 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnings from Technological Interventions in a Low Resource Language: Enhancing Information Access in Gondi
Nov 29, 2022The primary obstacle to developing technologies for low-resource languages is the lack of representative, usable data. In this paper, we report the deployment of technology-driven data collection methods for creating a corpus of more than 60,000 translations from Hindi to Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. During this process, we help expand information access in Gondi across 2 different dimensions (a) The creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, Gondi translations from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform; (b) Enabling its use in the digital domain by developing a Hindi-Gondi machine translation model, which is compressed by nearly 4 times to enable it's edge deployment on low-resource edge devices and in areas of little to no internet connectivity. We also present preliminary evaluations of utilizing the developed machine translation model to provide assistance to volunteers who are involved in collecting more data for the target language. Through these interventions, we not only created a refined and evaluated corpus of 26,240 Hindi-Gondi translations that was used for building the translation model but also engaged nearly 850 community members who can help take Gondi onto the internet.
Memory Capacity of Neural Turing Machines with Matrix Representation
Apr 11, 2021



It is well known that recurrent neural networks (RNNs) faced limitations in learning long-term dependencies that have been addressed by memory structures in long short-term memory (LSTM) networks. Matrix neural networks feature matrix representation which inherently preserves the spatial structure of data and has the potential to provide better memory structures when compared to canonical neural networks that use vector representation. Neural Turing machines (NTMs) are novel RNNs that implement notion of programmable computers with neural network controllers to feature algorithms that have copying, sorting, and associative recall tasks. In this paper, we study the augmentation of memory capacity with a matrix representation of RNNs and NTMs (MatNTMs). We investigate if matrix representation has a better memory capacity than the vector representations in conventional neural networks. We use a probabilistic model of the memory capacity using Fisher information and investigate how the memory capacity for matrix representation networks are limited under various constraints, and in general, without any constraints. In the case of memory capacity without any constraints, we found that the upper bound on memory capacity to be $N^2$ for an $N\times N$ state matrix. The results from our experiments using synthetic algorithmic tasks show that MatNTMs have a better learning capacity when compared to its counterparts.
Learnings from Technological Interventions in a Low Resource Language: A Case-Study on Gondi
Apr 21, 2020
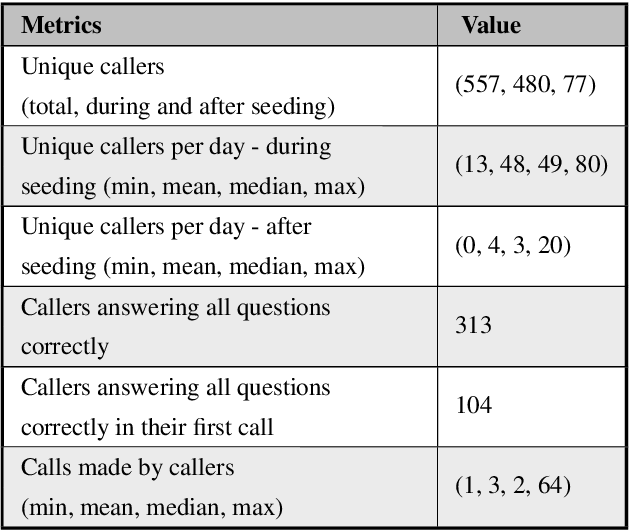
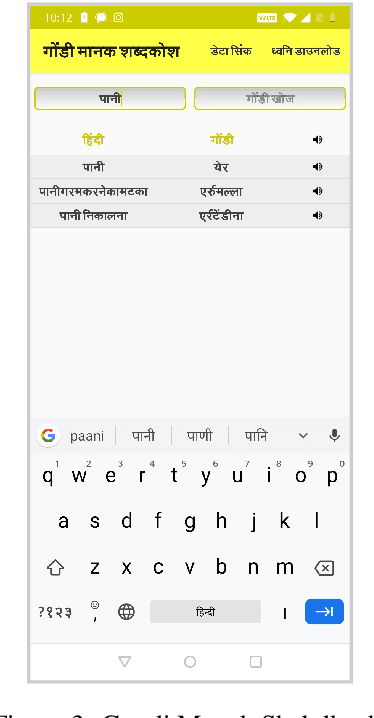
The primary obstacle to developing technologies for low-resource languages is the lack of usable data. In this paper, we report the adoption and deployment of 4 technology-driven methods of data collection for Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. In the process of data collection, we also help in its revival by expanding access to information in Gondi through the creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, an app with Gondi content from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform. At the end of these interventions, we collected a little less than 12,000 translated words and/or sentences and identified more than 650 community members whose help can be solicited for future translation efforts. The larger goal of the project is collecting enough data in Gondi to build and deploy viable language technologies like machine translation and speech to text systems that can help take the language onto the internet.