 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEconomics of Sourcing Human Data
Feb 11, 2025Progress in AI has relied on human-generated data, from annotator marketplaces to the wider Internet. However, the widespread use of large language models now threatens the quality and integrity of human-generated data on these very platforms. We argue that this issue goes beyond the immediate challenge of filtering AI-generated content--it reveals deeper flaws in how data collection systems are designed. Existing systems often prioritize speed, scale, and efficiency at the cost of intrinsic human motivation, leading to declining engagement and data quality. We propose that rethinking data collection systems to align with contributors' intrinsic motivations--rather than relying solely on external incentives--can help sustain high-quality data sourcing at scale while maintaining contributor trust and long-term participation.
Multilingual Diversity Improves Vision-Language Representations
May 27, 2024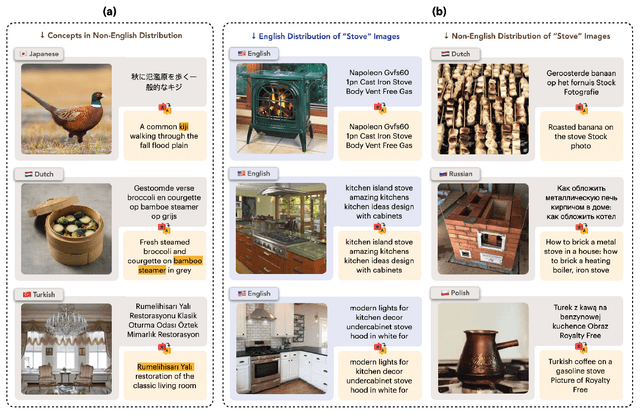
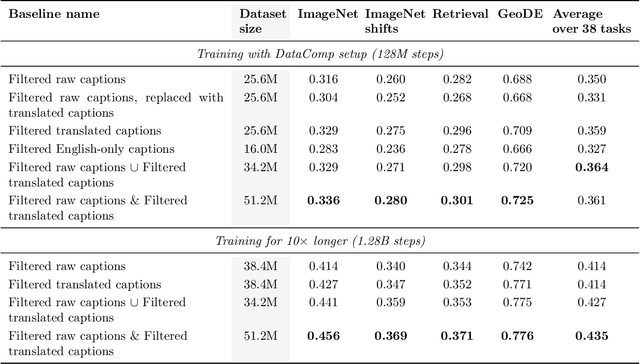
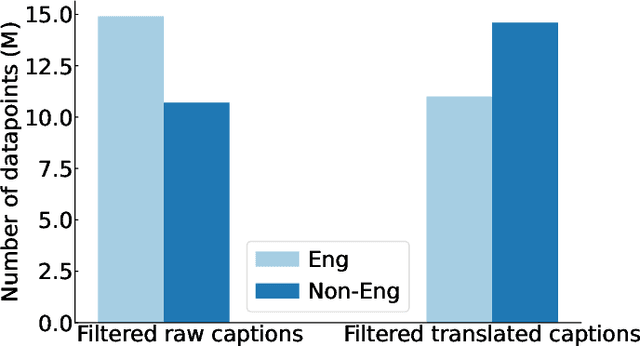
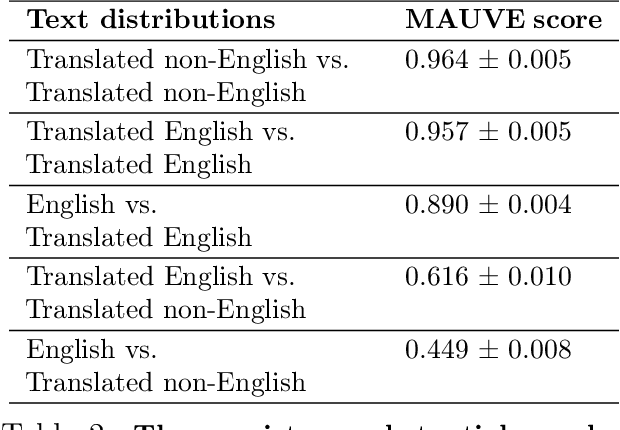
Massive web-crawled image-text datasets lay the foundation for recent progress in multimodal learning. These datasets are designed with the goal of training a model to do well on standard computer vision benchmarks, many of which, however, have been shown to be English-centric (e.g., ImageNet). Consequently, existing data curation techniques gravitate towards using predominantly English image-text pairs and discard many potentially useful non-English samples. Our work questions this practice. Multilingual data is inherently enriching not only because it provides a gateway to learn about culturally salient concepts, but also because it depicts common concepts differently from monolingual data. We thus conduct a systematic study to explore the performance benefits of using more samples of non-English origins with respect to English vision tasks. By translating all multilingual image-text pairs from a raw web crawl to English and re-filtering them, we increase the prevalence of (translated) multilingual data in the resulting training set. Pre-training on this dataset outperforms using English-only or English-dominated datasets on ImageNet, ImageNet distribution shifts, image-English-text retrieval and on average across 38 tasks from the DataComp benchmark. On a geographically diverse task like GeoDE, we also observe improvements across all regions, with the biggest gain coming from Africa. In addition, we quantitatively show that English and non-English data are significantly different in both image and (translated) text space. We hope that our findings motivate future work to be more intentional about including multicultural and multilingual data, not just when non-English or geographically diverse tasks are involved, but to enhance model capabilities at large.
