 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan GPT-4 Replicate Empirical Software Engineering Research?
Paper and Code
Oct 03, 2023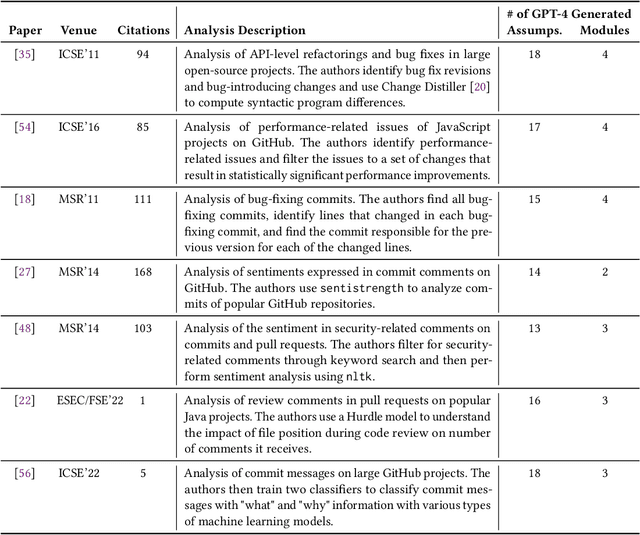
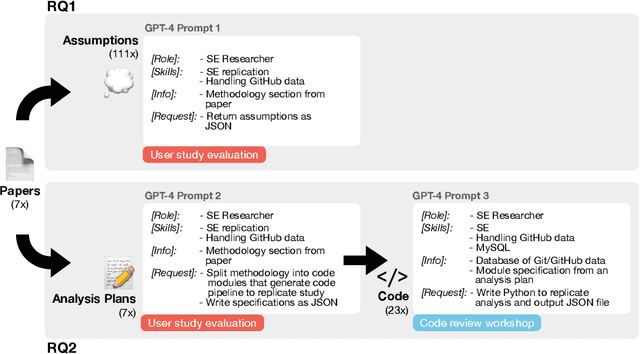

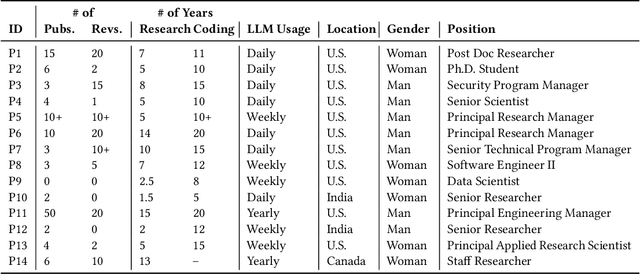
Empirical software engineering research on production systems has brought forth a better understanding of the software engineering process for practitioners and researchers alike. However, only a small subset of production systems is studied, limiting the impact of this research. While software engineering practitioners benefit from replicating research on their own data, this poses its own set of challenges, since performing replications requires a deep understanding of research methodologies and subtle nuances in software engineering data. Given that large language models (LLMs), such as GPT-4, show promise in tackling both software engineering- and science-related tasks, these models could help democratize empirical software engineering research. In this paper, we examine LLMs' abilities to perform replications of empirical software engineering research on new data. We specifically study their ability to surface assumptions made in empirical software engineering research methodologies, as well as their ability to plan and generate code for analysis pipelines on seven empirical software engineering papers. We perform a user study with 14 participants with software engineering research expertise, who evaluate GPT-4-generated assumptions and analysis plans (i.e., a list of module specifications) from the papers. We find that GPT-4 is able to surface correct assumptions, but struggle to generate ones that reflect common knowledge about software engineering data. In a manual analysis of the generated code, we find that the GPT-4-generated code contains the correct high-level logic, given a subset of the methodology. However, the code contains many small implementation-level errors, reflecting a lack of software engineering knowledge. Our findings have implications for leveraging LLMs for software engineering research as well as practitioner data scientists in software teams.