 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerful A/B-Testing Metrics and Where to Find Them
Jul 30, 2024Online controlled experiments, colloquially known as A/B-tests, are the bread and butter of real-world recommender system evaluation. Typically, end-users are randomly assigned some system variant, and a plethora of metrics are then tracked, collected, and aggregated throughout the experiment. A North Star metric (e.g. long-term growth or revenue) is used to assess which system variant should be deemed superior. As a result, most collected metrics are supporting in nature, and serve to either (i) provide an understanding of how the experiment impacts user experience, or (ii) allow for confident decision-making when the North Star metric moves insignificantly (i.e. a false negative or type-II error). The latter is not straightforward: suppose a treatment variant leads to fewer but longer sessions, with more views but fewer engagements; should this be considered a positive or negative outcome? The question then becomes: how do we assess a supporting metric's utility when it comes to decision-making using A/B-testing? Online platforms typically run dozens of experiments at any given time. This provides a wealth of information about interventions and treatment effects that can be used to evaluate metrics' utility for online evaluation. We propose to collect this information and leverage it to quantify type-I, type-II, and type-III errors for the metrics of interest, alongside a distribution of measurements of their statistical power (e.g. $z$-scores and $p$-values). We present results and insights from building this pipeline at scale for two large-scale short-video platforms: ShareChat and Moj; leveraging hundreds of past experiments to find online metrics with high statistical power.
$Δ\text{-}{\rm OPE}$: Off-Policy Estimation with Pairs of Policies
May 16, 2024The off-policy paradigm casts recommendation as a counterfactual decision-making task, allowing practitioners to unbiasedly estimate online metrics using offline data. This leads to effective evaluation metrics, as well as learning procedures that directly optimise online success. Nevertheless, the high variance that comes with unbiasedness is typically the crux that complicates practical applications. An important insight is that the difference between policy values can often be estimated with significantly reduced variance, if said policies have positive covariance. This allows us to formulate a pairwise off-policy estimation task: $\Delta\text{-}{\rm OPE}$. $\Delta\text{-}{\rm OPE}$ subsumes the common use-case of estimating improvements of a learnt policy over a production policy, using data collected by a stochastic logging policy. We introduce $\Delta\text{-}{\rm OPE}$ methods based on the widely used Inverse Propensity Scoring estimator and its extensions. Moreover, we characterise a variance-optimal additive control variate that further enhances efficiency. Simulated, offline, and online experiments show that our methods significantly improve performance for both evaluation and learning tasks.
Multi-Objective Recommendation via Multivariate Policy Learning
May 03, 2024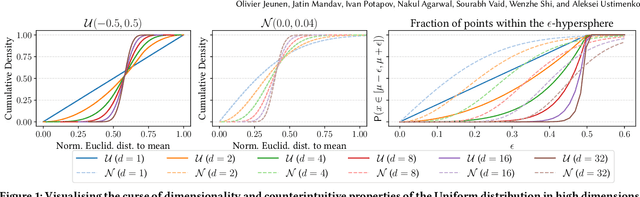

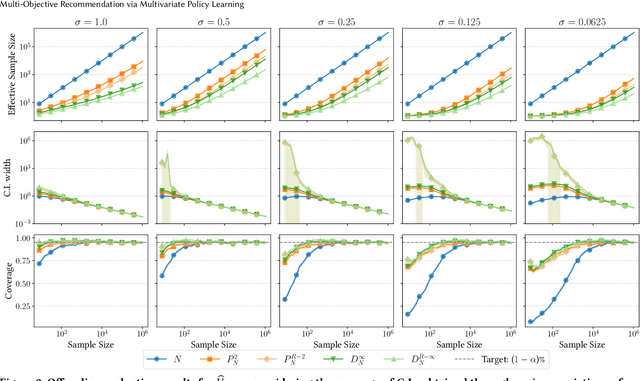
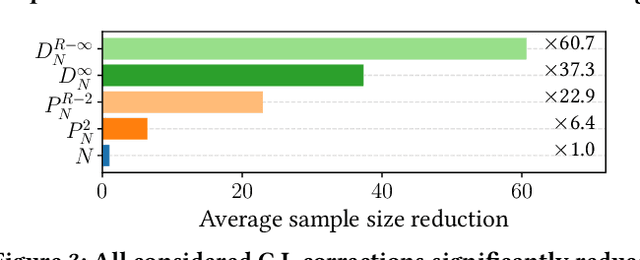
Real-world recommender systems often need to balance multiple objectives when deciding which recommendations to present to users. These include behavioural signals (e.g. clicks, shares, dwell time), as well as broader objectives (e.g. diversity, fairness). Scalarisation methods are commonly used to handle this balancing task, where a weighted average of per-objective reward signals determines the final score used for ranking. Naturally, how these weights are computed exactly, is key to success for any online platform. We frame this as a decision-making task, where the scalarisation weights are actions taken to maximise an overall North Star reward (e.g. long-term user retention or growth). We extend existing policy learning methods to the continuous multivariate action domain, proposing to maximise a pessimistic lower bound on the North Star reward that the learnt policy will yield. Typical lower bounds based on normal approximations suffer from insufficient coverage, and we propose an efficient and effective policy-dependent correction for this. We provide guidance to design stochastic data collection policies, as well as highly sensitive reward signals. Empirical observations from simulations, offline and online experiments highlight the efficacy of our deployed approach.
