 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Conceptual Multiverse
Apr 21, 2026When language models answer open-ended problems, they implicitly make hidden decisions that shape their outputs, leaving users with uncontextualized answers rather than a working map of the problem; drawing on multiverse analysis from statistics, we build and evaluate the conceptual multiverse, an interactive system that represents conceptual decisions such as how to frame a question or what to value as a space users can transparently inspect, intervenably change, and check against principled domain reasoning; for this structure to be worth navigating rather than misleading, it must be rigorous and checkable against domain reasoning norms, so we develop a general verification framework that enforces properties of good decision structures like unambiguity and completeness calibrated by expert-level reasoning; across three domains, the conceptual multiverse helped participants develop a working map of the problem, with philosophy students rewriting essays with sharper framings and reversed theses, alignment annotators moving from surface preferences to reasoning about user intent and harm, and poets identifying compositional patterns that clarified their taste.
Language Models as Critical Thinking Tools: A Case Study of Philosophers
Apr 06, 2024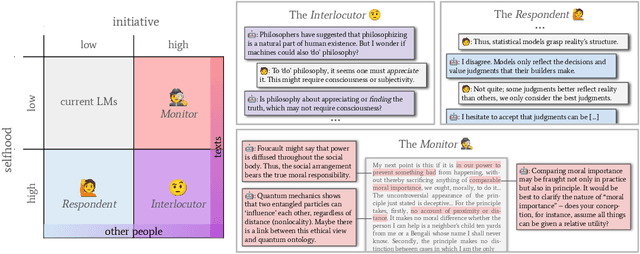
Current work in language models (LMs) helps us speed up or even skip thinking by accelerating and automating cognitive work. But can LMs help us with critical thinking -- thinking in deeper, more reflective ways which challenge assumptions, clarify ideas, and engineer new concepts? We treat philosophy as a case study in critical thinking, and interview 21 professional philosophers about how they engage in critical thinking and on their experiences with LMs. We find that philosophers do not find LMs to be useful because they lack a sense of selfhood (memory, beliefs, consistency) and initiative (curiosity, proactivity). We propose the selfhood-initiative model for critical thinking tools to characterize this gap. Using the model, we formulate three roles LMs could play as critical thinking tools: the Interlocutor, the Monitor, and the Respondent. We hope that our work inspires LM researchers to further develop LMs as critical thinking tools and philosophers and other 'critical thinkers' to imagine intellectually substantive uses of LMs.
And Then the Hammer Broke: Reflections on Machine Ethics from Feminist Philosophy of Science
Mar 09, 2024
Vision is an important metaphor in ethical and political questions of knowledge. The feminist philosopher Donna Haraway points out the ``perverse'' nature of an intrusive, alienating, all-seeing vision (to which we might cry out ``stop looking at me!''), but also encourages us to embrace the embodied nature of sight and its promises for genuinely situated knowledge. Current technologies of machine vision -- surveillance cameras, drones (for war or recreation), iPhone cameras -- are usually construed as instances of the former rather than the latter, and for good reasons. However, although in no way attempting to diminish the real suffering these technologies have brought about in the world, I make the case for understanding technologies of computer vision as material instances of embodied seeing and situated knowing. Furthermore, borrowing from Iris Murdoch's concept of moral vision, I suggest that these technologies direct our labor towards self-reflection in ethically significant ways. My approach draws upon paradigms in computer vision research, phenomenology, and feminist epistemology. Ultimately, this essay is an argument for directing more philosophical attention from merely criticizing technologies of vision as ethically deficient towards embracing them as complex, methodologically and epistemologically important objects.