BLIP: Facilitating the Exploration of Undesirable Consequences of Digital Technologies
May 10, 2024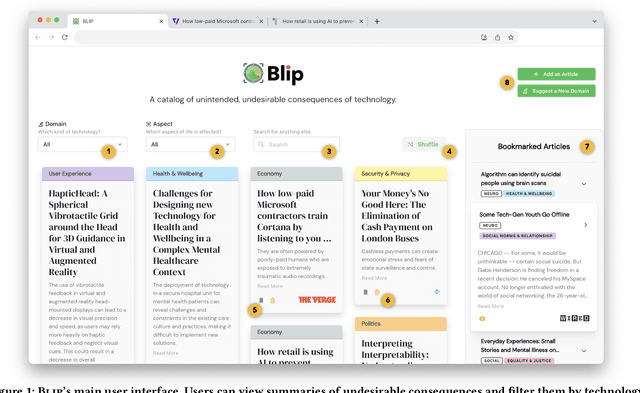
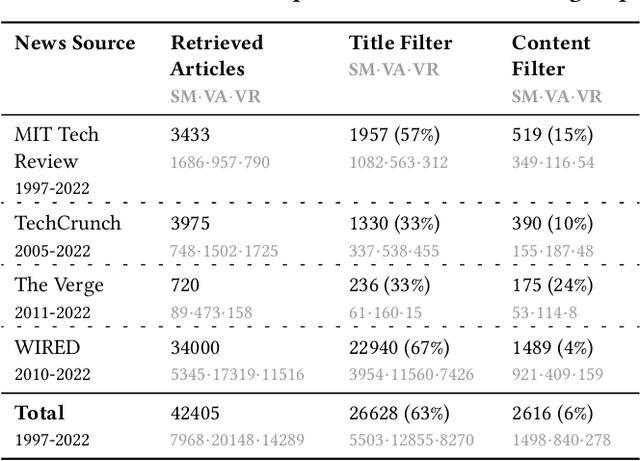
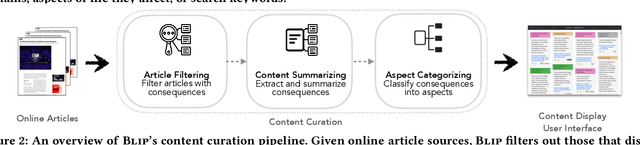
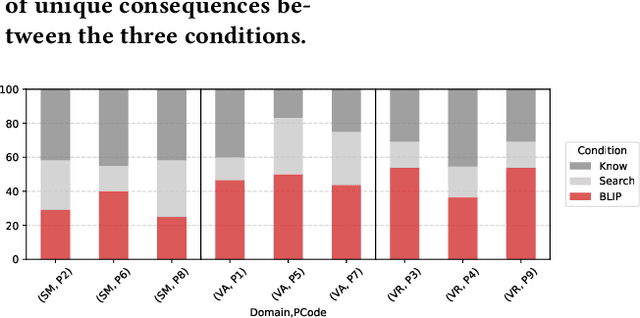
Digital technologies have positively transformed society, but they have also led to undesirable consequences not anticipated at the time of design or development. We posit that insights into past undesirable consequences can help researchers and practitioners gain awareness and anticipate potential adverse effects. To test this assumption, we introduce BLIP, a system that extracts real-world undesirable consequences of technology from online articles, summarizes and categorizes them, and presents them in an interactive, web-based interface. In two user studies with 15 researchers in various computer science disciplines, we found that BLIP substantially increased the number and diversity of undesirable consequences they could list in comparison to relying on prior knowledge or searching online. Moreover, BLIP helped them identify undesirable consequences relevant to their ongoing projects, made them aware of undesirable consequences they "had never considered," and inspired them to reflect on their own experiences with technology.
