 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Reduction for Heavy-Tailed Monetization Metrics in Ranking Experiments via Post-Stratification
Jun 02, 2026Online evaluation of ranking and retrieval systems often relies on downstream monetization metrics such as app revenue or creator earnings. These metrics are typically heavy-tailed, with a small fraction of users dominating both mean and variance, leading to low statistical power and unreliable conclusions in A/B experiments -- especially under limited traffic. We present a practical framework for variance reduction in online experiments by combining post-stratification with CUPED. Our approach leverages pre-experiment covariates to improve the sensitivity of monetization experiments without requiring additional traffic. Deployed at ShareChat across ranking-driven monetization experiments, the method substantially reduces variance and improves decision stability, achieving equivalent statistical confidence with ~45\% less traffic than standard metrics. We further discuss practical design choices, guardrails, and limitations, providing guidance on when post-stratification is appropriate for real-world information retrieval and Recommendation systems.
Powerful A/B-Testing Metrics and Where to Find Them
Jul 30, 2024Online controlled experiments, colloquially known as A/B-tests, are the bread and butter of real-world recommender system evaluation. Typically, end-users are randomly assigned some system variant, and a plethora of metrics are then tracked, collected, and aggregated throughout the experiment. A North Star metric (e.g. long-term growth or revenue) is used to assess which system variant should be deemed superior. As a result, most collected metrics are supporting in nature, and serve to either (i) provide an understanding of how the experiment impacts user experience, or (ii) allow for confident decision-making when the North Star metric moves insignificantly (i.e. a false negative or type-II error). The latter is not straightforward: suppose a treatment variant leads to fewer but longer sessions, with more views but fewer engagements; should this be considered a positive or negative outcome? The question then becomes: how do we assess a supporting metric's utility when it comes to decision-making using A/B-testing? Online platforms typically run dozens of experiments at any given time. This provides a wealth of information about interventions and treatment effects that can be used to evaluate metrics' utility for online evaluation. We propose to collect this information and leverage it to quantify type-I, type-II, and type-III errors for the metrics of interest, alongside a distribution of measurements of their statistical power (e.g. $z$-scores and $p$-values). We present results and insights from building this pipeline at scale for two large-scale short-video platforms: ShareChat and Moj; leveraging hundreds of past experiments to find online metrics with high statistical power.
Variance Reduction in Ratio Metrics for Efficient Online Experiments
Jan 08, 2024
Online controlled experiments, such as A/B-tests, are commonly used by modern tech companies to enable continuous system improvements. Despite their paramount importance, A/B-tests are expensive: by their very definition, a percentage of traffic is assigned an inferior system variant. To ensure statistical significance on top-level metrics, online experiments typically run for several weeks. Even then, a considerable amount of experiments will lead to inconclusive results (i.e. false negatives, or type-II error). The main culprit for this inefficiency is the variance of the online metrics. Variance reduction techniques have been proposed in the literature, but their direct applicability to commonly used ratio metrics (e.g. click-through rate or user retention) is limited. In this work, we successfully apply variance reduction techniques to ratio metrics on a large-scale short-video platform: ShareChat. Our empirical results show that we can either improve A/B-test confidence in 77% of cases, or can retain the same level of confidence with 30% fewer data points. Importantly, we show that the common approach of including as many covariates as possible in regression is counter-productive, highlighting that control variates based on Gradient-Boosted Decision Tree predictors are most effective. We discuss the practicalities of implementing these methods at scale and showcase the cost reduction they beget.
On Gradient Boosted Decision Trees and Neural Rankers: A Case-Study on Short-Video Recommendations at ShareChat
Dec 04, 2023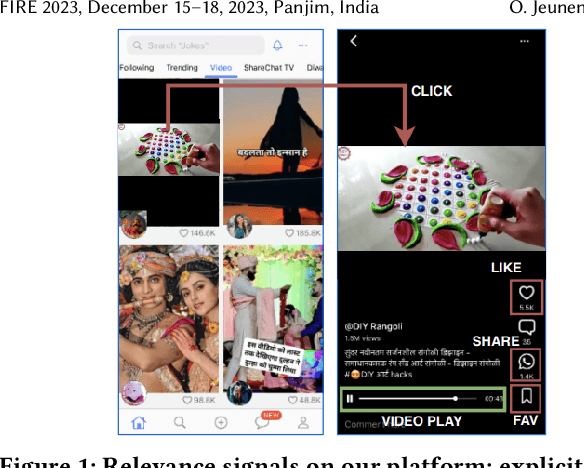
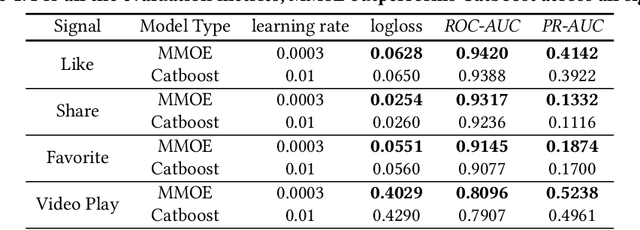
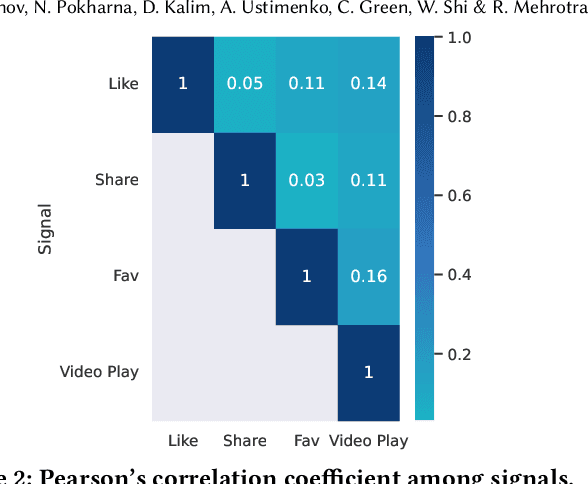
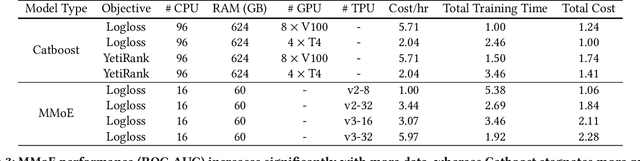
Practitioners who wish to build real-world applications that rely on ranking models, need to decide which modelling paradigm to follow. This is not an easy choice to make, as the research literature on this topic has been shifting in recent years. In particular, whilst Gradient Boosted Decision Trees (GBDTs) have reigned supreme for more than a decade, the flexibility of neural networks has allowed them to catch up, and recent works report accuracy metrics that are on par. Nevertheless, practical systems require considerations beyond mere accuracy metrics to decide on a modelling approach. This work describes our experiences in balancing some of the trade-offs that arise, presenting a case study on a short-video recommendation application. We highlight (1) neural networks' ability to handle large training data size, user- and item-embeddings allows for more accurate models than GBDTs in this setting, and (2) because GBDTs are less reliant on specialised hardware, they can provide an equally accurate model at a lower cost. We believe these findings are of relevance to researchers in both academia and industry, and hope they can inspire practitioners who need to make similar modelling choices in the future.