A Roadmap to Pluralistic Alignment
Feb 07, 2024With increased power and prevalence of AI systems, it is ever more critical that AI systems are designed to serve all, i.e., people with diverse values and perspectives. However, aligning models to serve pluralistic human values remains an open research question. In this piece, we propose a roadmap to pluralistic alignment, specifically using language models as a test bed. We identify and formalize three possible ways to define and operationalize pluralism in AI systems: 1) Overton pluralistic models that present a spectrum of reasonable responses; 2) Steerably pluralistic models that can steer to reflect certain perspectives; and 3) Distributionally pluralistic models that are well-calibrated to a given population in distribution. We also propose and formalize three possible classes of pluralistic benchmarks: 1) Multi-objective benchmarks, 2) Trade-off steerable benchmarks, which incentivize models to steer to arbitrary trade-offs, and 3) Jury-pluralistic benchmarks which explicitly model diverse human ratings. We use this framework to argue that current alignment techniques may be fundamentally limited for pluralistic AI; indeed, we highlight empirical evidence, both from our own experiments and from other work, that standard alignment procedures might reduce distributional pluralism in models, motivating the need for further research on pluralistic alignment.
LLMs grasp morality in concept
Nov 04, 2023

Work in AI ethics and fairness has made much progress in regulating LLMs to reflect certain values, such as fairness, truth, and diversity. However, it has taken the problem of how LLMs might 'mean' anything at all for granted. Without addressing this, it is not clear what imbuing LLMs with such values even means. In response, we provide a general theory of meaning that extends beyond humans. We use this theory to explicate the precise nature of LLMs as meaning-agents. We suggest that the LLM, by virtue of its position as a meaning-agent, already grasps the constructions of human society (e.g. morality, gender, and race) in concept. Consequently, under certain ethical frameworks, currently popular methods for model alignment are limited at best and counterproductive at worst. Moreover, unaligned models may help us better develop our moral and social philosophy.
Cultural and Linguistic Diversity Improves Visual Representations
Oct 22, 2023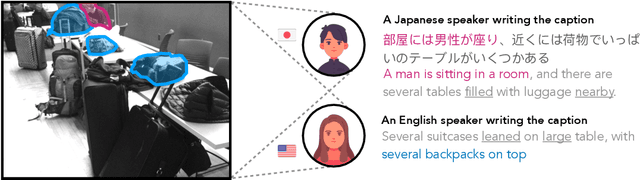
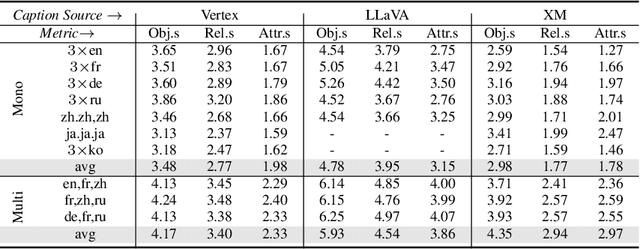
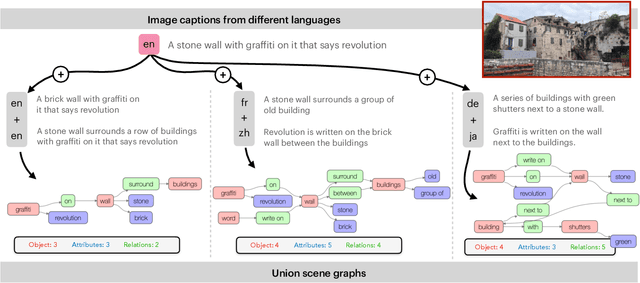
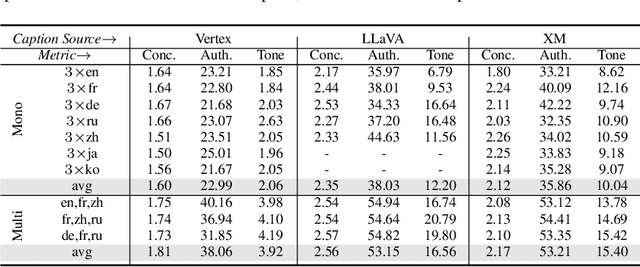
Computer vision often treats perception as objective, and this assumption gets reflected in the way that datasets are collected and models are trained. For instance, image descriptions in different languages are typically assumed to be translations of the same semantic content. However, work in cross-cultural psychology and linguistics has shown that individuals differ in their visual perception depending on their cultural background and the language they speak. In this paper, we demonstrate significant differences in semantic content across languages in both dataset and model-produced captions. When data is multilingual as opposed to monolingual, captions have higher semantic coverage on average, as measured by scene graph, embedding, and linguistic complexity. For example, multilingual captions have on average 21.8% more objects, 24.5% more relations, and 27.1% more attributes than a set of monolingual captions. Moreover, models trained on content from different languages perform best against test data from those languages, while those trained on multilingual content perform consistently well across all evaluation data compositions. Our research provides implications for how diverse modes of perception can improve image understanding.