Learning Metrics that Maximise Power for Accelerated A/B-Tests
Feb 06, 2024Online controlled experiments are a crucial tool to allow for confident decision-making in technology companies. A North Star metric is defined (such as long-term revenue or user retention), and system variants that statistically significantly improve on this metric in an A/B-test can be considered superior. North Star metrics are typically delayed and insensitive. As a result, the cost of experimentation is high: experiments need to run for a long time, and even then, type-II errors (i.e. false negatives) are prevalent. We propose to tackle this by learning metrics from short-term signals that directly maximise the statistical power they harness with respect to the North Star. We show that existing approaches are prone to overfitting, in that higher average metric sensitivity does not imply improved type-II errors, and propose to instead minimise the $p$-values a metric would have produced on a log of past experiments. We collect such datasets from two social media applications with over 160 million Monthly Active Users each, totalling over 153 A/B-pairs. Empirical results show that we are able to increase statistical power by up to 78% when using our learnt metrics stand-alone, and by up to 210% when used in tandem with the North Star. Alternatively, we can obtain constant statistical power at a sample size that is down to 12% of what the North Star requires, significantly reducing the cost of experimentation.
Variance Reduction in Ratio Metrics for Efficient Online Experiments
Jan 08, 2024
Online controlled experiments, such as A/B-tests, are commonly used by modern tech companies to enable continuous system improvements. Despite their paramount importance, A/B-tests are expensive: by their very definition, a percentage of traffic is assigned an inferior system variant. To ensure statistical significance on top-level metrics, online experiments typically run for several weeks. Even then, a considerable amount of experiments will lead to inconclusive results (i.e. false negatives, or type-II error). The main culprit for this inefficiency is the variance of the online metrics. Variance reduction techniques have been proposed in the literature, but their direct applicability to commonly used ratio metrics (e.g. click-through rate or user retention) is limited. In this work, we successfully apply variance reduction techniques to ratio metrics on a large-scale short-video platform: ShareChat. Our empirical results show that we can either improve A/B-test confidence in 77% of cases, or can retain the same level of confidence with 30% fewer data points. Importantly, we show that the common approach of including as many covariates as possible in regression is counter-productive, highlighting that control variates based on Gradient-Boosted Decision Tree predictors are most effective. We discuss the practicalities of implementing these methods at scale and showcase the cost reduction they beget.
Learning-to-Rank with Nested Feedback
Jan 08, 2024Many platforms on the web present ranked lists of content to users, typically optimized for engagement-, satisfaction- or retention- driven metrics. Advances in the Learning-to-Rank (LTR) research literature have enabled rapid growth in this application area. Several popular interfaces now include nested lists, where users can enter a 2nd-level feed via any given 1st-level item. Naturally, this has implications for evaluation metrics, objective functions, and the ranking policies we wish to learn. We propose a theoretically grounded method to incorporate 2nd-level feedback into any 1st-level ranking model. Online experiments on a large-scale recommendation system confirm our theoretical findings.
On Gradient Boosted Decision Trees and Neural Rankers: A Case-Study on Short-Video Recommendations at ShareChat
Dec 04, 2023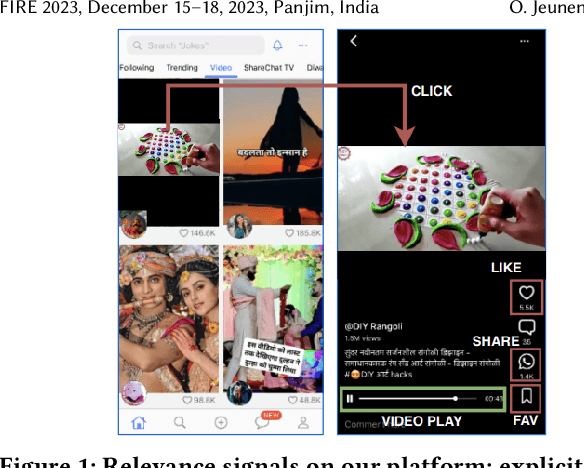
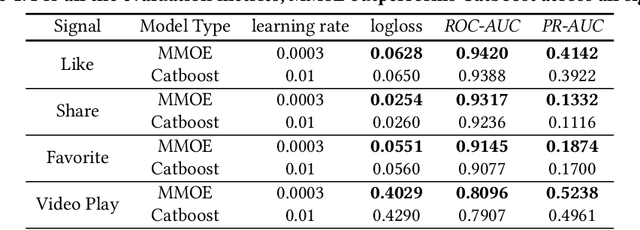
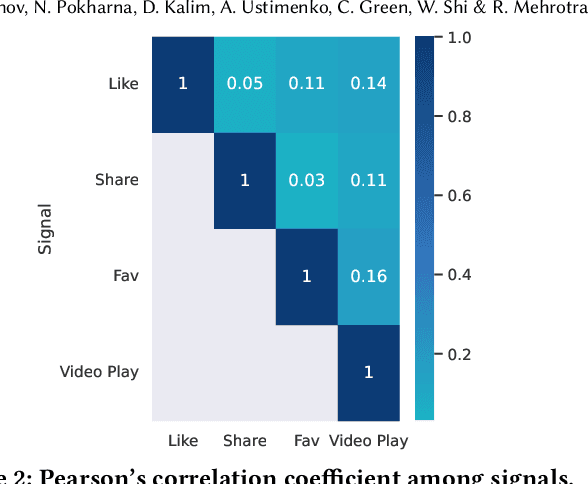
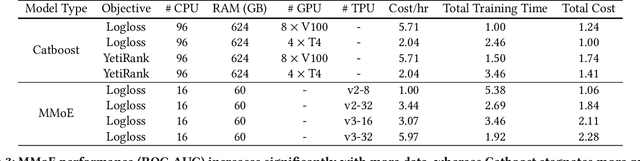
