 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Bridge the Gap: Efficient Novelty Recovery with Planning and Reinforcement Learning
Sep 28, 2024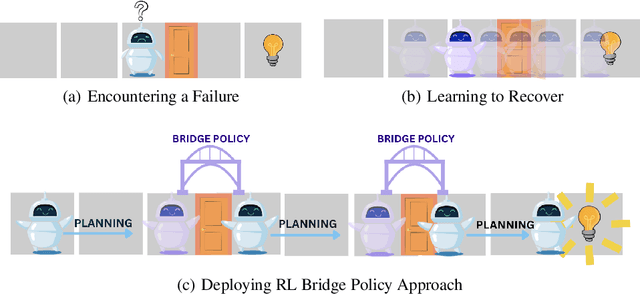

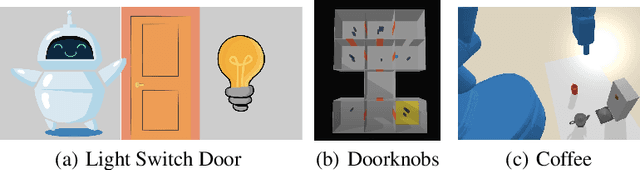
The real world is unpredictable. Therefore, to solve long-horizon decision-making problems with autonomous robots, we must construct agents that are capable of adapting to changes in the environment during deployment. Model-based planning approaches can enable robots to solve complex, long-horizon tasks in a variety of environments. However, such approaches tend to be brittle when deployed into an environment featuring a novel situation that their underlying model does not account for. In this work, we propose to learn a ``bridge policy'' via Reinforcement Learning (RL) to adapt to such novelties. We introduce a simple formulation for such learning, where the RL problem is constructed with a special ``CallPlanner'' action that terminates the bridge policy and hands control of the agent back to the planner. This allows the RL policy to learn the set of states in which querying the planner and following the returned plan will achieve the goal. We show that this formulation enables the agent to rapidly learn by leveraging the planner's knowledge to avoid challenging long-horizon exploration caused by sparse reward. In experiments across three different simulated domains of varying complexity, we demonstrate that our approach is able to learn policies that adapt to novelty more efficiently than several baselines, including a pure RL baseline. We also demonstrate that the learned bridge policy is generalizable in that it can be combined with the planner to enable the agent to solve more complex tasks with multiple instances of the encountered novelty.
Bi-Level Belief Space Search for Compliant Part Mating Under Uncertainty
Sep 24, 2024The problem of mating two parts with low clearance remains difficult for autonomous robots. We present bi-level belief assembly (BILBA), a model-based planner that computes a sequence of compliant motions which can leverage contact with the environment to reduce uncertainty and perform challenging assembly tasks with low clearance. Our approach is based on first deriving candidate contact schedules from the structure of the configuration space obstacle of the parts and then finding compliant motions that achieve the desired contacts. We demonstrate that BILBA can efficiently compute robust plans on multiple simulated tasks as well as a real robot rectangular peg-in-hole insertion task.
Compositional Generative Modeling: A Single Model is Not All You Need
Feb 02, 2024

