 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Flow-based Domain Randomization for Learning and Sequencing Robotic Skills
Feb 03, 2025



Domain randomization in reinforcement learning is an established technique for increasing the robustness of control policies trained in simulation. By randomizing environment properties during training, the learned policy can become robust to uncertainties along the randomized dimensions. While the environment distribution is typically specified by hand, in this paper we investigate automatically discovering a sampling distribution via entropy-regularized reward maximization of a normalizing-flow-based neural sampling distribution. We show that this architecture is more flexible and provides greater robustness than existing approaches that learn simpler, parameterized sampling distributions, as demonstrated in six simulated and one real-world robotics domain. Lastly, we explore how these learned sampling distributions, combined with a privileged value function, can be used for out-of-distribution detection in an uncertainty-aware multi-step manipulation planner.
Semi-Supervised Neural Processes for Articulated Object Interactions
Nov 28, 2024



The scarcity of labeled action data poses a considerable challenge for developing machine learning algorithms for robotic object manipulation. It is expensive and often infeasible for a robot to interact with many objects. Conversely, visual data of objects, without interaction, is abundantly available and can be leveraged for pretraining and feature extraction. However, current methods that rely on image data for pretraining do not easily adapt to task-specific predictions, since the learned features are not guaranteed to be relevant. This paper introduces the Semi-Supervised Neural Process (SSNP): an adaptive reward-prediction model designed for scenarios in which only a small subset of objects have labeled interaction data. In addition to predicting reward labels, the latent-space of the SSNP is jointly trained with an autoencoding objective using passive data from a much larger set of objects. Jointly training with both types of data allows the model to focus more effectively on generalizable features and minimizes the need for extensive retraining, thereby reducing computational demands. The efficacy of SSNP is demonstrated through a door-opening task, leading to better performance than other semi-supervised methods, and only using a fraction of the data compared to other adaptive models.
FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty
Aug 08, 2024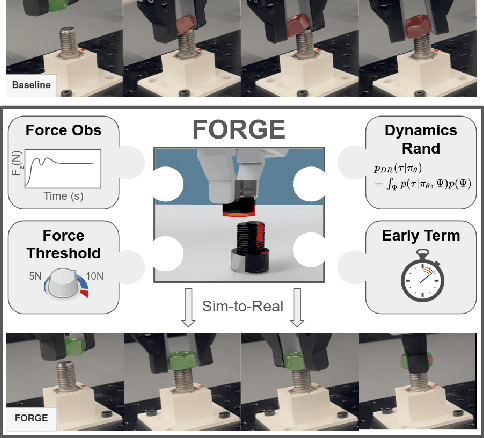

