 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving FIM Code Completions via Context & Curriculum Based Learning
Dec 21, 2024



Fill-in-the-Middle (FIM) models play a vital role in code completion tasks, leveraging both prefix and suffix context to provide more accurate and contextually relevant suggestions. This paper presents approaches to improve FIM code completion while addressing the challenge of maintaining low latency for real-time coding assistance. We enhance FIM code completion by incorporating context and curriculum examples in the training process. We identify patterns where completion suggestions fail more frequently, revealing complexities that smaller language models struggle with. To address these challenges, we develop a curriculum dataset by extracting hard-to-complete patterns from code repositories and generate context examples using semantic and static analysis tools (e.g. TSC compiler). We fine-tune various sized models, including StarCoder and DeepSeek, on this enhanced dataset. Our evaluation encompasses three key dimensions: the Santa Coder FIM task, the Amazon CCEval benchmark, and a new Multi-Line Infilling evaluation benchmark derived from SWE-bench. Comprehensive ablation studies across multiple model sizes reveal that while all fine-tuned models show improvements, the performance gains are more pronounced for smaller parameter models and incorporating difficult-to-complete examples, as part of curriculum learning, improves the code completion performance. This finding is particularly significant given the latency constraints of code completion tasks. While larger models like GPT and Claude perform well in multi-line completions but are prohibitively challenging to use given high latency, and our fine-tuned models achieve a balance between performance and latency. Finally, we validate our approach through online A/B testing, demonstrating tangible improvements in Completion Acceptance Rate (CAR) and Completion Persistence Rate (CPR), with zero latency impact.
Crafting Tomorrow: The Influence of Design Choices on Fresh Content in Social Media Recommendation
Oct 19, 2024The rise in popularity of social media platforms, has resulted in millions of new, content pieces being created every day. This surge in content creation underscores the need to pay attention to our design choices as they can greatly impact how long content remains relevant. In today's landscape where regularly recommending new content is crucial, particularly in the absence of detailed information, a variety of factors such as UI features, algorithms and system settings contribute to shaping the journey of content across the platform. While previous research has focused on how new content affects users' experiences, this study takes a different approach by analyzing these decisions considering the content itself. Through a series of carefully crafted experiments we explore how seemingly small decisions can influence the longevity of content, measured by metrics like Content Progression (CVP) and Content Survival (CSR). We also emphasize the importance of recognizing the stages that content goes through underscoring the need to tailor strategies for each stage as a one size fits all approach may not be effective. Additionally we argue for a departure from traditional experimental setups in the study of content lifecycles, to avoid potential misunderstandings while proposing advanced techniques, to achieve greater precision and accuracy in the evaluation process.
AI-assisted Coding with Cody: Lessons from Context Retrieval and Evaluation for Code Recommendations
Aug 09, 2024In this work, we discuss a recently popular type of recommender system: an LLM-based coding assistant. Connecting the task of providing code recommendations in multiple formats to traditional RecSys challenges, we outline several similarities and differences due to domain specifics. We emphasize the importance of providing relevant context to an LLM for this use case and discuss lessons learned from context enhancements & offline and online evaluation of such AI-assisted coding systems.
