 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Interaction Alignment: Designing, Evaluating, and Evolving Value-Centered AI For Reciprocal Human-AI Futures
Dec 25, 2025The rapid integration of generative AI into everyday life underscores the need to move beyond unidirectional alignment models that only adapt AI to human values. This workshop focuses on bidirectional human-AI alignment, a dynamic, reciprocal process where humans and AI co-adapt through interaction, evaluation, and value-centered design. Building on our past CHI 2025 BiAlign SIG and ICLR 2025 Workshop, this workshop will bring together interdisciplinary researchers from HCI, AI, social sciences and more domains to advance value-centered AI and reciprocal human-AI collaboration. We focus on embedding human and societal values into alignment research, emphasizing not only steering AI toward human values but also enabling humans to critically engage with and evolve alongside AI systems. Through talks, interdisciplinary discussions, and collaborative activities, participants will explore methods for interactive alignment, frameworks for societal impact evaluation, and strategies for alignment in dynamic contexts. This workshop aims to bridge the disciplines' gaps and establish a shared agenda for responsible, reciprocal human-AI futures.
Understanding Prompt Programming Tasks and Questions
Jul 23, 2025Prompting foundation models (FMs) like large language models (LLMs) have enabled new AI-powered software features (e.g., text summarization) that previously were only possible by fine-tuning FMs. Now, developers are embedding prompts in software, known as prompt programs. The process of prompt programming requires the developer to make many changes to their prompt. Yet, the questions developers ask to update their prompt is unknown, despite the answers to these questions affecting how developers plan their changes. With the growing number of research and commercial prompt programming tools, it is unclear whether prompt programmers' needs are being adequately addressed. We address these challenges by developing a taxonomy of 25 tasks prompt programmers do and 51 questions they ask, measuring the importance of each task and question. We interview 16 prompt programmers, observe 8 developers make prompt changes, and survey 50 developers. We then compare the taxonomy with 48 research and commercial tools. We find that prompt programming is not well-supported: all tasks are done manually, and 16 of the 51 questions -- including a majority of the most important ones -- remain unanswered. Based on this, we outline important opportunities for prompt programming tools.
