 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Just in Time" World Modeling Supports Human Planning and Reasoning
Jan 20, 2026Probabilistic mental simulation is thought to play a key role in human reasoning, planning, and prediction, yet the demands of simulation in complex environments exceed realistic human capacity limits. A theory with growing evidence is that people simulate using simplified representations of the environment that abstract away from irrelevant details, but it is unclear how people determine these simplifications efficiently. Here, we present a "Just-in-Time" framework for simulation-based reasoning that demonstrates how such representations can be constructed online with minimal added computation. The model uses a tight interleaving of simulation, visual search, and representation modification, with the current simulation guiding where to look and visual search flagging objects that should be encoded for subsequent simulation. Despite only ever encoding a small subset of objects, the model makes high-utility predictions. We find strong empirical support for this account over alternative models in a grid-world planning task and a physical reasoning task across a range of behavioral measures. Together, these results offer a concrete algorithmic account of how people construct reduced representations to support efficient mental simulation.
Empowerment Gain and Causal Model Construction: Children and adults are sensitive to controllability and variability in their causal interventions
Dec 09, 2025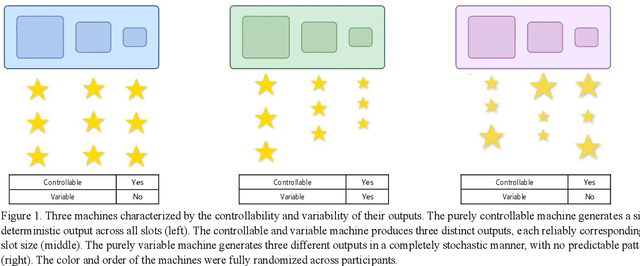

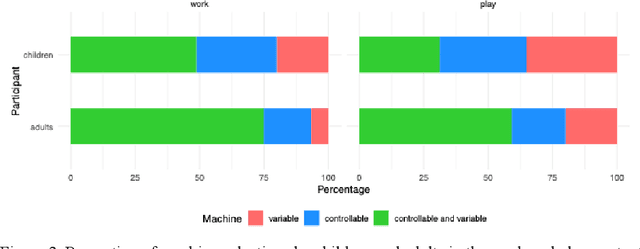

Learning about the causal structure of the world is a fundamental problem for human cognition. Causal models and especially causal learning have proved to be difficult for large pretrained models using standard techniques of deep learning. In contrast, cognitive scientists have applied advances in our formal understanding of causation in computer science, particularly within the Causal Bayes Net formalism, to understand human causal learning. In the very different tradition of reinforcement learning, researchers have described an intrinsic reward signal called "empowerment" which maximizes mutual information between actions and their outcomes. "Empowerment" may be an important bridge between classical Bayesian causal learning and reinforcement learning and may help to characterize causal learning in humans and enable it in machines. If an agent learns an accurate causal world model, they will necessarily increase their empowerment, and increasing empowerment will lead to a more accurate causal world model. Empowerment may also explain distinctive features of childrens causal learning, as well as providing a more tractable computational account of how that learning is possible. In an empirical study, we systematically test how children and adults use cues to empowerment to infer causal relations, and design effective causal interventions.
Direct Motion Models for Assessing Generated Videos
Apr 30, 2025A current limitation of video generative video models is that they generate plausible looking frames, but poor motion -- an issue that is not well captured by FVD and other popular methods for evaluating generated videos. Here we go beyond FVD by developing a metric which better measures plausible object interactions and motion. Our novel approach is based on auto-encoding point tracks and yields motion features that can be used to not only compare distributions of videos (as few as one generated and one ground truth, or as many as two datasets), but also for evaluating motion of single videos. We show that using point tracks instead of pixel reconstruction or action recognition features results in a metric which is markedly more sensitive to temporal distortions in synthetic data, and can predict human evaluations of temporal consistency and realism in generated videos obtained from open-source models better than a wide range of alternatives. We also show that by using a point track representation, we can spatiotemporally localize generative video inconsistencies, providing extra interpretability of generated video errors relative to prior work. An overview of the results and link to the code can be found on the project page: http://trajan-paper.github.io.
Decoupling the components of geometric understanding in Vision Language Models
Mar 05, 2025Understanding geometry relies heavily on vision. In this work, we evaluate whether state-of-the-art vision language models (VLMs) can understand simple geometric concepts. We use a paradigm from cognitive science that isolates visual understanding of simple geometry from the many other capabilities it is often conflated with such as reasoning and world knowledge. We compare model performance with human adults from the USA, as well as with prior research on human adults without formal education from an Amazonian indigenous group. We find that VLMs consistently underperform both groups of human adults, although they succeed with some concepts more than others. We also find that VLM geometric understanding is more brittle than human understanding, and is not robust when tasks require mental rotation. This work highlights interesting differences in the origin of geometric understanding in humans and machines -- e.g. from printed materials used in formal education vs. interactions with the physical world or a combination of the two -- and a small step toward understanding these differences.
Economics of Sourcing Human Data
Feb 11, 2025Progress in AI has relied on human-generated data, from annotator marketplaces to the wider Internet. However, the widespread use of large language models now threatens the quality and integrity of human-generated data on these very platforms. We argue that this issue goes beyond the immediate challenge of filtering AI-generated content--it reveals deeper flaws in how data collection systems are designed. Existing systems often prioritize speed, scale, and efficiency at the cost of intrinsic human motivation, leading to declining engagement and data quality. We propose that rethinking data collection systems to align with contributors' intrinsic motivations--rather than relying solely on external incentives--can help sustain high-quality data sourcing at scale while maintaining contributor trust and long-term participation.
The in-context inductive biases of vision-language models differ across modalities
Feb 03, 2025Inductive biases are what allow learners to make guesses in the absence of conclusive evidence. These biases have often been studied in cognitive science using concepts or categories -- e.g. by testing how humans generalize a new category from a few examples that leave the category boundary ambiguous. We use these approaches to study generalization in foundation models during in-context learning. Modern foundation models can condition on both vision and text, and differences in how they interpret and learn from these different modalities is an emerging area of study. Here, we study how their generalizations vary by the modality in which stimuli are presented, and the way the stimuli are described in text. We study these biases with three different experimental paradigms, across three different vision-language models. We find that the models generally show some bias towards generalizing according to shape over color. This shape bias tends to be amplified when the examples are presented visually. By contrast, when examples are presented in text, the ordering of adjectives affects generalization. However, the extent of these effects vary across models and paradigms. These results help to reveal how vision-language models represent different types of inputs in context, and may have practical implications for the use of vision-language models.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
Diffusion Generative Inverse Design
Sep 18, 2023