On Gradient Boosted Decision Trees and Neural Rankers: A Case-Study on Short-Video Recommendations at ShareChat
Dec 04, 2023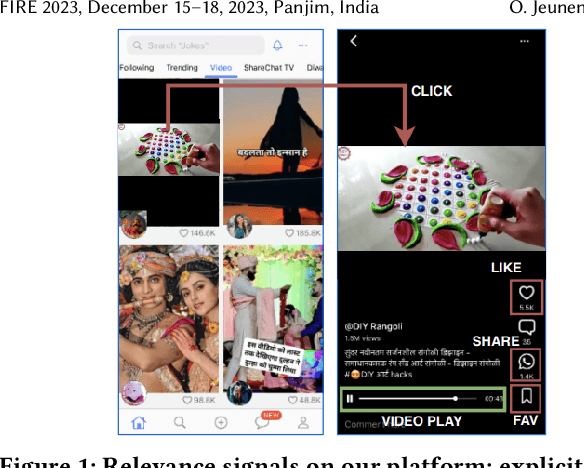
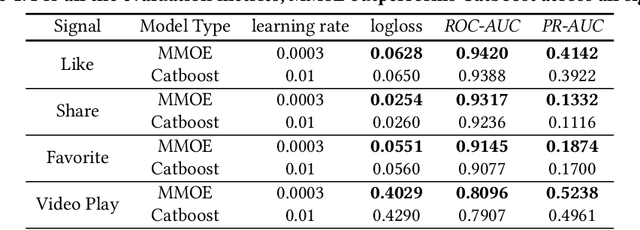
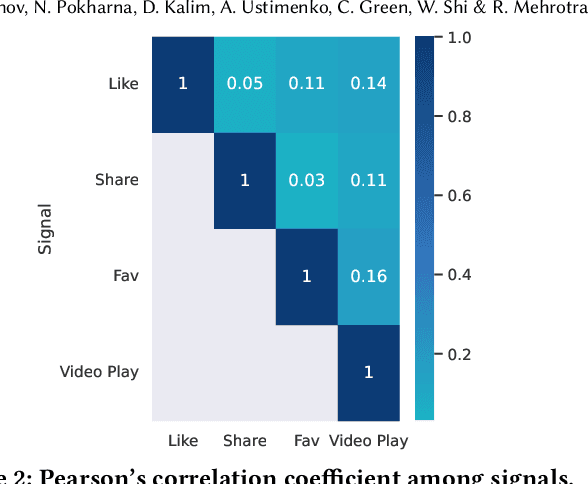
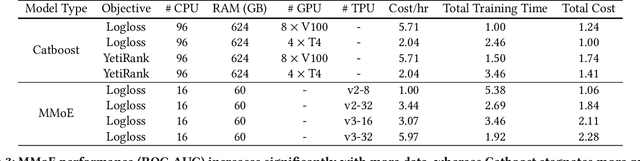
Practitioners who wish to build real-world applications that rely on ranking models, need to decide which modelling paradigm to follow. This is not an easy choice to make, as the research literature on this topic has been shifting in recent years. In particular, whilst Gradient Boosted Decision Trees (GBDTs) have reigned supreme for more than a decade, the flexibility of neural networks has allowed them to catch up, and recent works report accuracy metrics that are on par. Nevertheless, practical systems require considerations beyond mere accuracy metrics to decide on a modelling approach. This work describes our experiences in balancing some of the trade-offs that arise, presenting a case study on a short-video recommendation application. We highlight (1) neural networks' ability to handle large training data size, user- and item-embeddings allows for more accurate models than GBDTs in this setting, and (2) because GBDTs are less reliant on specialised hardware, they can provide an equally accurate model at a lower cost. We believe these findings are of relevance to researchers in both academia and industry, and hope they can inspire practitioners who need to make similar modelling choices in the future.
Ad-load Balancing via Off-policy Learning in a Content Marketplace
Sep 19, 2023



Ad-load balancing is a critical challenge in online advertising systems, particularly in the context of social media platforms, where the goal is to maximize user engagement and revenue while maintaining a satisfactory user experience. This requires the optimization of conflicting objectives, such as user satisfaction and ads revenue. Traditional approaches to ad-load balancing rely on static allocation policies, which fail to adapt to changing user preferences and contextual factors. In this paper, we present an approach that leverages off-policy learning and evaluation from logged bandit feedback. We start by presenting a motivating analysis of the ad-load balancing problem, highlighting the conflicting objectives between user satisfaction and ads revenue. We emphasize the nuances that arise due to user heterogeneity and the dependence on the user's position within a session. Based on this analysis, we define the problem as determining the optimal ad-load for a particular feed fetch. To tackle this problem, we propose an off-policy learning framework that leverages unbiased estimators such as Inverse Propensity Scoring (IPS) and Doubly Robust (DR) to learn and estimate the policy values using offline collected stochastic data. We present insights from online A/B experiments deployed at scale across over 80 million users generating over 200 million sessions, where we find statistically significant improvements in both user satisfaction metrics and ads revenue for the platform.