Practitioners who wish to build real-world applications that rely on ranking models, need to decide which modelling paradigm to follow. This is not an easy choice to make, as the research literature on this topic has been shifting in recent years. In particular, whilst Gradient Boosted Decision Trees (GBDTs) have reigned supreme for more than a decade, the flexibility of neural networks has allowed them to catch up, and recent works report accuracy metrics that are on par. Nevertheless, practical systems require considerations beyond mere accuracy metrics to decide on a modelling approach. This work describes our experiences in balancing some of the trade-offs that arise, presenting a case study on a short-video recommendation application. We highlight (1) neural networks' ability to handle large training data size, user- and item-embeddings allows for more accurate models than GBDTs in this setting, and (2) because GBDTs are less reliant on specialised hardware, they can provide an equally accurate model at a lower cost. We believe these findings are of relevance to researchers in both academia and industry, and hope they can inspire practitioners who need to make similar modelling choices in the future.
Ito Diffusion Approximation of Universal Ito Chains for Sampling, Optimization and Boosting
Oct 09, 2023This work considers a rather general and broad class of Markov chains, Ito chains that look like Euler-Maryama discretization of some Stochastic Differential Equation. The chain we study is a unified framework for theoretical analysis. It comes with almost arbitrary isotropic and state-dependent noise instead of normal and state-independent one, as in most related papers. Moreover, our chain's drift and diffusion coefficient can be inexact to cover a wide range of applications such as Stochastic Gradient Langevin Dynamics, sampling, Stochastic Gradient Descent, or Stochastic Gradient Boosting. We prove an upper bound for $W_{2}$-distance between laws of the Ito chain and the corresponding Stochastic Differential Equation. These results improve or cover most of the known estimates. Moreover, for some particular cases, our analysis is the first.
On Discounted Cumulative Gain as an Offline Evaluation Metric for Top-$n$ Recommendation
Jul 27, 2023



Approaches to recommendation are typically evaluated in one of two ways: (1) via a (simulated) online experiment, often seen as the gold standard, or (2) via some offline evaluation procedure, where the goal is to approximate the outcome of an online experiment. Several offline evaluation metrics have been adopted in the literature, inspired by ranking metrics prevalent in the field of Information Retrieval. (Normalised) Discounted Cumulative Gain (nDCG) is one such metric that has seen widespread adoption in empirical studies, and higher (n)DCG values have been used to present new methods as the state-of-the-art in top-$n$ recommendation for many years. Our work takes a critical look at this approach, and investigates when we can expect such metrics to approximate the gold standard outcome of an online experiment. We formally present the assumptions that are necessary to consider DCG an unbiased estimator of online reward and provide a derivation for this metric from first principles, highlighting where we deviate from its traditional uses in IR. Importantly, we show that normalising the metric renders it inconsistent, in that even when DCG is unbiased, ranking competing methods by their normalised DCG can invert their relative order. Through a correlation analysis between off- and on-line experiments conducted on a large-scale recommendation platform, we show that our unbiased DCG estimates strongly correlate with online reward, even when some of the metric's inherent assumptions are violated. This statement no longer holds for its normalised variant, suggesting that nDCG's practical utility may be limited.
Deep Stochastic Mechanics
May 31, 2023This paper introduces a novel deep-learning-based approach for numerical simulation of a time-evolving Schr\"odinger equation inspired by stochastic mechanics and generative diffusion models. Unlike existing approaches, which exhibit computational complexity that scales exponentially in the problem dimension, our method allows us to adapt to the latent low-dimensional structure of the wave function by sampling from the Markovian diffusion. Depending on the latent dimension, our method may have far lower computational complexity in higher dimensions. Moreover, we propose novel equations for stochastic quantum mechanics, resulting in linear computational complexity with respect to the number of dimensions. Numerical simulations verify our theoretical findings and show a significant advantage of our method compared to other deep-learning-based approaches used for quantum mechanics.