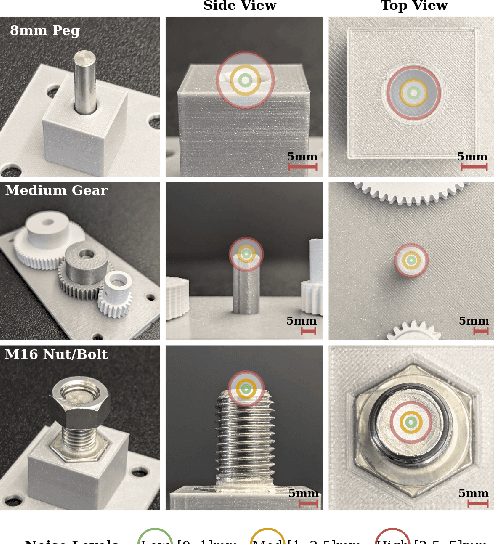
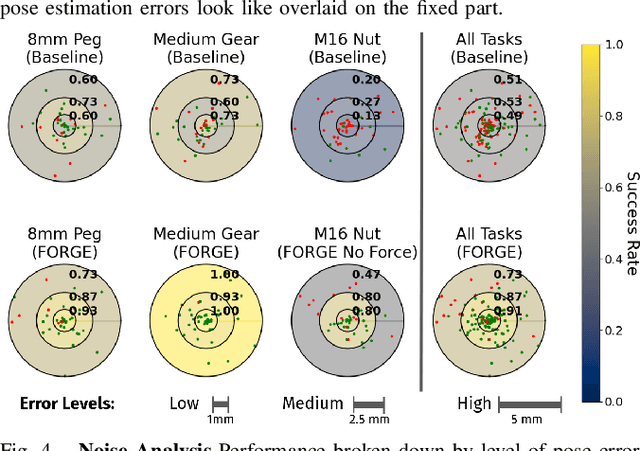
We present FORGE, a method that enables sim-to-real transfer of contact-rich manipulation policies in the presence of significant pose uncertainty. FORGE combines a force threshold mechanism with a dynamics randomization scheme during policy learning in simulation, to enable the robust transfer of the learned policies to the real robot. At deployment, FORGE policies, conditioned on a maximum allowable force, adaptively perform contact-rich tasks while respecting the specified force threshold, regardless of the controller gains. Additionally, FORGE autonomously predicts a termination action once the task has succeeded. We demonstrate that FORGE can be used to learn a variety of robust contact-rich policies, enabling multi-stage assembly of a planetary gear system, which requires success across three assembly tasks: nut-threading, insertion, and gear meshing. Project website can be accessed at https://noseworm.github.io/forge/.
Bayes3D: fast learning and inference in structured generative models of 3D objects and scenes
Dec 14, 2023



Robots cannot yet match humans' ability to rapidly learn the shapes of novel 3D objects and recognize them robustly despite clutter and occlusion. We present Bayes3D, an uncertainty-aware perception system for structured 3D scenes, that reports accurate posterior uncertainty over 3D object shape, pose, and scene composition in the presence of clutter and occlusion. Bayes3D delivers these capabilities via a novel hierarchical Bayesian model for 3D scenes and a GPU-accelerated coarse-to-fine sequential Monte Carlo algorithm. Quantitative experiments show that Bayes3D can learn 3D models of novel objects from just a handful of views, recognizing them more robustly and with orders of magnitude less training data than neural baselines, and tracking 3D objects faster than real time on a single GPU. We also demonstrate that Bayes3D learns complex 3D object models and accurately infers 3D scene composition when used on a Panda robot in a tabletop scenario.
Structured Latent Variable Models for Articulated Object Interaction
May 26, 2023



In this paper, we investigate a scenario in which a robot learns a low-dimensional representation of a door given a video of the door opening or closing. This representation can be used to infer door-related parameters and predict the outcomes of interacting with the door. Current machine learning based approaches in the doors domain are based primarily on labelled datasets. However, the large quantity of available door data suggests the feasibility of a semisupervised approach based on pretraining. To exploit the hierarchical structure of the dataset where each door has multiple associated images, we pretrain with a structured latent variable model known as a neural statistician. The neural satsitician enforces separation between shared context-level variables (common across all images associated with the same door) and instance-level variables (unique to each individual image). We first demonstrate that the neural statistician is able to learn an embedding that enables reconstruction and sampling of realistic door images. Then, we evaluate the correspondence of the learned embeddings to human-interpretable parameters in a series of supervised inference tasks. It was found that a pretrained neural statistician encoder outperformed analogous context-free baselines when predicting door handedness, size, angle location, and configuration from door images. Finally, in a visual bandit door-opening task with a variety of door configuration, we found that neural statistician embeddings achieve lower regret than context-free baselines.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Artificial Intelligence Nomenclature Identified From Delphi Study on Key Issues Related to Trust and Barriers to Adoption for Autonomous Systems
Oct 14, 2022The rapid integration of artificial intelligence across traditional research domains has generated an amalgamation of nomenclature. As cross-discipline teams work together on complex machine learning challenges, finding a consensus of basic definitions in the literature is a more fundamental problem. As a step in the Delphi process to define issues with trust and barriers to the adoption of autonomous systems, our study first collected and ranked the top concerns from a panel of international experts from the fields of engineering, computer science, medicine, aerospace, and defence, with experience working with artificial intelligence. This document presents a summary of the literature definitions for nomenclature derived from expert feedback.
Active Learning of Abstract Plan Feasibility
Jul 01, 2021

