 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Is This Not Enough?": Asymmetries in Institutional Accountability and Collective Sensemaking in the Case of Canada's Algorithmic Visa Triage System
Jun 11, 2026This paper examines how algorithmic accountability in Canada's visa system is articulated institutionally and experienced by applicants across borders. We analyzed Immigration, Refugees and Citizenship Canada (IRCC)'s Algorithmic Impact Assessment (AIA) for the temporary resident visa (TRV) triage system using the algorithmic decision-making adapted for the public sector (ADMAPS) framework and analyzed Reddit discussions among applicants using a mixed-methods approach. We show that while institutional artifacts emphasize transparency, procedural safeguards, and bounded impacts, applicants engage in collective sensemaking to interpret opaque decisions, often relying on peer knowledge amid uncertainty. We identify three asymmetries between how institutional accountability is structured and how people perceive the process: epistemic asymmetry in access to decision logic, jurisdictional asymmetry in exposure shaped by geopolitical positioning, and temporal--relational asymmetry in how waiting and uncertainty are experienced. We emphasize why it is important to shift attention from institutional design to the uneven distribution of experiences with public-sector algorithmic governance. Together, these contributions demonstrate how algorithmic governance systems in the context of transnational migration produce structured asymmetries not captured by institutional disclosure frameworks, and how extending ADMAPS can account for those uneven translations of accountability.
Mod-Guide: An LLM-based Content Moderation Feedback System to Address Insensitive Speech toward Indigenous Ethnic and Religious Minority Communities
Jun 11, 2026Language operates as a mechanism of both marginalization and resistance, especially for minority communities navigating insensitive and harmful speech online. As content moderation increasingly depends on large language models (LLMs), concerns arise about whether these systems can recognize culturally insensitive speech-language that disregards or marginalizes the cultural and religious perspectives of historically underrepresented communities, often through implicit erasure, misrepresentation, or normative framing, rather than overt hostility. Focusing on Bangladesh's Hindu and Chakma communities -- the country's largest religious and Indigenous ethnic minorities, respectively -- this paper investigates the epistemic limits of LLM-based moderation systems and explores methods for incorporating minority perspectives. We co-created a culturally grounded corpus of insensitive speech with community members and integrated their narratives into moderation pipelines using retrieval augmented generation (RAG). Our tool, Mod-Guide, improves LLM sensitivity to minority viewpoints by leveraging contextual cues derived from lived experience. Through mixed-method evaluations involving both minority and majority participants, we demonstrate that RAG-enhanced moderation responses are more contextually accurate and perceived differently across ethnic lines. This work advances research in human-computer interaction, AI ethics, and social computing by foregrounding restorative justice and hermeneutical inclusion in the design of content moderation systems.
Fairness Audits of Institutional Risk Models in Deployed ML Pipelines
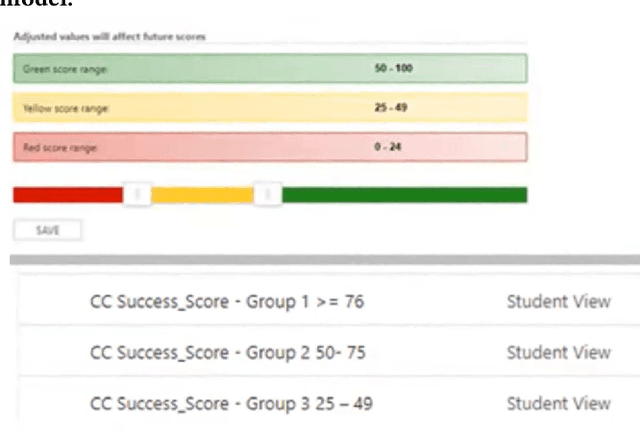
Apr 21, 2026Fairness audits of institutional risk models are critical for understanding how deployed machine learning pipelines allocate resources. Drawing on multi-year collaboration with Centennial College, where our prior ethnographic work introduced the ASP-HEI Cycle, we present a replica-based audit of a deployed Early Warning System (EWS), replicating its model using institutional training data and design specifications. We evaluate disparities by gender, age, and residency status across the full pipeline (training data, model predictions, and post-processing) using standard fairness metrics. Our audit reveals systematic misallocation: younger, male, and international students are disproportionately flagged for support, even when many ultimately succeed, while older and female students with comparable dropout risk are under-identified. Post-processing amplifies these disparities by collapsing heterogeneous probabilities into percentile-based risk tiers. This work provides a replicable methodology for auditing institutional ML systems and shows how disparities emerge and compound across stages, highlighting the importance of evaluating construct validity alongside statistical fairness. It contributes one empirical thread to a broader program investigating algorithms, student data, and power in higher education.