Can GPT-4 Replicate Empirical Software Engineering Research?
Oct 03, 2023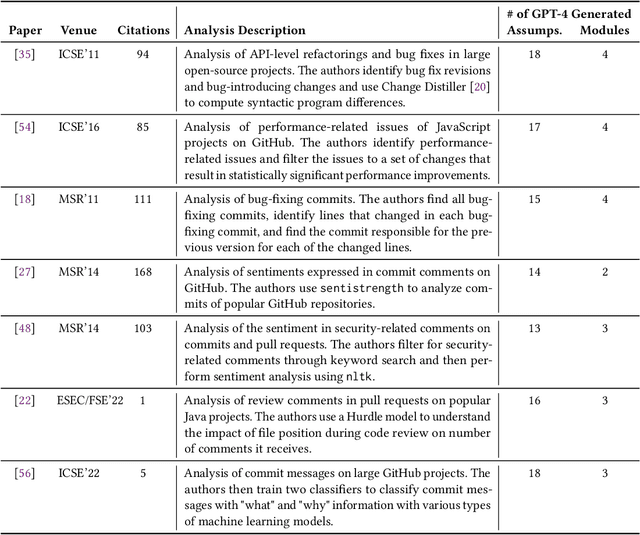
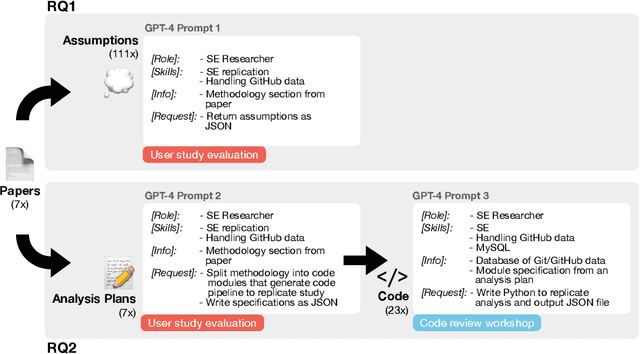

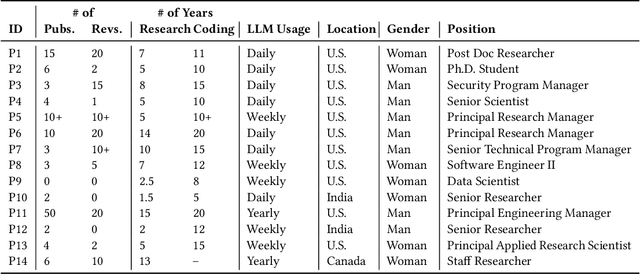
Empirical software engineering research on production systems has brought forth a better understanding of the software engineering process for practitioners and researchers alike. However, only a small subset of production systems is studied, limiting the impact of this research. While software engineering practitioners benefit from replicating research on their own data, this poses its own set of challenges, since performing replications requires a deep understanding of research methodologies and subtle nuances in software engineering data. Given that large language models (LLMs), such as GPT-4, show promise in tackling both software engineering- and science-related tasks, these models could help democratize empirical software engineering research. In this paper, we examine LLMs' abilities to perform replications of empirical software engineering research on new data. We specifically study their ability to surface assumptions made in empirical software engineering research methodologies, as well as their ability to plan and generate code for analysis pipelines on seven empirical software engineering papers. We perform a user study with 14 participants with software engineering research expertise, who evaluate GPT-4-generated assumptions and analysis plans (i.e., a list of module specifications) from the papers. We find that GPT-4 is able to surface correct assumptions, but struggle to generate ones that reflect common knowledge about software engineering data. In a manual analysis of the generated code, we find that the GPT-4-generated code contains the correct high-level logic, given a subset of the methodology. However, the code contains many small implementation-level errors, reflecting a lack of software engineering knowledge. Our findings have implications for leveraging LLMs for software engineering research as well as practitioner data scientists in software teams.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023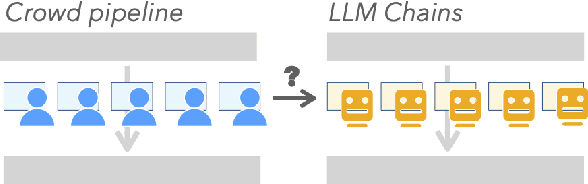

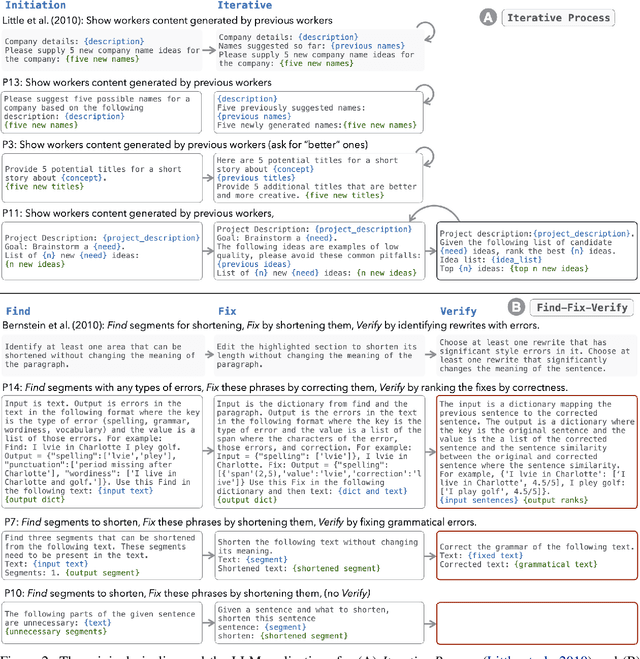
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.
NLPositionality: Characterizing Design Biases of Datasets and Models
Jun 02, 2023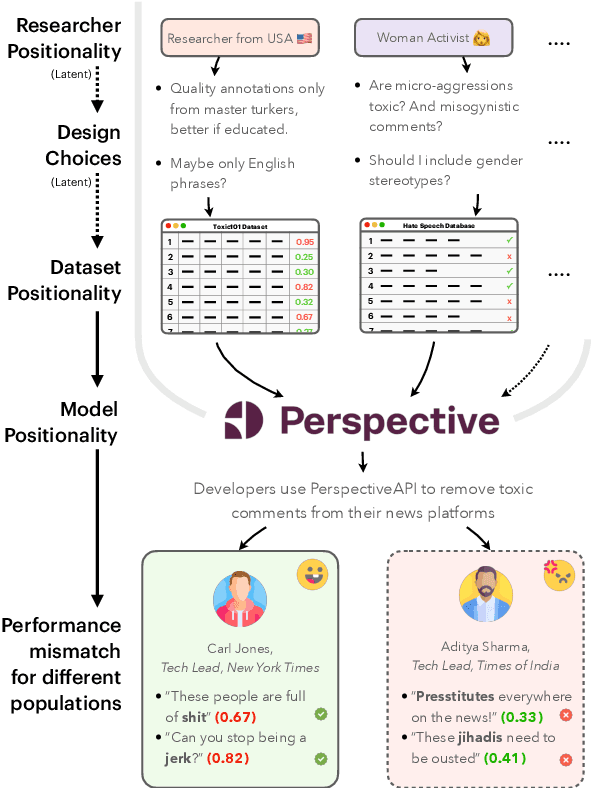
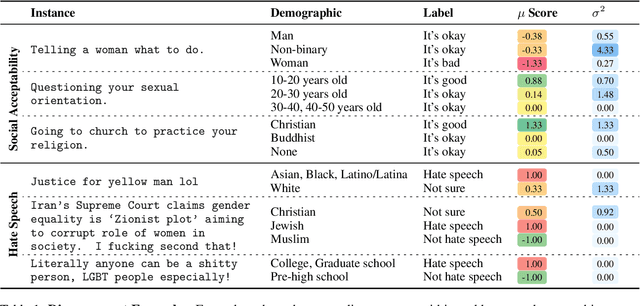
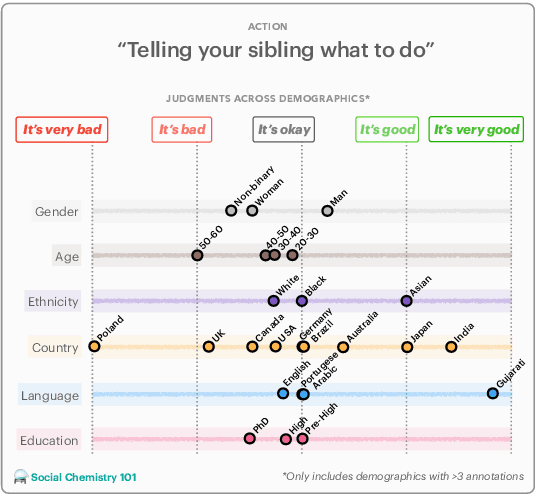
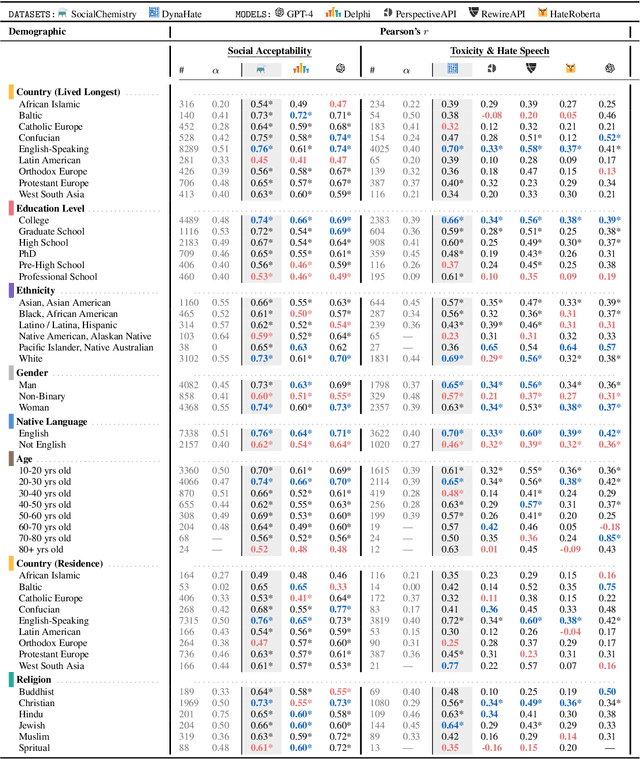