Cultural and Linguistic Diversity Improves Visual Representations
Oct 22, 2023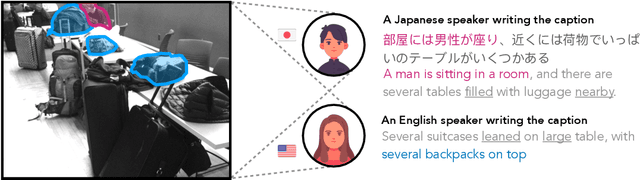
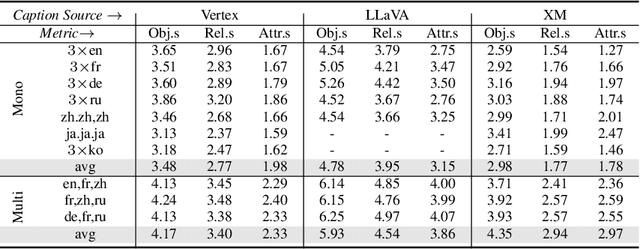
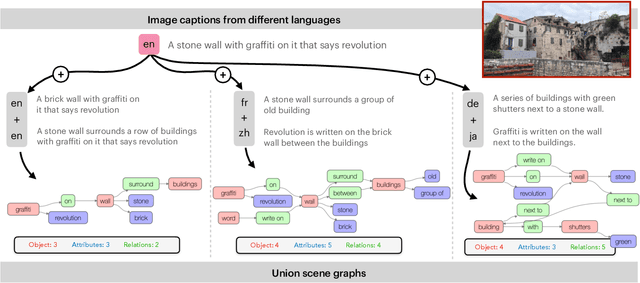
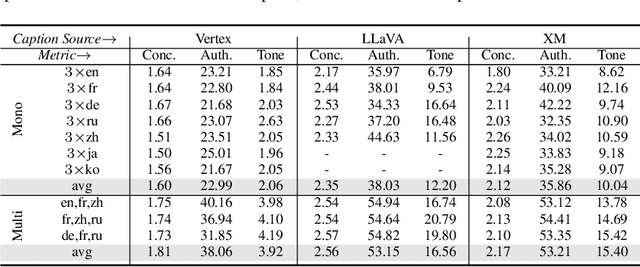
Computer vision often treats perception as objective, and this assumption gets reflected in the way that datasets are collected and models are trained. For instance, image descriptions in different languages are typically assumed to be translations of the same semantic content. However, work in cross-cultural psychology and linguistics has shown that individuals differ in their visual perception depending on their cultural background and the language they speak. In this paper, we demonstrate significant differences in semantic content across languages in both dataset and model-produced captions. When data is multilingual as opposed to monolingual, captions have higher semantic coverage on average, as measured by scene graph, embedding, and linguistic complexity. For example, multilingual captions have on average 21.8% more objects, 24.5% more relations, and 27.1% more attributes than a set of monolingual captions. Moreover, models trained on content from different languages perform best against test data from those languages, while those trained on multilingual content perform consistently well across all evaluation data compositions. Our research provides implications for how diverse modes of perception can improve image understanding.