Confidence Contours: Uncertainty-Aware Annotation for Medical Semantic Segmentation
Aug 15, 2023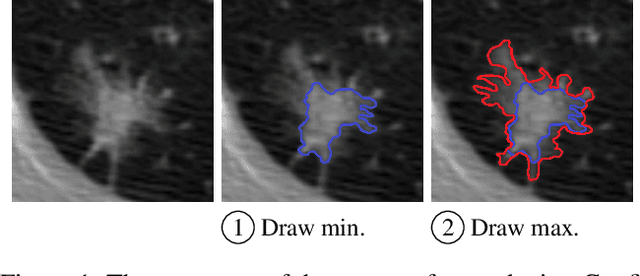
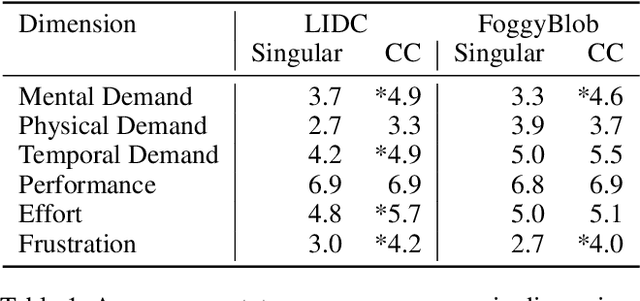
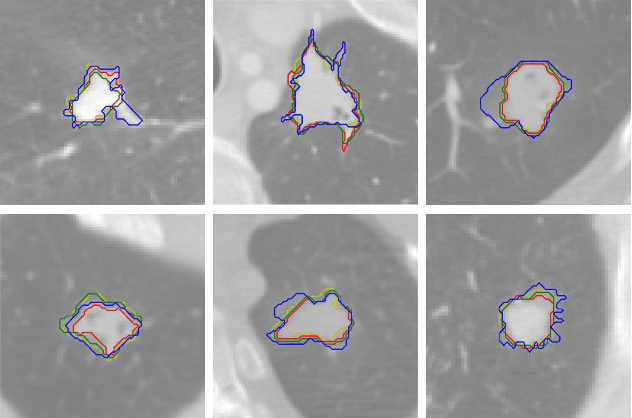
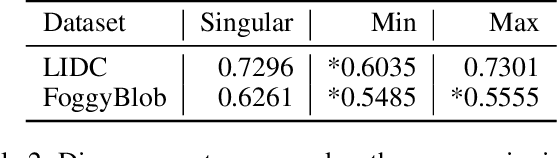
Medical image segmentation modeling is a high-stakes task where understanding of uncertainty is crucial for addressing visual ambiguity. Prior work has developed segmentation models utilizing probabilistic or generative mechanisms to infer uncertainty from labels where annotators draw a singular boundary. However, as these annotations cannot represent an individual annotator's uncertainty, models trained on them produce uncertainty maps that are difficult to interpret. We propose a novel segmentation representation, Confidence Contours, which uses high- and low-confidence ``contours'' to capture uncertainty directly, and develop a novel annotation system for collecting contours. We conduct an evaluation on the Lung Image Dataset Consortium (LIDC) and a synthetic dataset. From an annotation study with 30 participants, results show that Confidence Contours provide high representative capacity without considerably higher annotator effort. We also find that general-purpose segmentation models can learn Confidence Contours at the same performance level as standard singular annotations. Finally, from interviews with 5 medical experts, we find that Confidence Contour maps are more interpretable than Bayesian maps due to representation of structural uncertainty.