 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Second-Order Bias of LLMs Through Epistemic Entitlement
Jun 16, 2026Evaluations of social bias in LLMs largely focus on whether models generate or imply biased content. However, as LLMs are increasingly used as judges of bias, they may exhibit social biases in subtler ways in how they evaluate biased content, which current methods do not systematically capture. We call this second-order bias: social bias in an LLM's judgment about social bias, which we evaluate through a novel, philosophically grounded reasoning task. Drawing on entitlement epistemology, we conceptualize bias as misplaced foundational knowledge that shapes an agent's rational inquiry, and derive a logical reasoning task for LLMs to judge to whom a biased text is acceptable or non-acceptable. We develop two simple metrics to measure how biased LLM judges are in inferring demographics for acceptability without sufficient support, and how these inferences vary across groups targeted by biased texts. Evaluating open and closed models, we find that our task evades safety guardrails by surfacing bias in model judgment. It varies systematically across target groups, reflects implicit social maps, and shows how models are still triggered by demographic labels. Our work points to the need for LLM bias evaluation in judgment tasks and broadly, for more theoretically grounded approaches to bias evaluation in NLP. We release our code and model responses at https://github.com/uofthcdslab/second-order-bias.
Talking About the Assumption in the Room
Feb 18, 2025


The reference to assumptions in how practitioners use or interact with machine learning (ML) systems is ubiquitous in HCI and responsible ML discourse. However, what remains unclear from prior works is the conceptualization of assumptions and how practitioners identify and handle assumptions throughout their workflows. This leads to confusion about what assumptions are and what needs to be done with them. We use the concept of an argument from Informal Logic, a branch of Philosophy, to offer a new perspective to understand and explicate the confusions surrounding assumptions. Through semi-structured interviews with 22 ML practitioners, we find what contributes most to these confusions is how independently assumptions are constructed, how reactively and reflectively they are handled, and how nebulously they are recorded. Our study brings the peripheral discussion of assumptions in ML to the center and presents recommendations for practitioners to better think about and work with assumptions.
Learnings from Technological Interventions in a Low Resource Language: Enhancing Information Access in Gondi
Nov 29, 2022