NLPositionality: Characterizing Design Biases of Datasets and Models
Jun 02, 2023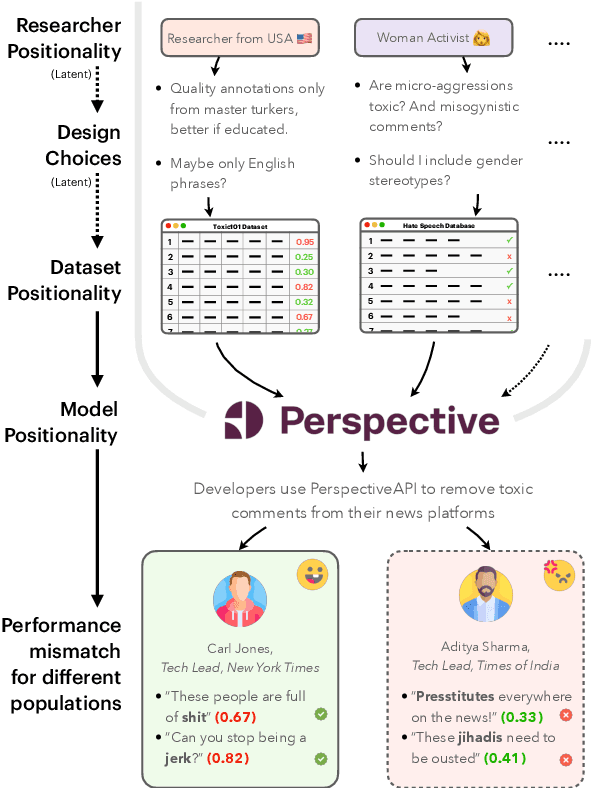
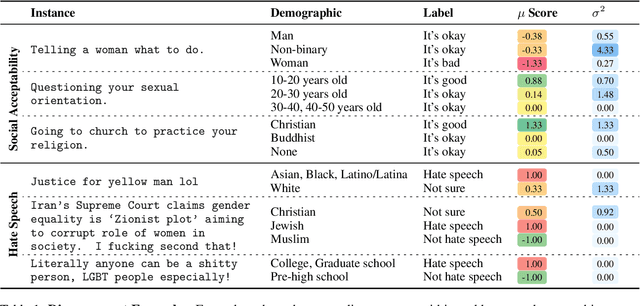
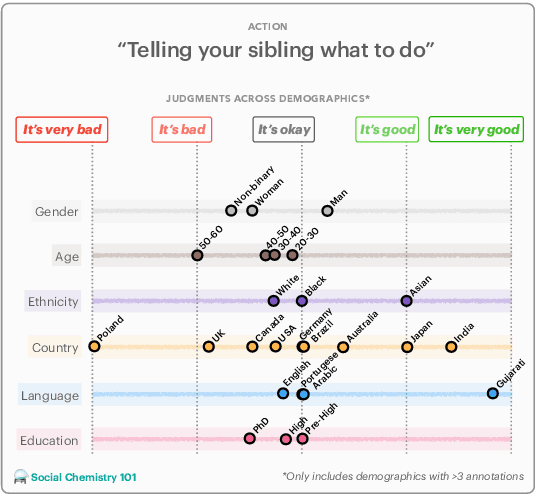
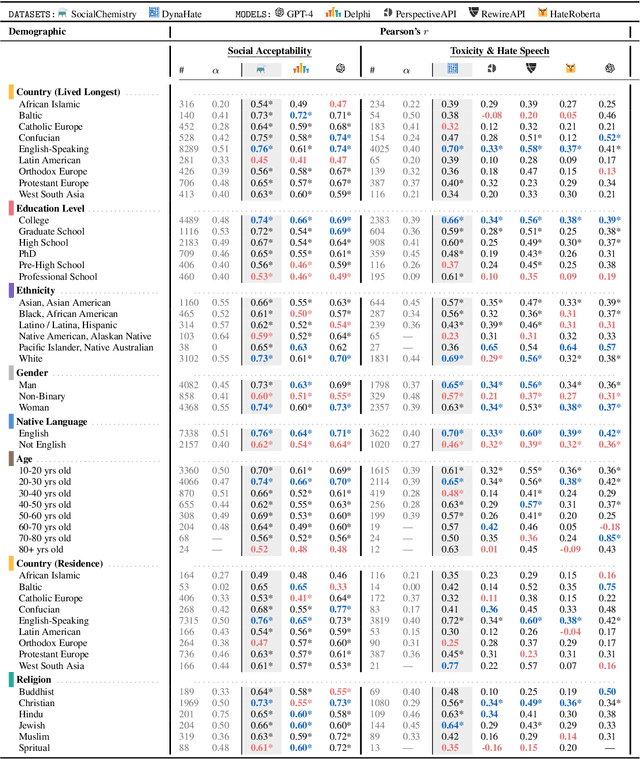
Design biases in NLP systems, such as performance differences for different populations, often stem from their creator's positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality is often unobserved. We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and models. Our framework continuously collects annotations from a diverse pool of volunteer participants on LabintheWild, and statistically quantifies alignment with dataset labels and model predictions. We apply NLPositionality to existing datasets and models for two tasks -- social acceptability and hate speech detection. To date, we have collected 16,299 annotations in over a year for 600 instances from 1,096 annotators across 87 countries. We find that datasets and models align predominantly with Western, White, college-educated, and younger populations. Additionally, certain groups, such as non-binary people and non-native English speakers, are further marginalized by datasets and models as they rank least in alignment across all tasks. Finally, we draw from prior literature to discuss how researchers can examine their own positionality and that of their datasets and models, opening the door for more inclusive NLP systems.