Human-Aligned Faithfulness in Toxicity Explanations of LLMs
Jun 23, 2025The discourse around toxicity and LLMs in NLP largely revolves around detection tasks. This work shifts the focus to evaluating LLMs' reasoning about toxicity -- from their explanations that justify a stance -- to enhance their trustworthiness in downstream tasks. Despite extensive research on explainability, it is not straightforward to adopt existing methods to evaluate free-form toxicity explanation due to their over-reliance on input text perturbations, among other challenges. To account for these, we propose a novel, theoretically-grounded multi-dimensional criterion, Human-Aligned Faithfulness (HAF), that measures the extent to which LLMs' free-form toxicity explanations align with those of a rational human under ideal conditions. We develop six metrics, based on uncertainty quantification, to comprehensively evaluate \haf of LLMs' toxicity explanations with no human involvement, and highlight how "non-ideal" the explanations are. We conduct several experiments on three Llama models (of size up to 70B) and an 8B Ministral model on five diverse toxicity datasets. Our results show that while LLMs generate plausible explanations to simple prompts, their reasoning about toxicity breaks down when prompted about the nuanced relations between the complete set of reasons, the individual reasons, and their toxicity stances, resulting in inconsistent and nonsensical responses. We open-source our code and LLM-generated explanations at https://github.com/uofthcdslab/HAF.
BTPD: A Multilingual Hand-curated Dataset of Bengali Transnational Political Discourse Across Online Communities
Jun 07, 2025Understanding political discourse in online spaces is crucial for analyzing public opinion and ideological polarization. While social computing and computational linguistics have explored such discussions in English, such research efforts are significantly limited in major yet under-resourced languages like Bengali due to the unavailability of datasets. In this paper, we present a multilingual dataset of Bengali transnational political discourse (BTPD) collected from three online platforms, each representing distinct community structures and interaction dynamics. Besides describing how we hand-curated the dataset through community-informed keyword-based retrieval, this paper also provides a general overview of its topics and multilingual content.
How do datasets, developers, and models affect biases in a low-resourced language?
Jun 07, 2025Sociotechnical systems, such as language technologies, frequently exhibit identity-based biases. These biases exacerbate the experiences of historically marginalized communities and remain understudied in low-resource contexts. While models and datasets specific to a language or with multilingual support are commonly recommended to address these biases, this paper empirically tests the effectiveness of such approaches in the context of gender, religion, and nationality-based identities in Bengali, a widely spoken but low-resourced language. We conducted an algorithmic audit of sentiment analysis models built on mBERT and BanglaBERT, which were fine-tuned using all Bengali sentiment analysis (BSA) datasets from Google Dataset Search. Our analyses showed that BSA models exhibit biases across different identity categories despite having similar semantic content and structure. We also examined the inconsistencies and uncertainties arising from combining pre-trained models and datasets created by individuals from diverse demographic backgrounds. We connected these findings to the broader discussions on epistemic injustice, AI alignment, and methodological decisions in algorithmic audits.
Talking About the Assumption in the Room
Feb 18, 2025


The reference to assumptions in how practitioners use or interact with machine learning (ML) systems is ubiquitous in HCI and responsible ML discourse. However, what remains unclear from prior works is the conceptualization of assumptions and how practitioners identify and handle assumptions throughout their workflows. This leads to confusion about what assumptions are and what needs to be done with them. We use the concept of an argument from Informal Logic, a branch of Philosophy, to offer a new perspective to understand and explicate the confusions surrounding assumptions. Through semi-structured interviews with 22 ML practitioners, we find what contributes most to these confusions is how independently assumptions are constructed, how reactively and reflectively they are handled, and how nebulously they are recorded. Our study brings the peripheral discussion of assumptions in ML to the center and presents recommendations for practitioners to better think about and work with assumptions.