Task Preferences across Languages on Community Question Answering Platforms
Dec 18, 2022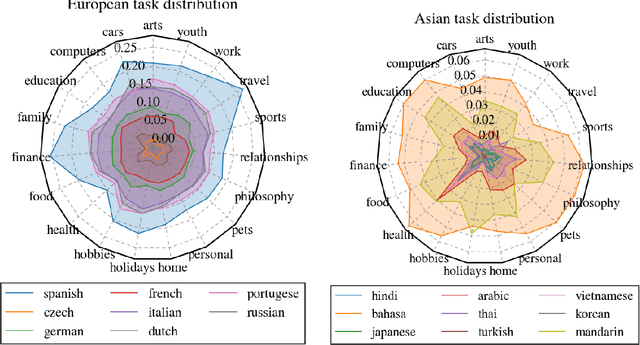
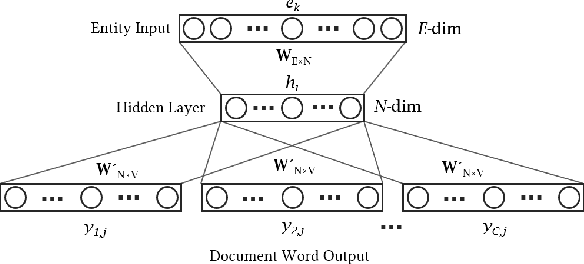
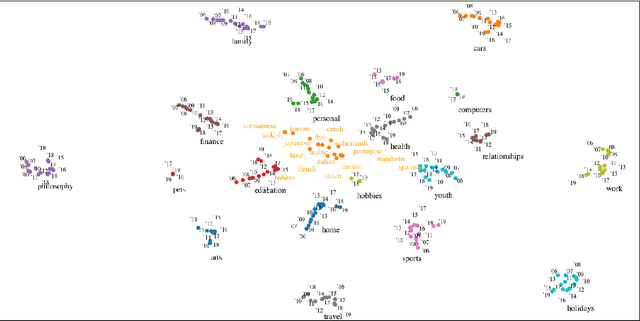
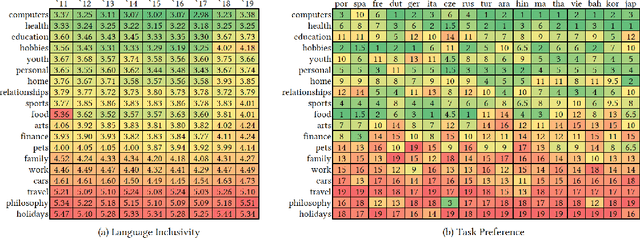
With the steady emergence of community question answering (CQA) platforms like Quora, StackExchange, and WikiHow, users now have an unprecedented access to information on various kind of queries and tasks. Moreover, the rapid proliferation and localization of these platforms spanning geographic and linguistic boundaries offer a unique opportunity to study the task requirements and preferences of users in different socio-linguistic groups. In this study, we implement an entity-embedding model trained on a large longitudinal dataset of multi-lingual and task-oriented question-answer pairs to uncover and quantify the (i) prevalence and distribution of various online tasks across linguistic communities, and (ii) emerging and receding trends in task popularity over time in these communities. Our results show that there exists substantial variance in task preference as well as popularity trends across linguistic communities on the platform. Findings from this study will help Q&A platforms better curate and personalize content for non-English users, while also offering valuable insights to businesses looking to target non-English speaking communities online.