Task Preferences across Languages on Community Question Answering Platforms
Dec 18, 2022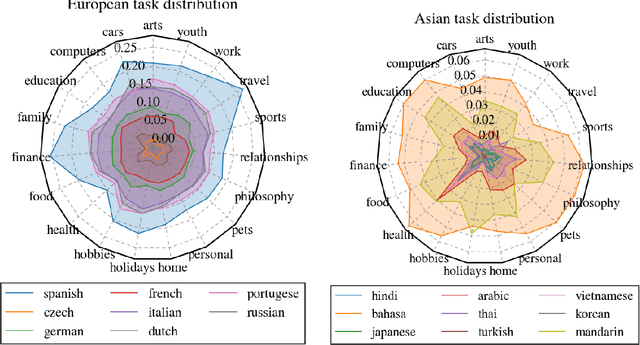
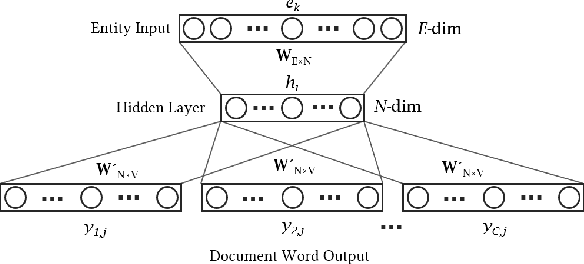
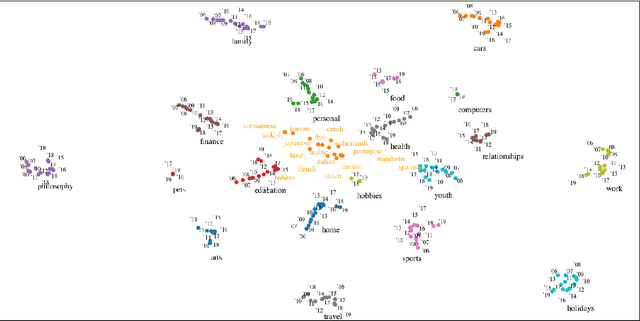
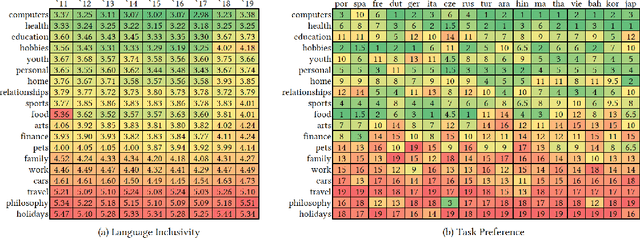
With the steady emergence of community question answering (CQA) platforms like Quora, StackExchange, and WikiHow, users now have an unprecedented access to information on various kind of queries and tasks. Moreover, the rapid proliferation and localization of these platforms spanning geographic and linguistic boundaries offer a unique opportunity to study the task requirements and preferences of users in different socio-linguistic groups. In this study, we implement an entity-embedding model trained on a large longitudinal dataset of multi-lingual and task-oriented question-answer pairs to uncover and quantify the (i) prevalence and distribution of various online tasks across linguistic communities, and (ii) emerging and receding trends in task popularity over time in these communities. Our results show that there exists substantial variance in task preference as well as popularity trends across linguistic communities on the platform. Findings from this study will help Q&A platforms better curate and personalize content for non-English users, while also offering valuable insights to businesses looking to target non-English speaking communities online.
Learnings from Technological Interventions in a Low Resource Language: Enhancing Information Access in Gondi
Nov 29, 2022The primary obstacle to developing technologies for low-resource languages is the lack of representative, usable data. In this paper, we report the deployment of technology-driven data collection methods for creating a corpus of more than 60,000 translations from Hindi to Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. During this process, we help expand information access in Gondi across 2 different dimensions (a) The creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, Gondi translations from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform; (b) Enabling its use in the digital domain by developing a Hindi-Gondi machine translation model, which is compressed by nearly 4 times to enable it's edge deployment on low-resource edge devices and in areas of little to no internet connectivity. We also present preliminary evaluations of utilizing the developed machine translation model to provide assistance to volunteers who are involved in collecting more data for the target language. Through these interventions, we not only created a refined and evaluated corpus of 26,240 Hindi-Gondi translations that was used for building the translation model but also engaged nearly 850 community members who can help take Gondi onto the internet.
