 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CIFAR Synthetic Evidence Corpus for Detecting AI-Generated Evidence
Jun 06, 2026The growing ability of generative models to produce realistic documents poses a direct challenge to evidentiary workflows in the justice system and the courts, where decisions increasingly depend on the authenticity of evidence such as receipts, communications, and administrative records. Unlike social media or academic settings, evidentiary documents are often only subtly altered, with small, localized edits that preserve overall plausibility while changing legal meaning. Yet progress on automated detection remains limited, largely due to the absence of suitable training and evaluation data especially suited for the justice system requirements. Existing resources are either focused on photos of human faces or natural scenery or on narrowly scoped academic or social media document types, and do not capture the structure, diversity, or manipulation patterns characteristic of real-world evidentiary data. As a result, current detection systems do not necessarily learn meaningful signals appropriate for the justice system. We introduce the CIFAR Synthetic Evidence Corpus, a dataset designed to enable rigorous evaluation of evidence verification under realistic and controlled conditions. The corpus spans multiple document families and a spectrum of manipulation strategies, from small field-level edits to complete document fabrication, and is constructed using a diverse set of state-of-the-art generative tools. It is organized to systematically vary both manipulation complexity and generation method, while enforcing source-level separation between training and test data to reflect real-world generalization challenges.
DetectZoo: A Unified Toolkit for AI-Generated Content Detection Across Text, Audio, and Image Modalities
Jun 02, 2026The growing popularity and capacity of generative models have eroded the distinction between human and machine-generated content, motivating a growing body of work on detection across text, images, and audio. Most available detectors are either commercial software or, if open-source, come with incompatible codebases with bespoke preprocessing, evaluation protocols, and evaluation metrics, which make their adoption, fair comparison, and reproduction quite difficult. To address this critical gap, we introduce DetectZoo, a first-of-its-kind, extensible toolkit designed to provide a unified interface for AI-generated content detection across text, audio, and image modalities. DetectZoo standardizes the complete empirical pipeline, from data ingestion and preprocessing to model assessment, offering researchers a cohesive framework to benchmark state-of-the-art detectors systematically. By integrating diverse public datasets and baseline detection algorithms under a single, unified API, our toolkit facilitates rigorous and reproducible evaluation. DetectZoo provides reference implementations of 61 detectors, native loaders for 22 benchmark datasets, and a standardized evaluation pipeline that reports multiple metrics through a common interface. Each detector is self-contained yet accessible through the same interface, automatically caches pretrained weights, and reproduces the original published results. DetectZoo lowers the barrier to entry for multi-modal AI forensics, enabling researchers to identify performance gaps across domains and accelerating the development of robust, generalizable detection techniques. The open-source repository and comprehensive documentation are publicly available at https://github.com/sadjadeb/DetectZoo, and the package can be installed via pip install detectzoo.
Fairness Audits of Institutional Risk Models in Deployed ML Pipelines
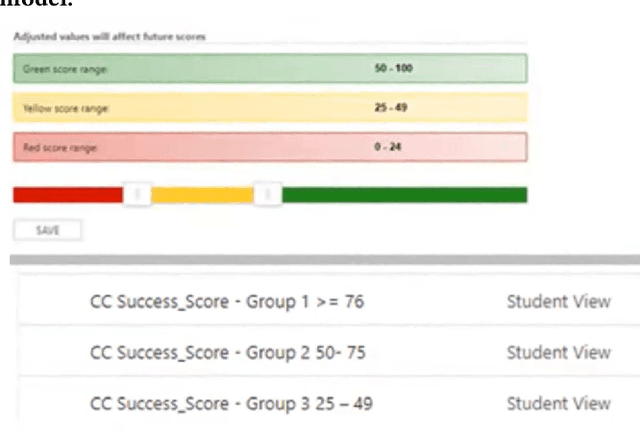
Apr 21, 2026Fairness audits of institutional risk models are critical for understanding how deployed machine learning pipelines allocate resources. Drawing on multi-year collaboration with Centennial College, where our prior ethnographic work introduced the ASP-HEI Cycle, we present a replica-based audit of a deployed Early Warning System (EWS), replicating its model using institutional training data and design specifications. We evaluate disparities by gender, age, and residency status across the full pipeline (training data, model predictions, and post-processing) using standard fairness metrics. Our audit reveals systematic misallocation: younger, male, and international students are disproportionately flagged for support, even when many ultimately succeed, while older and female students with comparable dropout risk are under-identified. Post-processing amplifies these disparities by collapsing heterogeneous probabilities into percentile-based risk tiers. This work provides a replicable methodology for auditing institutional ML systems and shows how disparities emerge and compound across stages, highlighting the importance of evaluating construct validity alongside statistical fairness. It contributes one empirical thread to a broader program investigating algorithms, student data, and power in higher education.
"This is not a data problem": Algorithms and Power in Public Higher Education in Canada
Mar 22, 2024
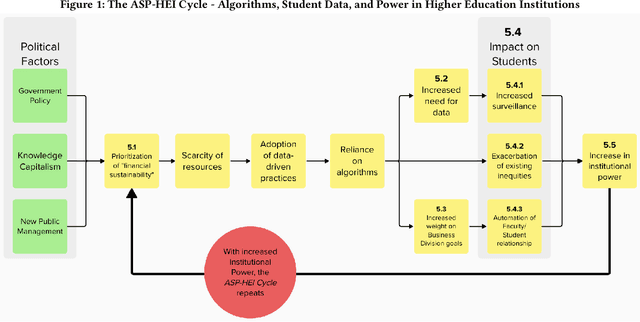
Algorithmic decision-making is increasingly being adopted across public higher education. The expansion of data-driven practices by post-secondary institutions has occurred in parallel with the adoption of New Public Management approaches by neoliberal administrations. In this study, we conduct a qualitative analysis of an in-depth ethnographic case study of data and algorithms in use at a public college in Ontario, Canada. We identify the data, algorithms, and outcomes in use at the college. We assess how the college's processes and relationships support those outcomes and the different stakeholders' perceptions of the college's data-driven systems. In addition, we find that the growing reliance on algorithmic decisions leads to increased student surveillance, exacerbation of existing inequities, and the automation of the faculty-student relationship. Finally, we identify a cycle of increased institutional power perpetuated by algorithmic decision-making, and driven by a push towards financial sustainability.
A Human-Centered Review of Algorithms in Decision-Making in Higher Education
Feb 12, 2023The use of algorithms for decision-making in higher education is steadily growing, promising cost-savings to institutions and personalized service for students but also raising ethical challenges around surveillance, fairness, and interpretation of data. To address the lack of systematic understanding of how these algorithms are currently designed, we reviewed an extensive corpus of papers proposing algorithms for decision-making in higher education. We categorized them based on input data, computational method, and target outcome, and then investigated the interrelations of these factors with the application of human-centered lenses: theoretical, participatory, or speculative design. We found that the models are trending towards deep learning, and increased use of student personal data and protected attributes, with the target scope expanding towards automated decisions. However, despite the associated decrease in interpretability and explainability, current development predominantly fails to incorporate human-centered lenses. We discuss the challenges with these trends and advocate for a human-centered approach.