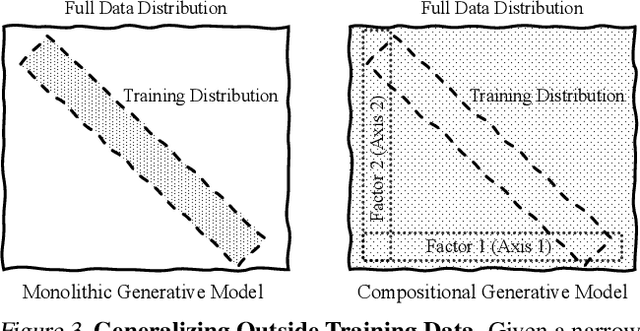

Large monolithic generative models trained on massive amounts of data have become an increasingly dominant approach in AI research. In this paper, we argue that we should instead construct large generative systems by composing smaller generative models together. We show how such a compositional generative approach enables us to learn distributions in a more data-efficient manner, enabling generalization to parts of the data distribution unseen at training time. We further show how this enables us to program and construct new generative models for tasks completely unseen at training. Finally, we show that in many cases, we can discover separate compositional components from data.
Video Language Planning
Oct 16, 2023We are interested in enabling visual planning for complex long-horizon tasks in the space of generated videos and language, leveraging recent advances in large generative models pretrained on Internet-scale data. To this end, we present video language planning (VLP), an algorithm that consists of a tree search procedure, where we train (i) vision-language models to serve as both policies and value functions, and (ii) text-to-video models as dynamics models. VLP takes as input a long-horizon task instruction and current image observation, and outputs a long video plan that provides detailed multimodal (video and language) specifications that describe how to complete the final task. VLP scales with increasing computation budget where more computation time results in improved video plans, and is able to synthesize long-horizon video plans across different robotics domains: from multi-object rearrangement, to multi-camera bi-arm dexterous manipulation. Generated video plans can be translated into real robot actions via goal-conditioned policies, conditioned on each intermediate frame of the generated video. Experiments show that VLP substantially improves long-horizon task success rates compared to prior methods on both simulated and real robots (across 3 hardware platforms).
Compositional Foundation Models for Hierarchical Planning
Sep 21, 2023



To make effective decisions in novel environments with long-horizon goals, it is crucial to engage in hierarchical reasoning across spatial and temporal scales. This entails planning abstract subgoal sequences, visually reasoning about the underlying plans, and executing actions in accordance with the devised plan through visual-motor control. We propose Compositional Foundation Models for Hierarchical Planning (HiP), a foundation model which leverages multiple expert foundation model trained on language, vision and action data individually jointly together to solve long-horizon tasks. We use a large language model to construct symbolic plans that are grounded in the environment through a large video diffusion model. Generated video plans are then grounded to visual-motor control, through an inverse dynamics model that infers actions from generated videos. To enable effective reasoning within this hierarchy, we enforce consistency between the models via iterative refinement. We illustrate the efficacy and adaptability of our approach in three different long-horizon table-top manipulation tasks.
Local Neural Descriptor Fields: Locally Conditioned Object Representations for Manipulation
Feb 07, 2023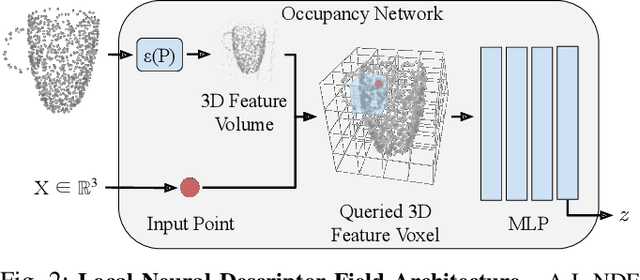

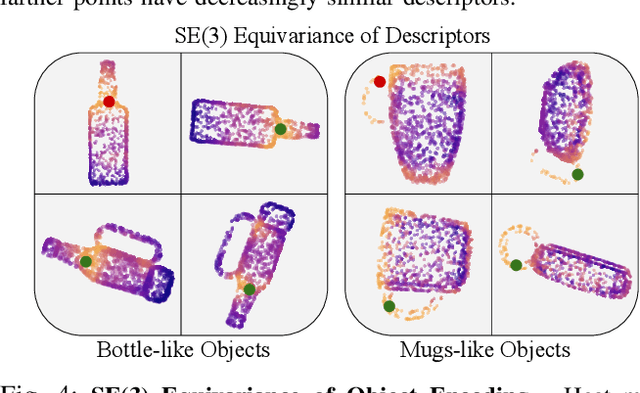
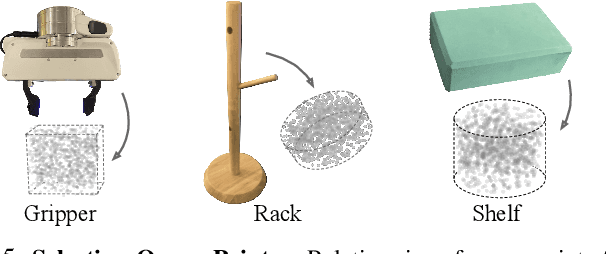
A robot operating in a household environment will see a wide range of unique and unfamiliar objects. While a system could train on many of these, it is infeasible to predict all the objects a robot will see. In this paper, we present a method to generalize object manipulation skills acquired from a limited number of demonstrations, to novel objects from unseen shape categories. Our approach, Local Neural Descriptor Fields (L-NDF), utilizes neural descriptors defined on the local geometry of the object to effectively transfer manipulation demonstrations to novel objects at test time. In doing so, we leverage the local geometry shared between objects to produce a more general manipulation framework. We illustrate the efficacy of our approach in manipulating novel objects in novel poses -- both in simulation and in the real world.
Task-Directed Exploration in Continuous POMDPs for Robotic Manipulation of Articulated Objects
Dec 08, 2022
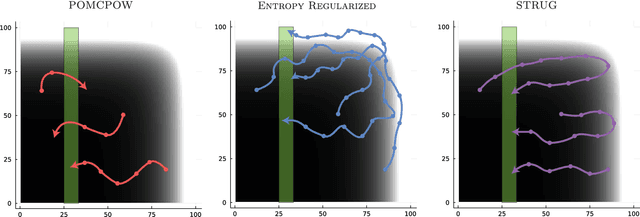