Inverse design refers to the problem of optimizing the input of an objective function in order to enact a target outcome. For many real-world engineering problems, the objective function takes the form of a simulator that predicts how the system state will evolve over time, and the design challenge is to optimize the initial conditions that lead to a target outcome. Recent developments in learned simulation have shown that graph neural networks (GNNs) can be used for accurate, efficient, differentiable estimation of simulator dynamics, and support high-quality design optimization with gradient- or sampling-based optimization procedures. However, optimizing designs from scratch requires many expensive model queries, and these procedures exhibit basic failures on either non-convex or high-dimensional problems. In this work, we show how denoising diffusion models (DDMs) can be used to solve inverse design problems efficiently and propose a particle sampling algorithm for further improving their efficiency. We perform experiments on a number of fluid dynamics design challenges, and find that our approach substantially reduces the number of calls to the simulator compared to standard techniques.
Improving Dual-Encoder Training through Dynamic Indexes for Negative Mining
Mar 27, 2023



Dual encoder models are ubiquitous in modern classification and retrieval. Crucial for training such dual encoders is an accurate estimation of gradients from the partition function of the softmax over the large output space; this requires finding negative targets that contribute most significantly ("hard negatives"). Since dual encoder model parameters change during training, the use of traditional static nearest neighbor indexes can be sub-optimal. These static indexes (1) periodically require expensive re-building of the index, which in turn requires (2) expensive re-encoding of all targets using updated model parameters. This paper addresses both of these challenges. First, we introduce an algorithm that uses a tree structure to approximate the softmax with provable bounds and that dynamically maintains the tree. Second, we approximate the effect of a gradient update on target encodings with an efficient Nystrom low-rank approximation. In our empirical study on datasets with over twenty million targets, our approach cuts error by half in relation to oracle brute-force negative mining. Furthermore, our method surpasses prior state-of-the-art while using 150x less accelerator memory.
Residual Policy Learning
Jan 03, 2019


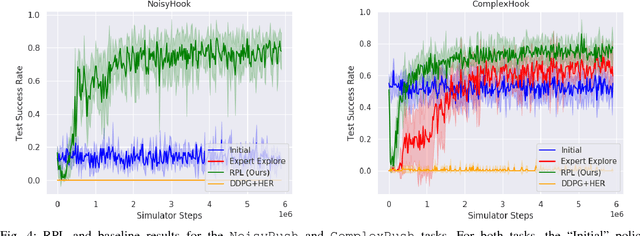
We present Residual Policy Learning (RPL): a simple method for improving nondifferentiable policies using model-free deep reinforcement learning. RPL thrives in complex robotic manipulation tasks where good but imperfect controllers are available. In these tasks, reinforcement learning from scratch remains data-inefficient or intractable, but learning a residual on top of the initial controller can yield substantial improvements. We study RPL in six challenging MuJoCo tasks involving partial observability, sensor noise, model misspecification, and controller miscalibration. For initial controllers, we consider both hand-designed policies and model-predictive controllers with known or learned transition models. By combining learning with control algorithms, RPL can perform long-horizon, sparse-reward tasks for which reinforcement learning alone fails. Moreover, we find that RPL consistently and substantially improves on the initial controllers. We argue that RPL is a promising approach for combining the complementary strengths of deep reinforcement learning and robotic control, pushing the boundaries of what either can achieve independently. Video and code at https://k-r-allen.github.io/residual-policy-learning/.