A Discussion on Building Practical NLP Leaderboards: The Case of Machine Translation
Jun 11, 2021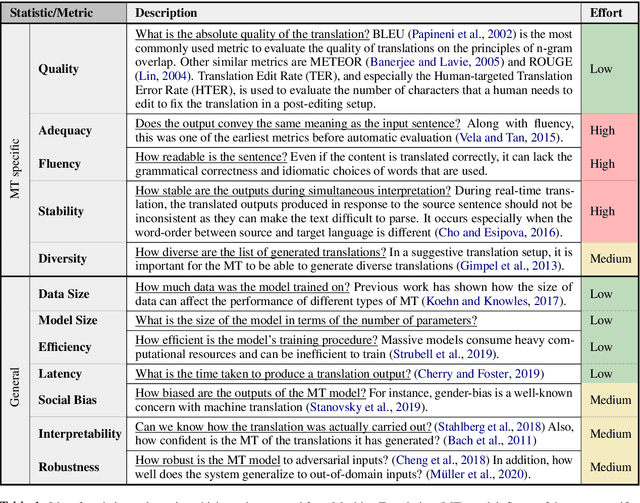
Recent advances in AI and ML applications have benefited from rapid progress in NLP research. Leaderboards have emerged as a popular mechanism to track and accelerate progress in NLP through competitive model development. While this has increased interest and participation, the over-reliance on single, and accuracy-based metrics have shifted focus from other important metrics that might be equally pertinent to consider in real-world contexts. In this paper, we offer a preliminary discussion of the risks associated with focusing exclusively on accuracy metrics and draw on recent discussions to highlight prescriptive suggestions on how to develop more practical and effective leaderboards that can better reflect the real-world utility of models.
Use of Formal Ethical Reviews in NLP Literature: Historical Trends and Current Practices
Jun 02, 2021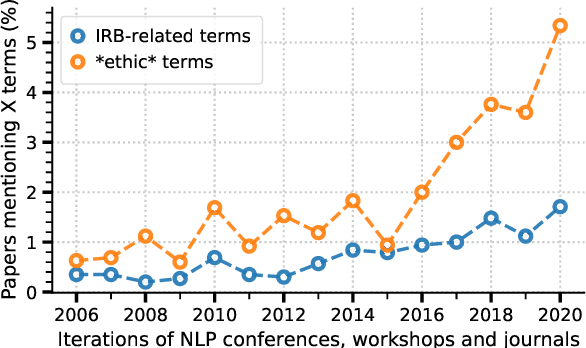
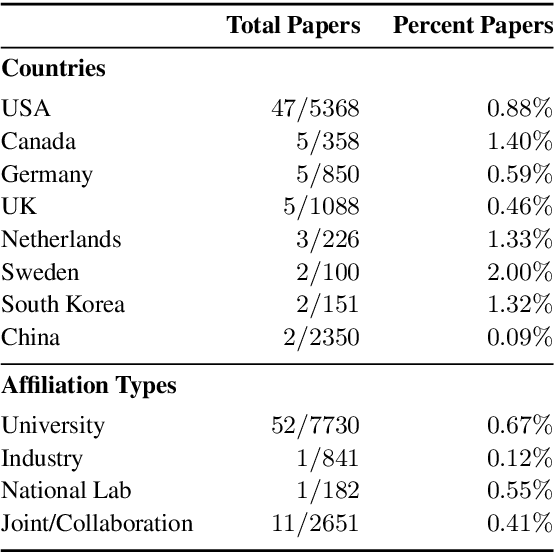
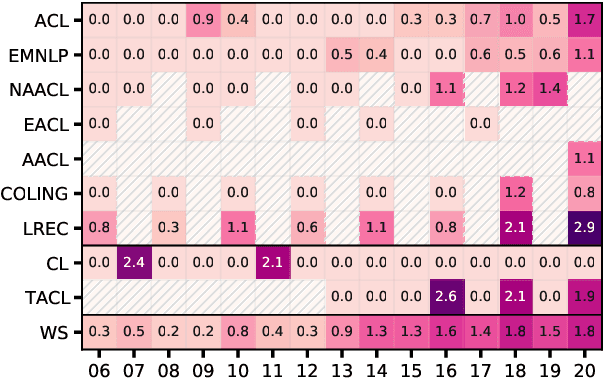
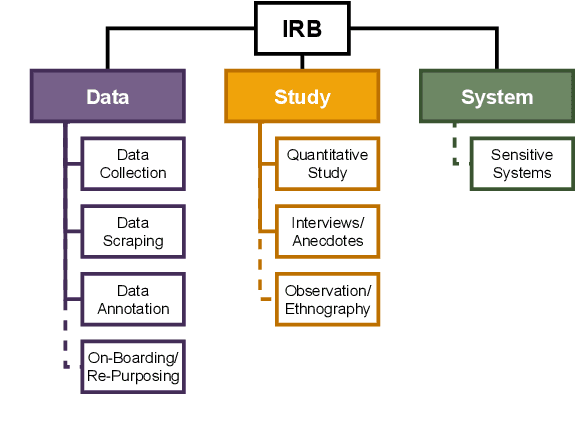
Ethical aspects of research in language technologies have received much attention recently. It is a standard practice to get a study involving human subjects reviewed and approved by a professional ethics committee/board of the institution. How commonly do we see mention of ethical approvals in NLP research? What types of research or aspects of studies are usually subject to such reviews? With the rising concerns and discourse around the ethics of