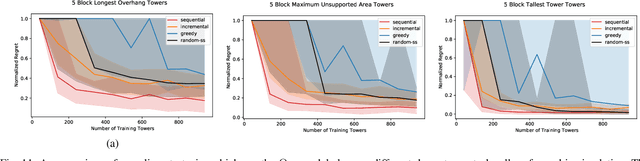
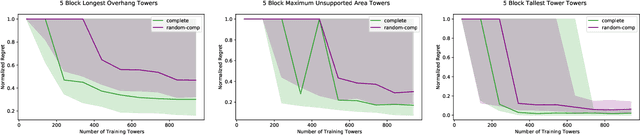
Long horizon sequential manipulation tasks are effectively addressed hierarchically: at a high level of abstraction the planner searches over abstract action sequences, and when a plan is found, lower level motion plans are generated. Such a strategy hinges on the ability to reliably predict that a feasible low level plan will be found which satisfies the abstract plan. However, computing Abstract Plan Feasibility (APF) is difficult because the outcome of a plan depends on real-world phenomena that are difficult to model, such as noise in estimation and execution. In this work, we present an active learning approach to efficiently acquire an APF predictor through task-independent, curious exploration on a robot. The robot identifies plans whose outcomes would be informative about APF, executes those plans, and learns from their successes or failures. Critically, we leverage an infeasible subsequence property to prune candidate plans in the active learning strategy, allowing our system to learn from less data. We evaluate our strategy in simulation and on a real Franka Emika Panda robot with integrated perception, experimentation, planning, and execution. In a stacking domain where objects have non-uniform mass distributions, we show that our system permits real robot learning of an APF model in four hundred self-supervised interactions, and that our learned model can be used effectively in multiple downstream tasks.
Visual Prediction of Priors for Articulated Object Interaction
Jun 06, 2020

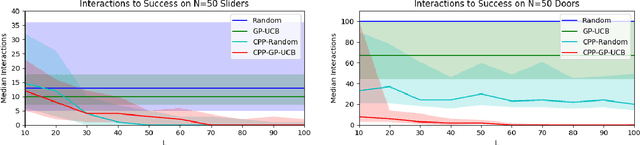
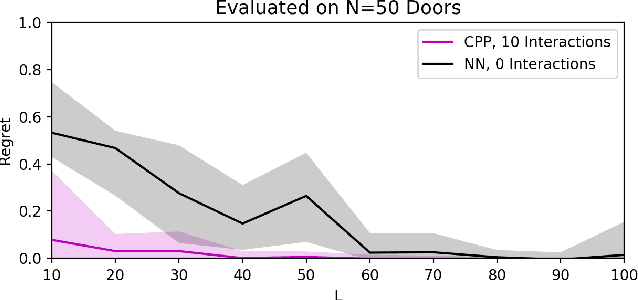
Exploration in novel settings can be challenging without prior experience in similar domains. However, humans are able to build on prior experience quickly and efficiently. Children exhibit this behavior when playing with toys. For example, given a toy with a yellow and blue door, a child will explore with no clear objective, but once they have discovered how to open the yellow door, they will most likely be able to open the blue door much faster. Adults also exhibit this behavior when entering new spaces such as kitchens. We develop a method, Contextual Prior Prediction, which provides a means of transferring knowledge between interactions in similar domains through vision. We develop agents that exhibit exploratory behavior with increasing efficiency, by learning visual features that are shared across environments, and how they correlate to actions. Our problem is formulated as a Contextual Multi-Armed Bandit where the contexts are images, and the robot has access to a parameterized action space. Given a novel object, the objective is to maximize reward with few interactions. A domain which strongly exhibits correlations between visual features and motion is kinemetically constrained mechanisms. We evaluate our method on simulated prismatic and revolute joints.