Representing and reasoning about uncertainty is crucial for autonomous agents acting in partially observable environments with noisy sensors. Partially observable Markov decision processes (POMDPs) serve as a general framework for representing problems in which uncertainty is an important factor. Online sample-based POMDP methods have emerged as efficient approaches to solving large POMDPs and have been shown to extend to continuous domains. However, these solutions struggle to find long-horizon plans in problems with significant uncertainty. Exploration heuristics can help guide planning, but many real-world settings contain significant task-irrelevant uncertainty that might distract from the task objective. In this paper, we propose STRUG, an online POMDP solver capable of handling domains that require long-horizon planning with significant task-relevant and task-irrelevant uncertainty. We demonstrate our solution on several temporally extended versions of toy POMDP problems as well as robotic manipulation of articulated objects using a neural perception frontend to construct a distribution of possible models. Our results show that STRUG outperforms the current sample-based online POMDP solvers on several tasks.
Active Learning of Abstract Plan Feasibility
Jul 01, 2021

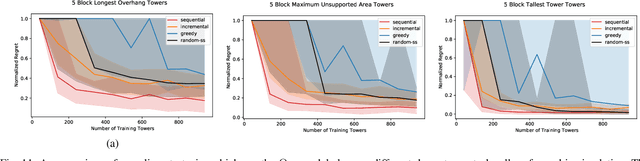
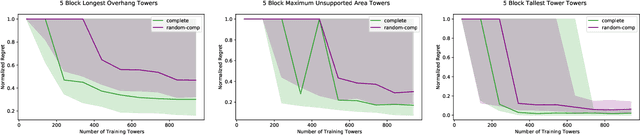
Long horizon sequential manipulation tasks are effectively addressed hierarchically: at a high level of abstraction the planner searches over abstract action sequences, and when a plan is found, lower level motion plans are generated. Such a strategy hinges on the ability to reliably predict that a feasible low level plan will be found which satisfies the abstract plan. However, computing Abstract Plan Feasibility (APF) is difficult because the outcome of a plan depends on real-world phenomena that are difficult to model, such as noise in estimation and execution. In this work, we present an active learning approach to efficiently acquire an APF predictor through task-independent, curious exploration on a robot. The robot identifies plans whose outcomes would be informative about APF, executes those plans, and learns from their successes or failures. Critically, we leverage an infeasible subsequence property to prune candidate plans in the active learning strategy, allowing our system to learn from less data. We evaluate our strategy in simulation and on a real Franka Emika Panda robot with integrated perception, experimentation, planning, and execution. In a stacking domain where objects have non-uniform mass distributions, we show that our system permits real robot learning of an APF model in four hundred self-supervised interactions, and that our learned model can be used effectively in multiple downstream tasks.
Learning Online Data Association
Nov 06, 2020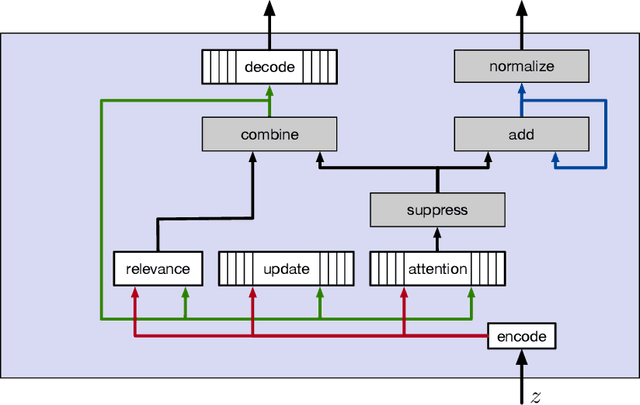
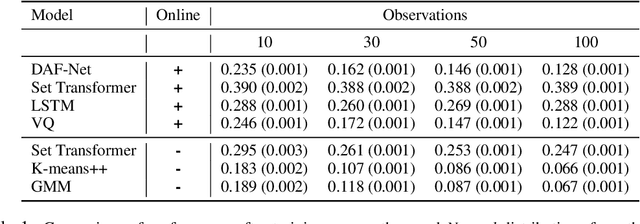
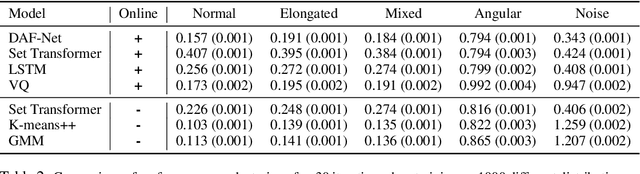

