 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prediction of Priors for Articulated Object Interaction
Paper and Code
Jun 06, 2020

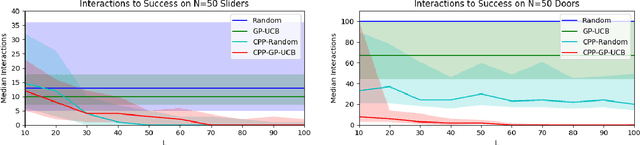
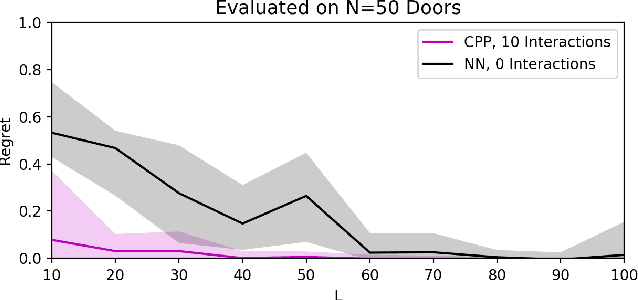
Exploration in novel settings can be challenging without prior experience in similar domains. However, humans are able to build on prior experience quickly and efficiently. Children exhibit this behavior when playing with toys. For example, given a toy with a yellow and blue door, a child will explore with no clear objective, but once they have discovered how to open the yellow door, they will most likely be able to open the blue door much faster. Adults also exhibit this behavior when entering new spaces such as kitchens. We develop a method, Contextual Prior Prediction, which provides a means of transferring knowledge between interactions in similar domains through vision. We develop agents that exhibit exploratory behavior with increasing efficiency, by learning visual features that are shared across environments, and how they correlate to actions. Our problem is formulated as a Contextual Multi-Armed Bandit where the contexts are images, and the robot has access to a parameterized action space. Given a novel object, the objective is to maximize reward with few interactions. A domain which strongly exhibits correlations between visual features and motion is kinemetically constrained mechanisms. We evaluate our method on simulated prismatic and revolute joints.