"This is not a data problem": Algorithms and Power in Public Higher Education in Canada
Mar 22, 2024
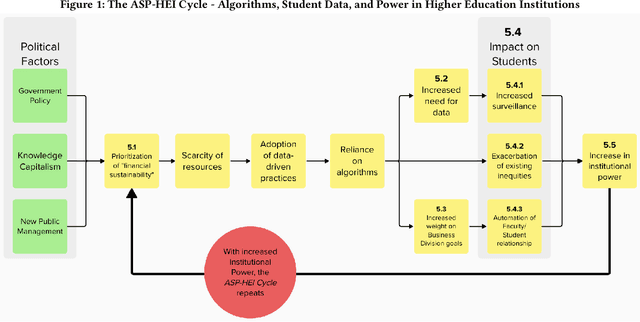
Algorithmic decision-making is increasingly being adopted across public higher education. The expansion of data-driven practices by post-secondary institutions has occurred in parallel with the adoption of New Public Management approaches by neoliberal administrations. In this study, we conduct a qualitative analysis of an in-depth ethnographic case study of data and algorithms in use at a public college in Ontario, Canada. We identify the data, algorithms, and outcomes in use at the college. We assess how the college's processes and relationships support those outcomes and the different stakeholders' perceptions of the college's data-driven systems. In addition, we find that the growing reliance on algorithmic decisions leads to increased student surveillance, exacerbation of existing inequities, and the automation of the faculty-student relationship. Finally, we identify a cycle of increased institutional power perpetuated by algorithmic decision-making, and driven by a push towards financial sustainability.
Beyond Predictive Algorithms in Child Welfare
Feb 26, 2024


Caseworkers in the child welfare (CW) sector use predictive decision-making algorithms built on risk assessment (RA) data to guide and support CW decisions. Researchers have highlighted that RAs can contain biased signals which flatten CW case complexities and that the algorithms may benefit from incorporating contextually rich case narratives, i.e. - casenotes written by caseworkers. To investigate this hypothesized improvement, we quantitatively deconstructed two commonly used RAs from a United States CW agency. We trained classifier models to compare the predictive validity of RAs with and without casenote narratives and applied computational text analysis on casenotes to highlight topics uncovered in the casenotes. Our study finds that common risk metrics used to assess families and build CWS predictive risk models (PRMs) are unable to predict discharge outcomes for children who are not reunified with their birth parent(s). We also find that although casenotes cannot predict discharge outcomes, they contain contextual case signals. Given the lack of predictive validity of RA scores and casenotes, we propose moving beyond quantitative risk assessments for public sector algorithms and towards using contextual sources of information such as narratives to study public sociotechnical systems.
The "Colonial Impulse" of Natural Language Processing: An Audit of Bengali Sentiment Analysis Tools and Their Identity-based Biases
Jan 19, 2024



While colonization has sociohistorically impacted people's identities across various dimensions, those colonial values and biases continue to be perpetuated by sociotechnical systems. One category of sociotechnical systems--sentiment analysis tools--can also perpetuate colonial values and bias, yet less attention has been paid to how such tools may be complicit in perpetuating coloniality, although they are often used to guide various practices (e.g., content moderation). In this paper, we explore potential bias in sentiment analysis tools in the context of Bengali communities that have experienced and continue to experience the impacts of colonialism. Drawing on identity categories most impacted by colonialism amongst local Bengali communities, we focused our analytic attention on gender, religion, and nationality. We conducted an algorithmic audit of all sentiment analysis tools for Bengali, available on the Python package index (PyPI) and GitHub. Despite similar semantic content and structure, our analyses showed that in addition to inconsistencies in output from different tools, Bengali sentiment analysis tools exhibit bias between different identity categories and respond differently to different ways of identity expression. Connecting our findings with colonially shaped sociocultural structures of Bengali communities, we discuss the implications of downstream bias of sentiment analysis tools.