Disentangling Causal Effects from Sets of Interventions in the Presence of Unobserved Confounders
Oct 11, 2022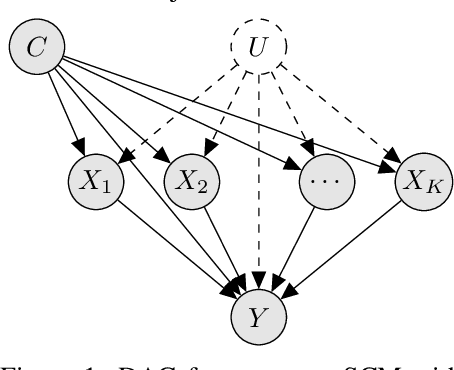
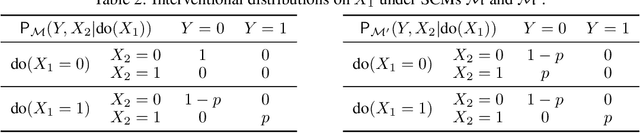
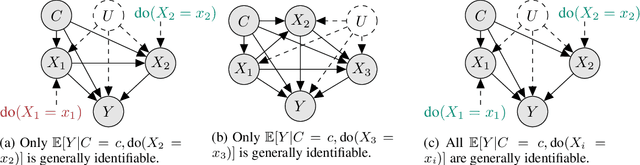
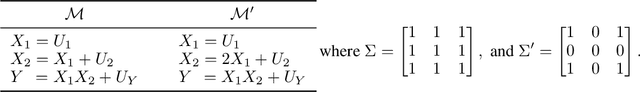
The ability to answer causal questions is crucial in many domains, as causal inference allows one to understand the impact of interventions. In many applications, only a single intervention is possible at a given time. However, in some important areas, multiple interventions are concurrently applied. Disentangling the effects of single interventions from jointly applied interventions is a challenging task -- especially as simultaneously applied interventions can interact. This problem is made harder still by unobserved confounders, which influence both treatments and outcome. We address this challenge by aiming to learn the effect of a single-intervention from both observational data and sets of interventions. We prove that this is not generally possible, but provide identification proofs demonstrating that it can be achieved under non-linear continuous structural causal models with additive, multivariate Gaussian noise -- even when unobserved confounders are present. Importantly, we show how to incorporate observed covariates and learn heterogeneous treatment effects. Based on the identifiability proofs, we provide an algorithm that learns the causal model parameters by pooling data from different regimes and jointly maximizing the combined likelihood. The effectiveness of our method is empirically demonstrated on both synthetic and real-world data.
Mostra: A Flexible Balancing Framework to Trade-off User, Artist and Platform Objectives for Music Sequencing
Apr 22, 2022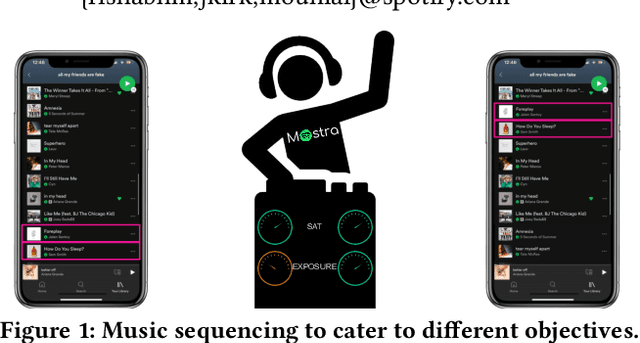
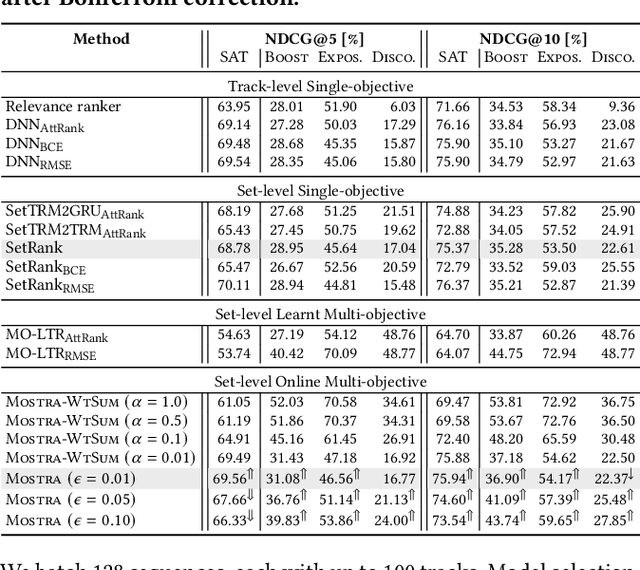

We consider the task of sequencing tracks on music streaming platforms where the goal is to maximise not only user satisfaction, but also artist- and platform-centric objectives, needed to ensure long-term health and sustainability of the platform. Grounding the work across four objectives: Sat, Discovery, Exposure and Boost, we highlight the need and the potential to trade-off performance across these objectives, and propose Mostra, a Set Transformer-based encoder-decoder architecture equipped with submodular multi-objective beam search decoding. The proposed model affords system designers the power to balance multiple goals, and dynamically control the impact on one objective to satisfy other objectives. Through extensive experiments on data from a large-scale music streaming platform, we present insights on the trade-offs that exist across different objectives, and demonstrate that the proposed framework leads to a superior, just-in-time balancing across the various metrics of interest.