Design biases in NLP systems, such as performance differences for different populations, often stem from their creator's positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality is often unobserved. We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and models. Our framework continuously collects annotations from a diverse pool of volunteer participants on LabintheWild, and statistically quantifies alignment with dataset labels and model predictions. We apply NLPositionality to existing datasets and models for two tasks -- social acceptability and hate speech detection. To date, we have collected 16,299 annotations in over a year for 600 instances from 1,096 annotators across 87 countries. We find that datasets and models align predominantly with Western, White, college-educated, and younger populations. Additionally, certain groups, such as non-binary people and non-native English speakers, are further marginalized by datasets and models as they rank least in alignment across all tasks. Finally, we draw from prior literature to discuss how researchers can examine their own positionality and that of their datasets and models, opening the door for more inclusive NLP systems.
Understanding the Usability of AI Programming Assistants
Mar 30, 2023



The software engineering community recently has witnessed widespread deployment of AI programming assistants, such as GitHub Copilot. However, in practice, developers do not accept AI programming assistants' initial suggestions at a high frequency. This leaves a number of open questions related to the usability of these tools. To understand developers' practices while using these tools and the important usability challenges they face, we administered a survey to a large population of developers and received responses from a diverse set of 410 developers. Through a mix of qualitative and quantitative analyses, we found that developers are most motivated to use AI programming assistants because they help developers reduce key-strokes, finish programming tasks quickly, and recall syntax, but resonate less with using them to help brainstorm potential solutions. We also found the most important reasons why developers do not use these tools are because these tools do not output code that addresses certain functional or non-functional requirements and because developers have trouble controlling the tool to generate the desired output. Our findings have implications for both creators and users of AI programming assistants, such as designing minimal cognitive effort interactions with these tools to reduce distractions for users while they are programming.