When an agent interacts with a complex environment, it receives a stream of percepts in which it may detect entities, such as objects or people. To build up a coherent, low-variance estimate of the underlying state, it is necessary to fuse information from multiple detections over time. To do this fusion, the agent must decide which detections to associate with one another. We address this data-association problem in the setting of an online filter, in which each observation is processed by aggregating into an existing object hypothesis. Classic methods with strong probabilistic foundations exist, but they are computationally expensive and require models that can be difficult to acquire. In this work, we use the deep-learning tools of sparse attention and representation learning to learn a machine that processes a stream of detections and outputs a set of hypotheses about objects in the world. We evaluate this approach on simple clustering problems, problems with dynamics, and a complex image-based domain. We find that it generalizes well from short to long observation sequences and from a few to many hypotheses, outperforming other learning approaches and classical non-learning methods.
Residual Policy Learning
Jan 03, 2019


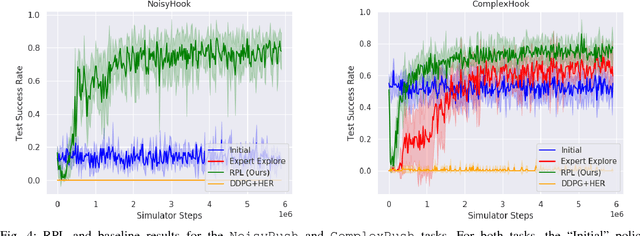
We present Residual Policy Learning (RPL): a simple method for improving nondifferentiable policies using model-free deep reinforcement learning. RPL thrives in complex robotic manipulation tasks where good but imperfect controllers are available. In these tasks, reinforcement learning from scratch remains data-inefficient or intractable, but learning a residual on top of the initial controller can yield substantial improvements. We study RPL in six challenging MuJoCo tasks involving partial observability, sensor noise, model misspecification, and controller miscalibration. For initial controllers, we consider both hand-designed policies and model-predictive controllers with known or learned transition models. By combining learning with control algorithms, RPL can perform long-horizon, sparse-reward tasks for which reinforcement learning alone fails. Moreover, we find that RPL consistently and substantially improves on the initial controllers. We argue that RPL is a promising approach for combining the complementary strengths of deep reinforcement learning and robotic control, pushing the boundaries of what either can achieve independently. Video and code at https://k-r-allen.github.io/residual-policy-learning/.