Counterfactual Evaluation of Slate Recommendations with Sequential Reward Interactions
Aug 24, 2020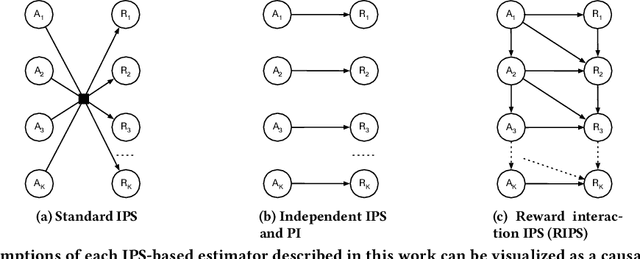
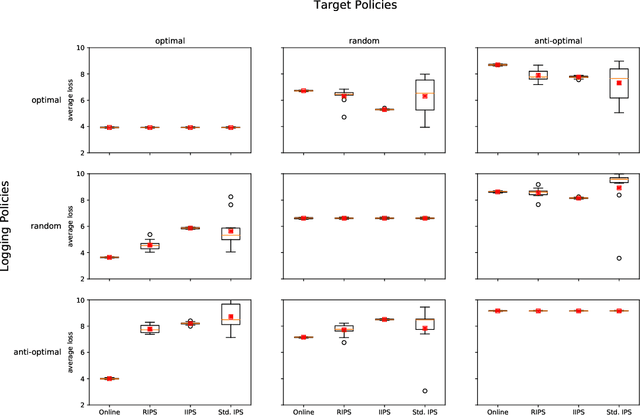
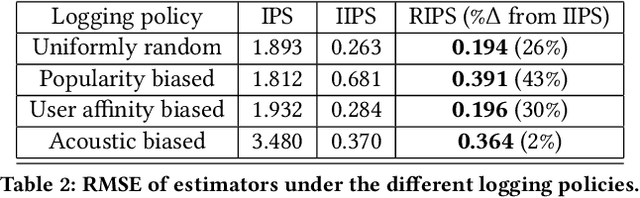
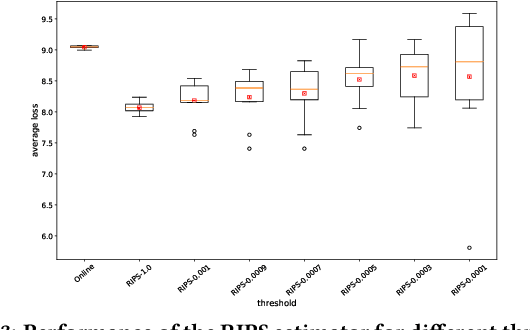
Users of music streaming, video streaming, news recommendation, and e-commerce services often engage with content in a sequential manner. Providing and evaluating good sequences of recommendations is therefore a central problem for these services. Prior reweighting-based counterfactual evaluation methods either suffer from high variance or make strong independence assumptions about rewards. We propose a new counterfactual estimator that allows for sequential interactions in the rewards with lower variance in an asymptotically unbiased manner. Our method uses graphical assumptions about the causal relationships of the slate to reweight the rewards in the logging policy in a way that approximates the expected sum of rewards under the target policy. Extensive experiments in simulation and on a live recommender system show that our approach outperforms existing methods in terms of bias and data efficiency for the sequential track recommendations problem.
Towards Task Understanding in Visual Settings
Nov 28, 2018
We consider the problem of understanding real world tasks depicted in visual images. While most existing image captioning methods excel in producing natural language descriptions of visual scenes involving human tasks, there is often the need for an understanding of the exact task being undertaken rather than a literal description of the scene. We leverage insights from real world task understanding systems, and propose a framework composed of convolutional neural networks, and an external hierarchical task ontology to produce task descriptions from input images. Detailed experiments highlight the efficacy of the extracted descriptions, which could potentially find their way in many applications, including image alt text generation.