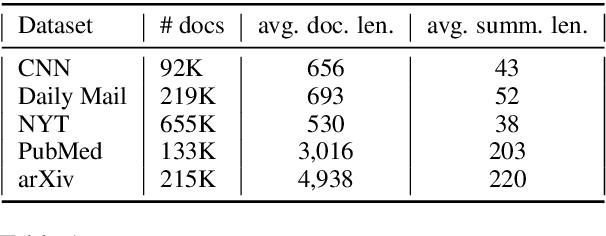
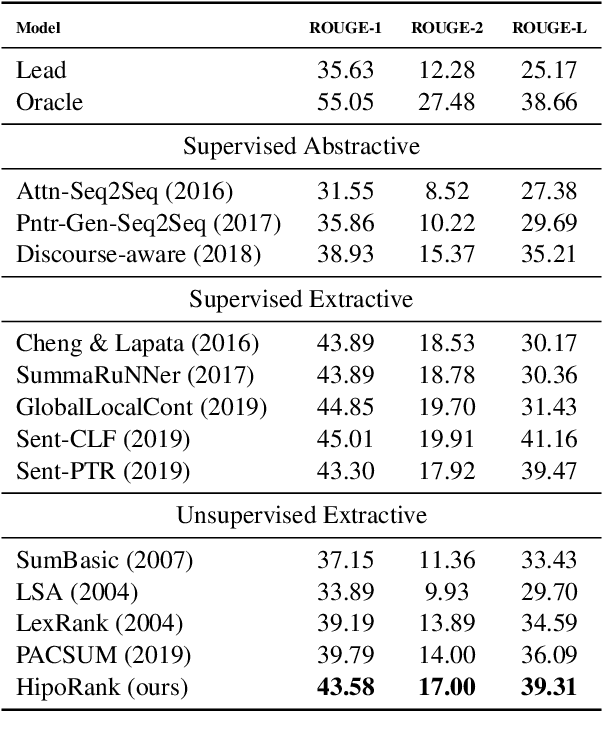
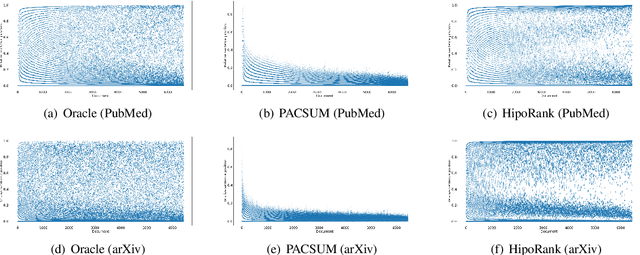
We propose a novel graph-based ranking model for unsupervised extractive summarization of long documents. Graph-based ranking models typically represent documents as undirected fully-connected graphs, where a node is a sentence, an edge is weighted based on sentence-pair similarity, and sentence importance is measured via node centrality. Our method leverages positional and hierarchical information grounded in discourse structure to augment a document's graph representation with hierarchy and directionality. Experimental results on PubMed and arXiv datasets show that our approach outperforms strong unsupervised baselines by wide margins and performs comparably to some of the state-of-the-art supervised models that are trained on hundreds of thousands of examples. In addition, we find that our method provides comparable improvements with various distributional sentence representations; including BERT and RoBERTa models fine-tuned on sentence similarity.