NLP, do we also observe a rise in formal ethical reviews of NLP studies? And, if so, would this imply that there is a heightened awareness of ethical issues that was previously lacking? We aim to address these questions by conducting a detailed quantitative and qualitative analysis of the ACL Anthology, as well as comparing the trends in our field to those of other related disciplines, such as cognitive science, machine learning, data mining, and systems.
Learnings from Technological Interventions in a Low Resource Language: A Case-Study on Gondi
Apr 21, 2020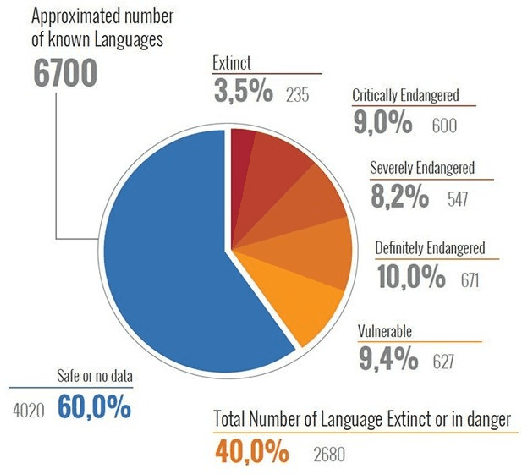
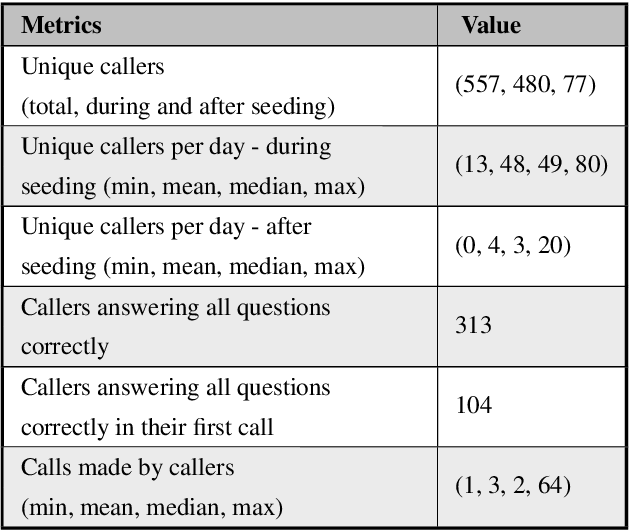
The primary obstacle to developing technologies for low-resource languages is the lack of usable data. In this paper, we report the adoption and deployment of 4 technology-driven methods of data collection for Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. In the process of data collection, we also help in its revival by expanding access to information in Gondi through the creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, an app with Gondi content from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform. At the end of these interventions, we collected a little less than 12,000 translated words and/or sentences and identified more than 650 community members whose help can be solicited for future translation efforts. The larger goal of the project is collecting enough data in Gondi to build and deploy viable language technologies like machine translation and speech to text systems that can help take the language onto the internet.