 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural and Linguistic Diversity Improves Visual Representations
Paper and Code
Oct 22, 2023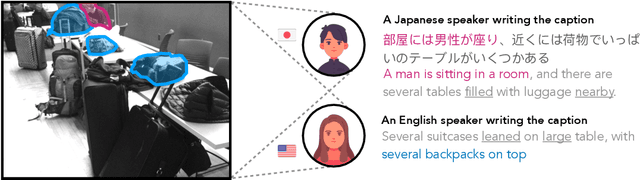
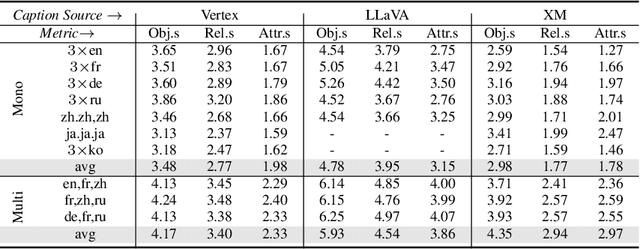
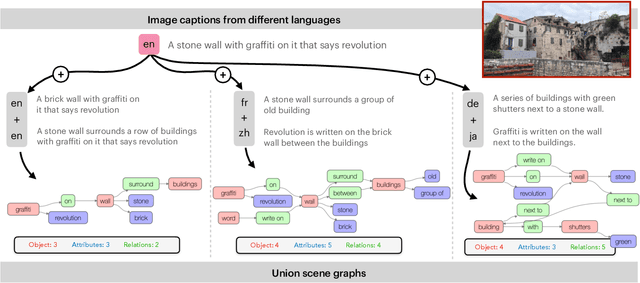
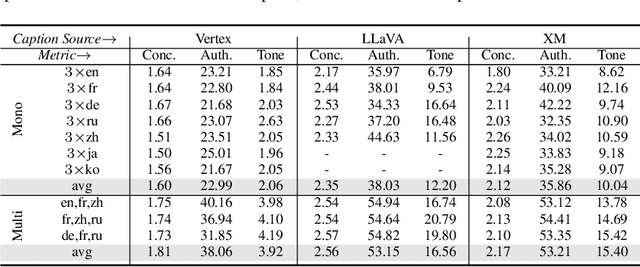
Computer vision often treats perception as objective, and this assumption gets reflected in the way that datasets are collected and models are trained. For instance, image descriptions in different languages are typically assumed to be translations of the same semantic content. However, work in cross-cultural psychology and linguistics has shown that individuals differ in their visual perception depending on their cultural background and the language they speak. In this paper, we demonstrate significant differences in semantic content across languages in both dataset and model-produced captions. When data is multilingual as opposed to monolingual, captions have higher semantic coverage on average, as measured by scene graph, embedding, and linguistic complexity. For example, multilingual captions have on average 21.8% more objects, 24.5% more relations, and 27.1% more attributes than a set of monolingual captions. Moreover, models trained on content from different languages perform best against test data from those languages, while those trained on multilingual content perform consistently well across all evaluation data compositions. Our research provides implications for how diverse modes of perception can improve image understanding.