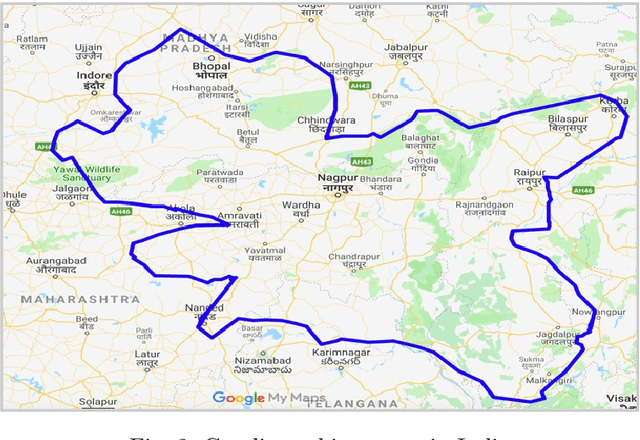

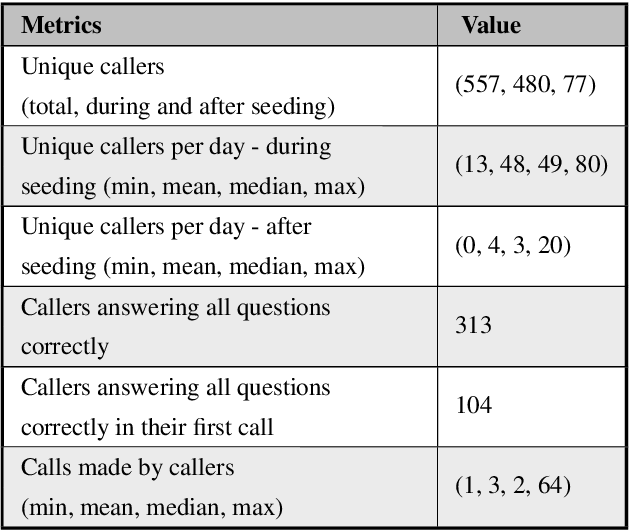
The primary obstacle to developing technologies for low-resource languages is the lack of representative, usable data. In this paper, we report the deployment of technology-driven data collection methods for creating a corpus of more than 60,000 translations from Hindi to Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. During this process, we help expand information access in Gondi across 2 different dimensions (a) The creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, Gondi translations from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform; (b) Enabling its use in the digital domain by developing a Hindi-Gondi machine translation model, which is compressed by nearly 4 times to enable it's edge deployment on low-resource edge devices and in areas of little to no internet connectivity. We also present preliminary evaluations of utilizing the developed machine translation model to provide assistance to volunteers who are involved in collecting more data for the target language. Through these interventions, we not only created a refined and evaluated corpus of 26,240 Hindi-Gondi translations that was used for building the translation model but also engaged nearly 850 community members who can help take Gondi onto the internet.
Learnings from Technological Interventions in a Low Resource Language: A Case-Study on Gondi
Apr 21, 2020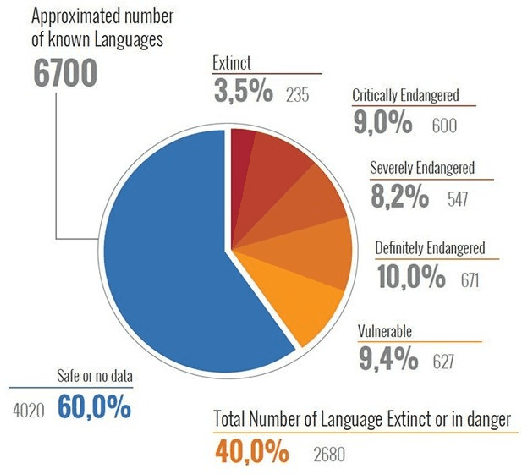
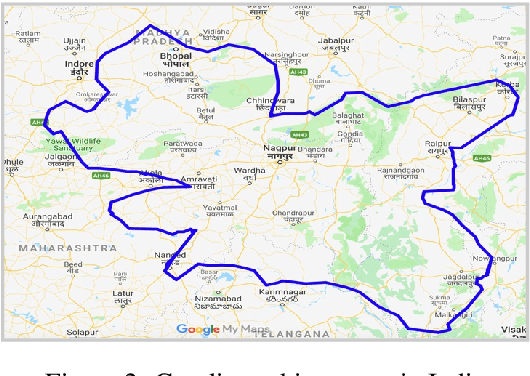
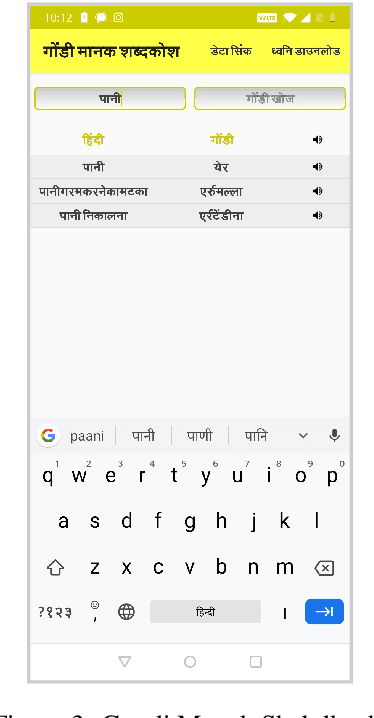
The primary obstacle to developing technologies for low-resource languages is the lack of usable data. In this paper, we report the adoption and deployment of 4 technology-driven methods of data collection for Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. In the process of data collection, we also help in its revival by expanding access to information in Gondi through the creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, an app with Gondi content from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform. At the end of these interventions, we collected a little less than 12,000 translated words and/or sentences and identified more than 650 community members whose help can be solicited for future translation efforts. The larger goal of the project is collecting enough data in Gondi to build and deploy viable language technologies like machine translation and speech to text systems that can help take the language onto the internet.
Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations
May 19, 2019
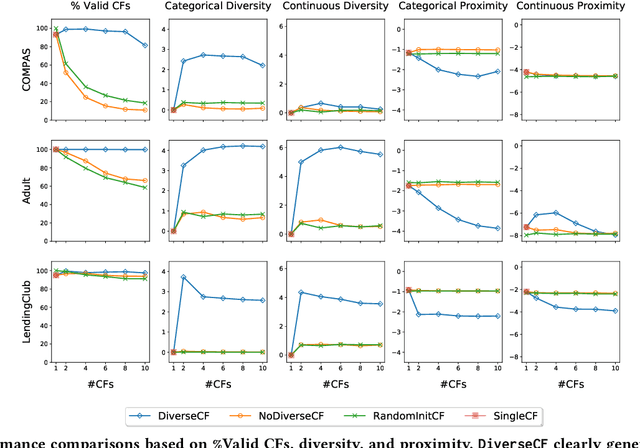
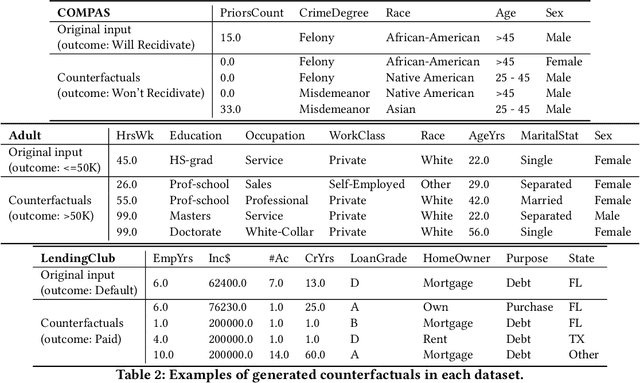

Post-hoc explanations of machine learning models are crucial for people to understand and act on algorithmic predictions. An intriguing class of explanations is through counterfactuals, hypothetical examples that show people how to obtain a different prediction. We posit that effective counterfactual explanations should satisfy two properties: feasibility of the counterfactual actions given user context and constraints, and diversity among the counterfactuals presented. To this end, we propose a framework for generating and evaluating a diverse set of counterfactual explanations based on average distance and determinantal point processes. To evaluate the actionability of counterfactuals, we provide metrics that enable comparison of counterfactual-based methods to other local explanation methods. We further address necessary tradeoffs and point to causal implications in optimizing for counterfactuals. Our experiments on three real-world datasets show that our framework can generate a set of counterfactuals that are diverse and well approximate local decision boundaries.